
Essentials of Linguistics by Catherine Anderson is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License, except where otherwise noted.
Essentials of Linguistics by Catherine Anderson is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License, except where otherwise noted.
This Open Educational Resource (OER) brings together Open Access content from around the web and enhances it with dynamic video lectures about the core areas of theoretical linguistics (phonetics, phonology, morphology, syntax, and semantics), supplemented with discussion of psycholinguistic and neurolinguistic findings. Essentials of Linguistics is suitable for any beginning learner of linguistics but is primarily aimed at the Canadian learner, focusing on Canadian English for learning phonetic transcription, and discussing the status of Indigenous languages in Canada. Drawing on best practices for instructional design, Essentials of Linguistics is suitable for blended classes, traditional lecture classes, and for self-directed learning. No prior knowledge of linguistics is required.
Your instructor might assign some parts or all of this OER to support your learning, or you may choose to use it to teach yourself introductory linguistics. You might decide to read the textbook straight through and watch the videos in order, or you might select specific topics that are of particular interest to you. However you use the OER, we recommend that you begin with Chapter 1, which provides fundamentals for the rest of the topics. You will also find that if you complete the quizzes and attempt the exercises, you’ll achieve a better understanding of the material in each chapter.
You may use Essentials of Linguistics as a stand-alone textbook or as a supplement to a traditional textbook. The OER is suitable for an in-person, blended or fully online course. Because this is an entirely open resource, its content is licensed under a Creative Common Attribution 4.0. International License; therefore, you are free to redistribute, revise, remix, and retain any of the parts of the eTextbook.

Photo credit: Colin Czerneda, 2017
Catherine Anderson is a Teaching Professor in the Department of Linguistics & Languages at McMaster University. She earned a Ph.D. in Linguistics from Northwestern University in Evanston, Illinois. Dr. Anderson conducts research on undergraduate learning and curriculum in linguistics. She lives in Hamilton, Ontario, with her partner and their school-aged twins.
This project was funded by a grant from the Open Textbook Initiative of eCampusOntario for adoption and adaptation of existing resources and supported by McMaster University’s Paul R. MacPherson Institute for Leadership, Innovation and Excellence in Teaching. Anastassiya Yudintseva was the Instructional Designer for the project, and Kendrick Potvin was the Digital Media Specialist. Zafar Syed also provided oversight.
Most of the material included in this ebook originated in Dr. Anderson’s Introduction to Linguistics courses, the blended design of which was supported by McMaster University’s Humanities Media and Computing, especially Katrina Espanol-Miller, with financial support from the Faculty of Humanities and the Department of Linguistics. This ebook also incorporates material adapted from How Language Works by Michael Gasser, under a GNU Free Documentation License.
Special thanks go to David Kanatawakhon-Maracle for his contributions to Chapter 11. Captions for the videos were the work of a capable team of students from Dr. Anderson’s Ling 2SY3 class: Maryam Ahmed, Brianna Borean, Carina Chan, Elena Davis, Meliha Horzum, Emiliya Krichevskaya, Thea Robinson, Connor Savery, Saloni Tattar, and Kathryn Williams.
In this chapter, we begin to consider the ways that linguists think about language, especially the idea that linguists strive to make systematic observations of human language behaviour. Linguists don’t spend time prescribing how people should or shouldn’t use their language!
One of the challenges of observing how humans use language is that a lot of what we do with language happens in our minds. Of course, it’s relatively simple to observe the words that we speak or write, but it’s much harder to observe the processes that unfold in someone’s mind when they’re listening to someone speaking, understanding them, and thinking up a reply. Part of learning to do linguistics is learning some of the techniques linguists have for drawing conclusions about these mental processes.
In Chapter 1 we also discuss the fundamental attributes of human language and discover the five core components that make up the grammar of every human language.
When you’ve completed this chapter, you will be able to:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=22
1. What does it mean to say that Linguistics is a science?
2. Each of the following sentences represents something someone might say about language. Which of them illustrates a descriptive view of language?
3. Which of the following kinds of data would a linguist be likely to observe?
Linguistics is one of those subjects that not many people have heard of, so you might well be wondering exactly what it is.
The simplest definition of Linguistics is that it’s the science of language.
This is a simple definition but it contains some very important words. First, when we say that linguistics is a science, that doesn’t mean you need a lab coat and safety goggles to do linguistics. Instead, what it means is that the way we ask questions to learn about language uses a scientific approach.
The scientific way of thinking about language involves making systematic, empirical observations. There’s another important word: empirical means that we observe data to find the evidence for our theories.
All scientists make empirical observations: botanists observe how plants grow and reproduce. Chemists observe how substances interact with other. Linguists observe how people use their language.
A crucial thing to keep in mind is that the observations we make about language use are NOT value judgments. Lots of people in the world — like your high school English teacher, various newspaper columnists, maybe your grandparents, and maybe even some of your friends — make judgments about how people use language. But linguists don’t.
A short-hand way of saying this is that linguists have a descriptive approach to language, not a prescriptive approach.
We describe what people do with their language, but we don’t prescribe how they should or shouldn’t do it.
This descriptive approach is consistent with a scientific way of thinking. Think about an entomologist who studies beetles. Imagine that scientist observes that a species of beetle eats leaves. She’s not going to judge that the beetles are eating wrong, and tell them that they’d be more successful in life if only they eat the same thing as ants. No — she observes what the beetle eats and tries to figure out why: she develops a theory of why the beetle eats this plant and not that one.
In the same way, linguists observe what people say and how they say it, and come up with theories of why people say certain things or make certain sounds but not others.
In our simple definition of linguistics, there’s another important word we need to focus on: linguistics is the science of human language.
There are plenty of species that communicate with each other in an impressive variety of ways, but in linguistics, our job is to focus on the unique system that humans use.
It turns out that humans have some important differences to all other species that make our language unique.
First, what we call the articulatory system: our lungs, larynx & vocal folds, and the shape of our tongue, teeth, lips, nose, all enable us to produce speech. No other species can do this in the way we can, not even our closest genetic relatives the chimpanzees, bonobos, and orangutans.
Second, our auditory system is special: our ears are sensitive to exactly the frequencies that are most common in human speech. There are other species that have similar patterns of auditory sensitivity, but human newborns pay special attention to human speech, even more so than synthetic speech that is matched for acoustic characteristics.
And most important of all, our neural system is special: no other species has a brain as complex and densely connected as ours with so many connections dedicated to producing and understanding language.
Humans’ language ability is different from all other species’ communication systems, and linguistics is the science that studies this unique ability.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=24
1. Newspaper headlines occasionally have unexpectedly funny interpretations. One example is: Two cars were reported stolen by the police yesterday. Which part of your mental grammar leads to the possibility that the police could have done the stealing or the reporting in this headline?
2. Newfoundland English has some characteristic differences to standard Canadian English. The following sentences are grammatical in Newfoundland English: I eats toast for breakfast every day. You knows the answer to that question. What part of the mental grammar of Newfoundland English is different to Canadian English in these examples?
3. When speakers of Hawaiian pronounce the English phrase, “Merry Christmas”, it sounds like: mele kalikimaka. What part of the mental grammar of Hawaiian is responsible for how the English phrase gets pronounced?
We know now that Linguistics is the scientific study of human language. It’s also important to know that linguistics is one member of the broad field that is known as cognitive science.
The cognitive sciences are interested in what goes in the mind. And in linguistics, we’re specifically interested in how our language knowledge is represented and organized in the human mind.
Think about this: you and I both speak English. I’m speaking English right here on this video and you’re listening and understanding me. Right now I’ve got some idea in my mind that I want to express. I’m squeezing the air out of my lungs; I’m vibrating my vocal folds, and I’m manipulating parts of my mouth to produce sounds. Those sounds are captured by a microphone and now they’re playing on your computer. In response to the sound coming from your computer speaker or your headphones, your eardrums are vibrating and sending signals to your brain, with the result that the idea in your mind is something similar to the idea that was in my head when I made this video.
There must be something that your mind and my mind have in common to allow that to happen: some shared system that allows us to understand each other’s ideas when we speak. In linguistics, we call that system the mental grammar and our primary goal is to find out what that shared system is like.
All speakers of all languages have a mental grammar: the shared system that lets speakers of a language understand each other. In Essentials of Linguistics we devote most of our attention to the mental grammar of English, but we’ll also use our scientific tools and techniques to examine some parts of the grammars of other languages.
We’ll start by looking at sound systems: how speakers make particular sounds and how listeners hear these sounds. If you’ve ever tried to learn a second language you know that the sounds in the second language are not always the same as in your first language. Linguists call the study of speech sounds phonetics.
Then we’ll look at how the mental grammar of each language organizes sounds in the mind; this is called phonology.
We will examine the strategies that languages use to form meaningful words; this is called morphology.
Then we take a close look at the different ways that languages combine words to form phrases and sentences. The term for that is syntax.
We also look at how the meanings of words and sentences are organized in the mind, which linguists call semantics.
These five things are the core pieces of the mental grammar of any language: they’re the things all speakers know about a language. All languages have phonetics, phonology, morphology, syntax and semantics in their grammars.
These five areas are also the core subfields of theoretical linguistics. Just as there are other kinds of language knowledge we have, there are other branches of the field of linguistics, and we’ll take a peek at some of those other branches along the way.
The foremost property of mental grammar is that it is generative: it allows each speaker to create new words and sentences that have never been spoken before. The mental grammar generates these new words and sentences according to systematic principles that every speaker knows unconsciously.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=26
1. What does it mean to say that mental grammar is generative?
2. The systematic principles of English phonology generate some word forms but not others. Which of the following words could be a possible word in English?
3. The systematic principles of English syntax generate some sentences but not others. Which of the following sentences is not possible in English?
Probably the most fundamental property of human language is creativity. When we say that human languages are creative, we don’t just mean that you can use them to write beautiful poems and great works of literature.
When we say that human language is creative, we mean a couple of different things:
First, every language can express any possible concept.
That notion might surprise you at first. I often see magazine articles or blog posts that talk about supposedly untranslatable words that exist in other languages but that don’t exist in English. A quick search online leads me to these gems:
Kummerspeck is the German word for excess weight gained from emotional overeating.
In Inuktitut, iktsuarpok is that feeling of anticipation when you’re waiting for someone to show up at your house and you keep going outside to see if they’re there yet.
And in Tagalog, gigil is the word for the urge to squeeze something that is irresistibly cute.
So if you believe that kind of article, it might seem like some concepts are restricted to certain languages. But think about it: Just because English doesn’t have one single word that means “the urge to squeeze something cute” doesn’t mean that English-speakers can’t understand the concept of wanting to squeeze something cute. As soon as I described it using the English phrase “the urge to squeeze something cute” you understood the concept! It just takes more than one word to express it! The same is true of every language: all of the world’s languages can express all concepts.
The other side of the creativity of language is even more interesting. Every language can generate an infinite number of possible new words and sentences.
Every language has a finite set of words in it. A language’s vocabulary might be quite large, but it’s still finite. And every language has a small and finite set of principles for combining those words.
But every language can use that finite vocabulary and that finite set of principles to generate an infinite number of sentences, new sentences every single day.
Likewise, every language has a finite set of sounds and a finite set of principles for combining those sounds. Every language can use those finite resources to generate an infinite number of possible new words in that language.
Because human languages are all capable of generating new words and generating new sentences, we say that human grammar is generative.
Remember that when we use the word “grammar” in linguistics, we’re talking not about the prescriptive rules that your Grade 6 teacher tried to make you follow, but about mental grammar, the things in our minds that all speakers of a language have in common that allow us to understand each other. Mental grammar is generative.
The final, and possibly the most important thing to know about the creativity of language is that it is governed by systematic principles. Every fluent speaker of a language uses systematic principles to combine sounds to form words and to combine words to form sentences. In Essentials of Linguistics, we’ll use the tools of systematic observation to discover what these systematic principles are.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=28
1. It’s important to study Latin because Latin is more logical than other languages.
2. Spending too much time texting will ruin your ability to write proper English.
3. The dictionary gives the only correct meaning and pronunciation for words.
Because everybody speaks a language, just about everybody has opinions about language. But there are lots of things that are commonly believed about language that just aren’t true.
You might have heard someone say that a given language has no grammar. I’ve heard people try to argue that Chinese has no grammar, that English has no grammar, that the languages spoken by Indigenous people who live in what is currently Canada have no grammar, even that Swiss German has no grammar.
When people say this, they might mean a few different things. Sometimes they just mean that there’s not much variation in the forms of words, which is true of Chinese, but the grammar of Chinese has lots of complexity in its sound system.
But sometimes people who argue that a language has no grammar are actually trying to claim that that language is inferior in some way.
The truth is that all languages have grammar. All languages have a sound system, a system for forming words, a way of organizing words into sentences, a systematic way of assigning meanings. Even languages that don’t have writing systems or dictionaries or published books of rules still have speakers who understand each other; that means they have a shared system, a shared mental grammar.
When we’re investigating mental grammar, it doesn’t matter whether a language has a prestigious literature or is spoken by powerful people. Using linguists’ techniques for making scientific observations about language, we can study the phonetics, phonology, morphology, syntax and semantics of any language.
Another opinion that you might have heard about language is that some languages are better than others. Maybe you’ve heard someone say, “Oh, I don’t speak real Italian, just a dialect,” implying that the dialect is not as good as so-called real Italian. Or maybe you’ve heard someone say that Québec French is just sloppy; it’s not as good as the French they speak in France. Or maybe you’ve heard someone say that nobody in Newfoundland can speak proper English, or nobody in Texas speaks proper English, or maybe even nobody in North America speaks proper English and the only good English is the Queen’s English that they speak in England.
The truth is that all languages are equally valid. Just as we said that all languages have grammar, it’s also the case that there’s no way to say that one grammar is better or worse than another grammar. Remember that linguistics takes a scientific approach to language, and scientists don’t rate or rank the things they study. Ichthyologists don’t rank fish to say which species is more correct at being a fish, and astronomers don’t argue over which galaxy is more posh. In the same way, linguists don’t assign a value to any language or variety or dialect.
It is the case, though, that plenty of people do attribute value to particular dialects or varieties, and sociolinguistic research tells us that there can be negative or positive social consequences for people who speak certain varieties. When people say that British English is better than American English, for example, they’re making a social judgment, based on politics, history, economics, or snobbery. But there is no linguistic basis for making that value judgment.
One of the common misconceptions about language arose when scholars first started doing linguistics. At first, they focused on the languages that they knew, which were mostly the languages that were spoken in Europe. The grammars of those languages had a lot in common because they all evolved from a common ancestor, which we now call Proto-Indo-European. When linguists started learning about the languages spoken in other parts of the world, they thought at first that these languages were so unfamiliar, so unusual, so weird, that they speculated that these languages had nothing at all in common with the languages of Europe.
Linguists have now studied enough languages to know that in spite of the many differences between languages, there are some universal properties that are common to all human languages. The field of linguistic typology studies the properties that languages have in common even across languages that they aren’t related to. Some of these universal properties are at the level of phonology, for example, all languages have consonants and vowels. Some of these universals are at the level of morphology and syntax. All languages make a distinction between nouns and verbs. In nearly all languages, the subject of a sentence comes before the verb and before the object of the sentence. We’ll discover more of these universals as we proceed through the chapters.
A very common belief that people have about language is something you might have heard from your grandparents or your teachers. Have you heard them say, “Kids these days are ruining English! They should learn to speak properly!” Or if you grew up speaking Mandarin, maybe you heard the same thing, “Those teenagers are ruining Mandarin! They should learn to speak properly!” For as long as there has been language, there have been people complaining that young people are ruining it, and trying to force them to speak in a more old-fashioned way. Some countries like France and Germany even have official institutes that make prescriptive rules about what words and sentence structures are allowed in the language and which ones aren’t allowed.
The truth is that every language changes over time. Languages are spoken by humans, and as humans grow and change, and as our society changes, our language changes along with it. Some language change is as simple as in the vocabulary of a language: we need to introduce new words to talk about new concepts and new inventions. For example, the verb google didn’t exist when I was an undergraduate student, but now googling is something I do every day. Language also changes in they we pronounce things and in the way we use words and form sentences. In a later chapter, we’ll talk about some of the things that are changing in Canadian English.
Another common belief about language is the idea that you can’t learn a language unless someone teaches you the rules, either in a language class or with a textbook or a software package. This might be partially true for learning a language as an adult: it might be hard to do it on your own without a teacher. But think about yourself as a kid. Whatever language you grew up speaking, whether it’s English or French or Mandarin or Arabic or Tamil or Serbian, you didn’t have to wait until kindergarten to start speaking. You learned the language from infancy by interacting with the people around you who spoke that language. Some of those people around you might have taught you particular words for things, but they probably weren’t teaching you, “make the [f] sound by putting your top teeth on your bottom lip” or “make sure you put the subject of the sentence before the verb”. And by the time you started school you were perfectly fluent in your language. In some parts of the world, people never go to school and never have any formal instruction, but they still speak their languages fluently.
That’s because almost everything we know about our language — our mental grammar — is unconscious knowledge that’s acquired implicitly as children. Much of your knowledge of your mental grammar is not accessible to your conscious awareness. This is kind of a strange idea: how can you know something if you’re not conscious of knowing it? Many things that we know are indeed conscious knowledge. For example, if I asked you, you could explain to me how to get to your house, or what the capital of Canada is, or what the difference is between a cow and a horse. But our mind also has lots of knowledge that is not fully conscious. You probably can’t explain very clearly how to control your muscles to climb stairs, or how to recognize the face of someone you know, or how to form complex sentences in your native language, and yet you can do all of these things easily and fluently, and unconsciously. A lot of our job when we study Linguistics is to make explicit the things that you already know implicitly. This is exactly what makes linguistics challenging at first, but it’s also what makes it fun!
Exercise 1. Generate a sentence of English that you have never, ever uttered or heard before. Have a friend do the same thing. Exchange sentences with your friend. Were you able to understand each other’s sentences? How could you understand them, even though you had never heard them before?
Exercise 2. Pretend you’re working for a start-up. Your company has developed a very cool new product, and they turn to you, the linguist, to come up with a name for this new product. It has to be a unique name that doesn’t already exist. What will you name your company’s cool new product?
Now, look at this list of product names generated by other students. Which of them are good product names and which aren’t? What makes something a good name?
| mentocular | swoodiei | torrix | baizan |
| jibberdab | keerild | euquinu | tuitionary |
| kzen | zirka | hbiufk | fluxon |
Exercise 3. Think of a word that has only recently entered English, so it’s not yet in mainstream dictionaries. Observe some examples of the word being used in context, either in your regular conversations or by searching online. Based on your observations of the word in context, write a dictionary definition of the word.
Exercise 4. Think about all the languages that you speak, or about a variety of language that you’ve heard spoken by someone you know. Make two scientific observations about that language or a variety. Your observations might be about the sounds of the language, about the words, about how the sentences are organized, or about how people use different elements of the language. Remember that scientific observations are descriptive, not prescriptive.
We’ve now seen that the field of linguistics approaches the study of language from a scientific point of view. As linguists, we seek to make systematic, descriptive observations about human language behaviour. From these empirical observations, linguists have learned that every speaker of every human language has a mental grammar. And the mental grammar of every language includes systematic principles for how sounds (or hand signs, in a signed language) are made, for how these sounds or signs are organized into words, for how words and smaller pieces of words are combined to form phrases and sentences, and for how we assign meaning to words and sentences. When we speak our language, we use our mental grammar to generate new phrases and sentences, and the people who listen to us use their mental grammar to understand us.
In this chapter, we learn how humans produce speech sounds and how linguists classify speech sounds. Sounds are classified according to how they’re produced and what they sound like. We also begin to learn a notation system for representing speech sounds, since the English writing system is not very accurate or consistent in how it represents sounds.
When you’ve completed this chapter, you will be able to:
Phonetics studies human speech. Speech is produced by bringing air from the lungs to the larynx (respiration), where the vocal folds may be held open to allow the air to pass through or may vibrate to make a sound (phonation). The airflow from the lungs is then shaped by the articulators in the mouth and nose (articulation).

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=37
1. What is the voicing of the last sound in the word soup?
2. What is the voicing of the last sound in the word life?
3. What is the voicing of the last sound in the word seem?
The field of phonetics studies the sounds of human speech. When we study speech sounds we can consider them from two angles. Acoustic phonetics, in addition to being part of linguistics, is also a branch of physics. It’s concerned with the physical, acoustic properties of the sound waves that we produce. We’ll talk some about the acoustics of speech sounds, but we’re primarily interested in articulatory phonetics, that is, how we humans use our bodies to produce speech sounds. Producing speech needs three mechanisms.
The first is a source of energy. Anything that makes a sound needs a source of energy. For human speech sounds, the air flowing from our lungs provides energy.
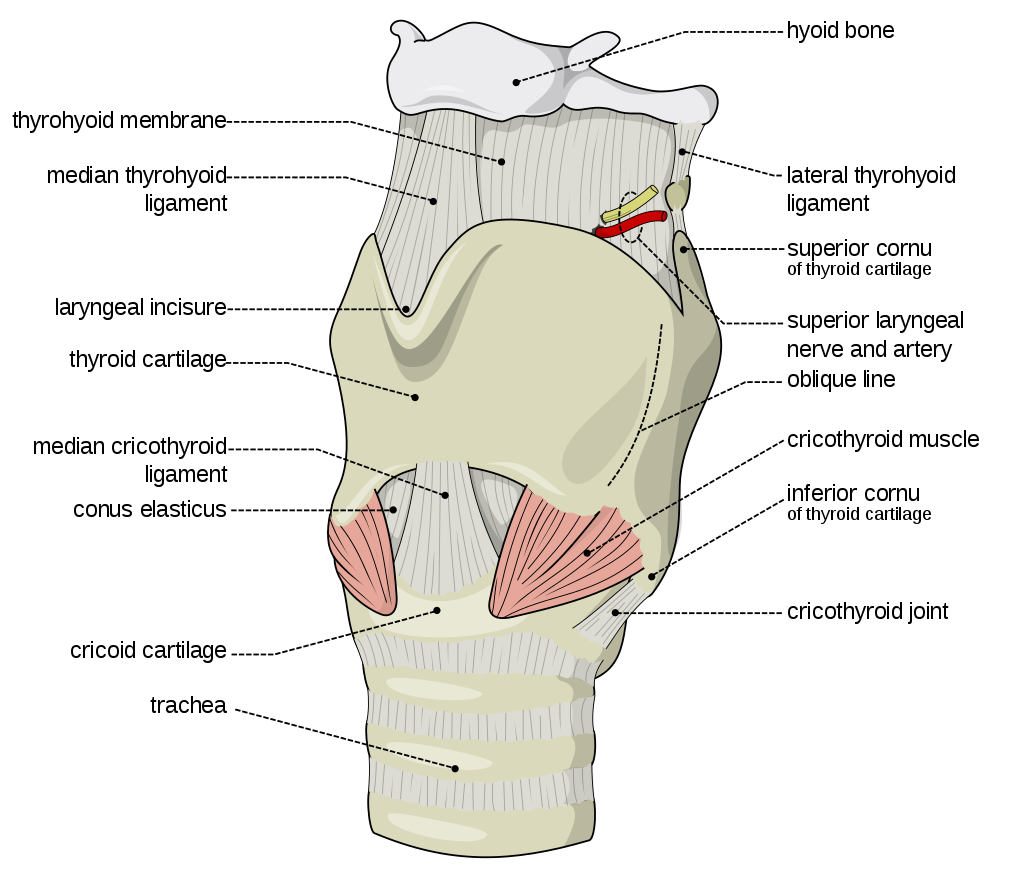
The second is a source of the sound: air flowing from the lungs arrives at the larynx. Put your hand on the front of your throat and gently feel the bony part under your skin. That’s the front of your larynx. It’s not actually made of bone; it’s cartilage and muscle. This picture shows what the larynx looks like from the front.
By Olek Remesz (wiki-pl: Orem, commons: Orem) [CC BY-SA 2.5-2.0-1.0 (https://creativecommons.org/licenses/by-sa/2.5-2.0-1.0)], via Wikimedia Commons
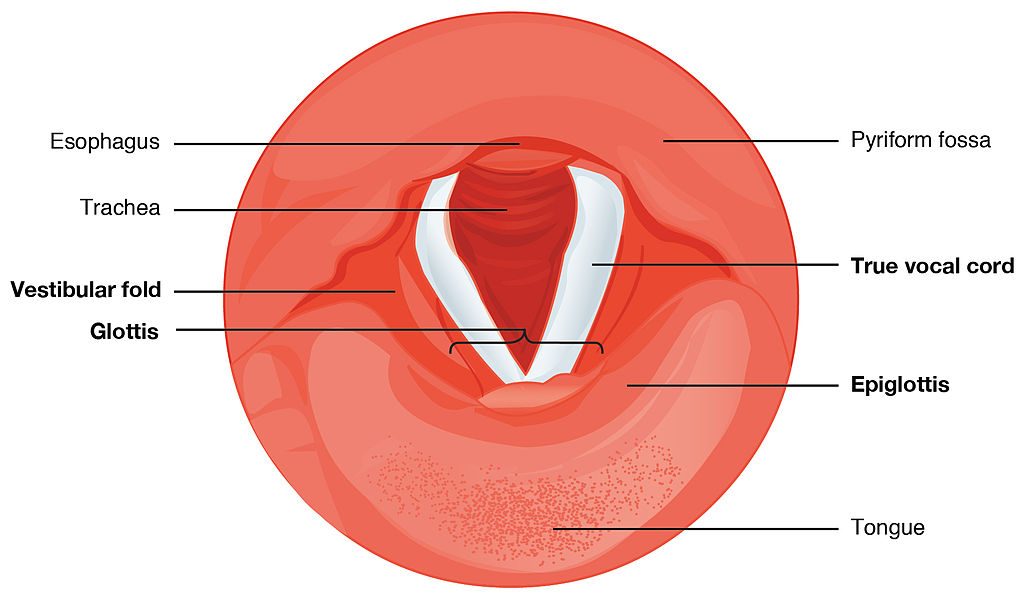
This next picture is a view down a person’s throat.
By OpenStax College [CC BY 3.0 (http://creativecommons.org/licenses/by/3.0)], via Wikimedia Commons
What you see here is that the opening of the larynx can be covered by two triangle-shaped pieces of skin. These are often called “vocal cords” but they’re not really like cords or strings. A better name for them is vocal folds.
The opening between the vocal folds is called the glottis.
We can control our vocal folds to make a sound. I want you to try this out so take a moment and close your door or make sure there’s no one around that you might disturb.
First I want you to say the word “uh-oh”. Now say it again, but stop half-way through, “Uh-”. When you do that, you’ve closed your vocal folds by bringing them together. This stops the air flowing through your vocal tract. That little silence in the middle of “uh-oh” is called a glottal stop because the air is stopped completely when the vocal folds close off the glottis.
Now I want you to open your mouth and breathe out quietly, “haaaaaaah”. When you do this, your vocal folds are open and the air is passing freely through the glottis.
Now breathe out again and say “aaah”, as if the doctor is looking down your throat. To make that “aaaah” sound, you’re holding your vocal folds close together and vibrating them rapidly.
When we speak, we make some sounds with vocal folds open, and some with vocal folds vibrating. Put your hand on the front of your larynx again and make a long “SSSSS” sound. Now switch and make a “ZZZZZ” sound. You can feel your larynx vibrate on “ZZZZZ” but not on “SSSSS”. That’s because [s] is a voiceless sound, made with the vocal folds held open, and [z] is a voiced sound, where we vibrate the vocal folds. Do it again and feel the difference between voiced and voiceless.
Now take your hand off your larynx and plug your ears and make the two sounds again with your ears plugged. You can hear the difference between voiceless and voiced sounds inside your head.
I said at the beginning that there are three crucial mechanisms involved in producing speech, and so far we’ve looked at only two:
The oral cavity is the space in your mouth. The nasal cavity, obviously, is the space inside and behind your nose. And of course, we use our tongues, lips, teeth and jaws to articulate speech as well. In the next unit, we’ll look in more detail at how we use our articulators.
So to sum up, the three mechanisms that we use to produce speech are:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=40
1. Which articulators are responsible for the first sound in the word minor?
2. Which articulators are responsible for the final sound in the word wit?
3. Which articulators are responsible for the first sound in the word photography?
We know that humans produce speech by bringing air from the lungs through the larynx, where the vocal folds might or might not vibrate. That airflow is then shaped by the articulators.

Created by User:ish shwar (original .png deleted), .svg by Rohieb [GFDL (http://www.gnu.org/copyleft/fdl.html), CC-BY-SA-3.0 (http://creativecommons.org/licenses/by-sa/3.0/) via Wikimedia Commons
This image is called a sagittal section. It depicts the inside of your head as if we sliced right between your eyes and down the middle of your nose and mouth. This angle gives us a good view of the parts of the vocal tract that are involved in filtering airflow to produce speech sounds.
Let’s start at the front of your mouth, with your lips. If you make the sound “aaaaa” then round your lips, the sound of the vowel changes. We can also use our lips to block the flow of air completely, like in the consonants [b] and [p].
We also use our teeth to shape airflow. They don’t do much on their own, but we can place the tip of the tongue between the teeth, for sounds like [θ] and [ð]. Or we can bring the top teeth down against the bottom lip for [f] and [v].
If you put your finger in your mouth and tap the roof of your mouth, you’ll find that it’s bony. That is the hard palate. English doesn’t have very many palatal sounds, but we do raise the tongue towards the palate for the glide [j].
Now from where you have your finger on the roof of your mouth, slide it forward towards your top teeth. Before you get to the teeth, you’ll find a ridge, which is called the alveolar ridge. If you use the tip of the tongue to block airflow at the alveolar ridge, you get the sounds [t] and [d]. We also produce [l] and [n] at the alveolar ridge, and some people also produce the sounds [s] and [z] with the tongue at the alveolar ridge (though there are other ways of making the [s] sound.)
When we block airflow in the mouth but allow air to circulate through the nasal cavity, we get the nasal sounds [m] [n] and [ŋ].
Some languages also have nasal vowels. Make an “aaaaa” vowel again, then make it nasal. [aaaaa] [ããããã]
The articulator that you move to allow air into the nasal cavity is called the velum. You might also know it as the soft palate. For sounds made in the mouth, the velum rests against the back of the throat. But we can pull the velum away from the back of the throat and allow air into the nose. We can also block airflow by moving the body of the tongue up against the velum, to make the sounds [k] and [ɡ].
Farther back than the velum are the uvula and the pharynx, but English doesn’t use these articulators in its set of speech sounds.
Every different configuration of the articulators leads to a different acoustic output.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=42
1. The vowel sounds in the words neat and spread are both spelled “ea”. Do the vowels in the two words sound the same as each other or different?
2. Are the final sounds in the words face and mess the same as each other or different?
3. Are the first sounds in the two words gym and gum the same as each other or different?
In the first part of this book, we’re concentrating on the sounds of human speech. You might have already noticed that there’s a challenge to talking about speech sounds — English spelling is notoriously messy.
Take a look at these words:
say, weigh, they, rain, flame, lei, café, toupee, ballet
All of them contain the same vowel sound, [e], but the sound is spelled with nine different combinations of letters. Some of them are more common ways than others of spelling the sound [e], but even if we take away the ones that English borrowed from other languages, that still leaves five different ways of spelling one sound. One of the problems is that English has only five letter characters that represent vowels, but more than a dozen different vowel sounds. But it’s not just the vowels that are the problem.
English has the opposite problem as well. Take a look at these words:
cough, tough, bough, through, though
Here we’ve got a sequence of four letters that appear in the same order in the same position in each word, but that sequence of letters is pronounced in five different ways in English. Not only can a single sound be represented by very many different spellings, but even a single spelling is not consistent with the sounds that it represents.
Even one letter can be pronounced in a whole lot of different ways. Look at:
cake, century, ocean, and cello
The letter “c” represents four quite different sounds. Clearly, English spelling is a mess. There are a lot of reasons for why that might be.
The area where English first evolved was first inhabited by people who spoke early forms of Germanic and Celtic dialects. But then Normans invaded and brought all kinds of French and Latin words with their spellings. When the technology to print books was invented, there was influence from Dutch. So even the earliest form of English was influenced by many different languages.
Modern English also borrows words from lots of languages. When we borrow words like cappuccino or champagne, we adapt the pronunciation to fit into English but we often retain the spelling from the original language.
Another factor is that the English spelling system was standardized hundreds of years ago when it became possible to print books. A lot of our standard spellings became consistent when the Authorized Version of the Bible was published in the year 1611. Spelling hasn’t actually changed much since 1611, but English pronunciation sure has, so the way we produce the sounds of English has diverged from how we write the language.
Furthermore, English is spoken all over the world, with many different regional varieties. British English sounds quite different from Canadian English, which is different from Australian English, and Indian English is quite different again, even though all of these varieties are spelled in nearly the same way.
There’s even variation within each speaker of English, depending on the context: the way you speak is going to be different depending on if you’re hanging out with your friends or interviewing for a job or talking on the phone to your grandmother.
The important thing to remember for our purposes is that everyone who knows a language can speak and understand it, and children learn to speak and understand spoken language automatically. So in linguistics, we say that speaking and listening are the primary linguistic skills. Not all languages have writing systems, and not everyone who speaks a language can read or write it, so those skills are secondary.
So here’s the problem: as linguists, we’re primarily interested in speech and listening, but our English writing system is notoriously bad at representing speech sounds accurately. We need some way to be able to refer to particular speech sounds, not to English letters. Fortunately, linguists have developed a useful tool for doing exactly that. It’s called the International Phonetic Alphabet, or IPA. The first version of the IPA was created over 100 years ago, in 1888, and it’s been revised many times over the years. The last revision was fairly recent, in 2015. The most useful thing about the IPA is that, unlike English spelling, there’s no ambiguity about which sound a given symbol refers to. Each symbol represents only one sound, and each sound maps onto only one symbol. Linguists use the IPA to transcribe speech sounds from all languages.
When we use this phonetic alphabet, we’re not writing in the normal sense, we’re putting down a visual representation of sounds, so we call it phonetic transcription. That phonetic transcription gives us a written record of the sounds of spoken language. Here are just a few transcriptions of simple words so you can begin to see how the IPA works.
snake [snek]
sugar[ʃʊɡəɹ]
cake[kek]
cell[sɛl]
sell [sɛl]
Notice that some of the IPA symbols look like English letters, and some of them are probably unfamiliar to you. Since some of the IPA symbols look a lot like letters, how can you know if you’re looking at a spelled word or at a phonetic transcription? The notation gives us a clue: the transcriptions all have square brackets around them. Whenever we transcribe speech sounds, we use square brackets to indicate that we’re not using ordinary spelling.
You can learn the IPA symbols for representing the sounds of Canadian English in the next unit. For now, I want you to notice the one-to-one correspondence between sounds and symbols. Look at those first two words: snake and sugar. In English spelling, they both begin with the letter “s”. But in speaking, they begin with two quite different sounds. This IPA symbol [s] always represents the [s] sound, never any other sound, even if those other sounds might be spelled with the letter “s”. The word sugar is spelled with the letter “s” but it doesn’t begin with the [s] sound so we use a different symbol to transcribe it.
So, one IPA symbol always makes the same sound.
Likewise, one sound is always represented by the same IPA symbol.
Look at the word cake. It’s spelled with “c” at the beginning and “k-e” at the end, but both those spellings make the sound [k] so in its transcription, it begins and ends with the symbol for the [k] sound. Likewise, look at those two different words cell and sell. They’re spelled differently, and we know that they have different meanings, but they’re both pronounced the same way, so they’re transcribed using the same IPA symbols.
The reason the IPA is so useful is that it’s unambiguous: each symbol always represents exactly one sound, and each sound is always represented by exactly one symbol. In the next unit, you’ll start to learn the individual IPA symbols that correspond to the sounds of Canadian English.
The following tables give you some sample words so you can start to learn which IPA symbols correspond to which speech sounds. In these tables, the portion of the English word that makes the relevant sound is indicated in boldface type, but remember that English spelling is not always consistent, and your pronunciation of a word might be a little different from someone else’s. These examples are drawn from the pronunciation of mainstream Canadian English. To hear an audio-recording of the sound for each IPA symbol, consult the consonant, vowel, and diphthong charts available here.
The sounds are categorized here according to how they’re produced. You’ll learn more about these categories in units 2.6, 2.7 and 3.2.
| [p] | peach, apple, cap |
| [b] | bill, above, rib |
| [t] | tall, internal, light |
| [d] | dill, adore, kid |
| [k] | cave, ticket, luck |
| [ɡ] | give, baggage, dig |
| [f] | phone, raffle, leaf |
| [v] | video, lively, love |
| [θ] | thin, author, bath |
| [ð] | there, leather, breathe |
| [s] | celery, passing, bus |
| [z] | zebra, deposit, shoes |
| [ʃ] | shell, ocean, rush |
| [ʒ] | genre, measure, rouge |
| [h] | hill, ahead |
| [tʃ] | chip, achieve, ditch |
| [dʒ] | jump, adjoin, bridge |
| [m] | mill, hammer, broom |
| [n] | nickel, sunny, spoon |
| [ŋ] | singer, wrong |
| [l] | lamb, silly, fall |
| [ɹ] | robot, furry, star |
| [j] | yellow, royal |
| [w] | winter, flower |
| [ɾ] | butter, pedal (only between vowels when the second syllable is unstressed) |
| [i] | see, neat, piece |
| [ɪ] | pin, bit, lick |
| [e] | say, place, rain (in spoken Canadian English, [e] becomes [eɪ]) |
| [ɛ] | ten, said, bread |
| [æ] | mad, cat, fan |
| [a] | far, start |
| [u] | pool, blue |
| [ʊ] | look, good, bush |
| [o] | throw, hole, toe (in spoken Canadian English, [o] becomes [oʊ]) |
| [ʌ] | bus, mud, lunch |
| [ɔ] | store, more, corn |
| [ɑ] | dog, ball, father |
| [ə] | believe, cinnamon, surround (in an unstressed syllable) |
| [ɨ] | roses, wanted (in an unstressed syllable that is a suffix) |
| [ɚ] | weather, editor (in an unstressed syllable with an r-quality) |
| [ɝ] | bird, fur (in a stressed syllable with an r-quality) |
| [aɪ] | fly, lie, smile |
| [aʊ] | now, frown, loud |
| [ɔɪ] | boy, spoil, noise |
| [ju] | cue, few |

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=46
1. What kind of sound is the first sound in the word early?
2. What kind of sound is the first sound in the word junior?
3. What kind of sound is the first sound in the word winter?
Remember that there are three steps involved in producing speech sounds. The process starts with respiration as air flows up from the lungs. Phonation occurs at the larynx, where the vocal folds may or may not vibrate to produce voicing, and then we use our mouth, jaw, lips, teeth and tongue to shape the sound, which is called articulation.
In phonetics, we classify sounds according to how they’re produced, and also according to the acoustic properties of the sounds. The primary acoustic property that we’re interested in is called sonority. Sonority has to do with the amount of acoustic energy that a sound has. A simple example of this is that a loud sound is more sonorous and a quiet sound is less sonorous. But sonority is not just about loudness. Sounds that are made with lots of airflow from the lungs, and with vocal folds vibrating, are sonorous sounds. Sounds that have less airflow or don’t have voicing from the vocal folds have less sonority. Those two pieces of information, sonority and articulation, allow us to group sounds into three broad categories
We produce vowels with the vocal tract quite open and usually with our vocal folds vibrating so vowels have a lot of acoustic energy: they’re sonorous. Vowel sounds can go on for a long time: if you’re singing, when you hold the note, you hold it on the vowels. Make some vowel sounds and notice how you can hold them for a long time: “aaaaa iiiii uuuuu”.
The sounds that we call consonants are ones where we use our articulators to obstruct the vocal tract, either partially or completely. Because the vocal tract is somewhat obstructed, less air flows from the lungs, so these sounds have less energy, they’re less sonorous, and they’re usually shorter than vowels. Consonant sounds can be voiced or voiceless.
There’s also an intermediate category called glides that have some of the properties of vowels and some of the consonants. The vocal tract is unobstructed for glides, like for vowels, but they are shorter and less sonorous than vowels. We’ll learn more about glides when we take a closer look at vowels.
This acoustic notion of sonority plays a role in every language of the world because spoken words are organized around the property of sonority. Every single spoken word is made up of one or more syllables. You probably know that a syllable is like a beat in the rhythm of the word, so you know that ball has one syllable, basket has two syllables, and bicycle has three.
But what is a syllable, in phonetic terms? A syllable is a peak of sonority that is surrounded by less sonorous sounds. What that means is that a syllable is made up of a vowel, or some other very sonorous sound, with some sounds before it and after it that are less sonorous, usually glides and consonants. The most sonorous sound, the peak of sonority, is called the nucleus of a syllable.
Looking back at those words, we can see that the word ball contains the sonorous vowel sound [ɑ], with two less-sonorous consonants, [b] and [l] on each side of it. Likewise, basket has two vowel sounds [æ] and [ɪ], with the consonants [b] before the first syllable, [sk] between the two vowels, and [t] after the second vowel. Can you figure out what the vowel and consonant sounds are in the word bicycle? Remember that written letters don’t necessarily map directly onto speech sounds!

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=48
1. What is the articulatory description for the consonant sound represented by the IPA symbol [p]?
2. What is the articulatory description for the consonant sound represented by the IPA symbol [ð]?
3. What is the articulatory description for the consonant sound represented by the IPA symbol [ʃ]?
Let’s look more closely at the class of sounds we call consonants. Remember that consonants have some constriction in the vocal tract that obstructs the airflow, either partially or completely. We can classify consonants according to three pieces of information.
The first piece of information we need to know about a consonant is its voicing — is it voiced or voiceless? In the video about how humans produce speech, we felt the difference between voiced and voiceless sounds: for voiced consonants like [z] and [v], the vocal folds vibrate. For voiceless sounds like [s] and [f], the vocal folds are held apart to let air pass through.
The second thing we need to know about consonants is where the obstruction in the vocal tract occurs; we call that the place of articulation.
If we obstruct our vocal tract at the lips, like for the sounds [b] and [p], the place of articulation is bilabial.
The consonants [f] and [v] are made with the top teeth on the bottom lip, so these are called labiodental sounds.
Move your tongue to the ridge above and behind your top teeth and make a [t] or [d]; these are alveolar sounds. Many people also make the sound [s] with the tongue at the alveolar ridge. Even though there is quite a bit of variation in how people make the sound [s], it still gets classified as an alveolar sound.
If you’re making a [s] and move the tongue farther back, not quite to the soft palate, the sound turns into a [ʃ], which is called post-alveolar, meaning it’s a little bit behind the alveolar ridge. You also sometimes see [ʃ] and [ʒ] called “alveo-palatal” or “palato-alveolar” sounds because the place of articulation is between the alveolar ridge and the palate.
The only true palatal sound that English has is [j].
And if you bring the back of your tongue up against the back of the soft palate, the velum, you produce the velar sounds [k] and [ɡ].
Some languages also have uvular and pharyngeal sounds made even farther back in the throat, but English doesn’t have sounds at those places of articulation.
And of course English has a glottal fricative made right at the larynx, the sound [h].
In addition to knowing where the vocal tract is obstructed, to classify consonants we also need to know how the vocal tract is obstructed. This is called the manner of articulation.
If we obstruct the airflow completely, the sound is called a stop. When the airflow is stopped, pressure builds up in the vocal tract and then is released in an burst of air when we release the obstruction. So the other name for stops is plosives. English has two bilabial stops, [p] and [b], two alveolar stops, [t] and [d], and two velar stops [k] and [ɡ].
It’s also possible to obstruct the airflow in the mouth but allow air to flow through the nasal cavity. English has three nasal sounds at those same three places of articulation: the bilabial nasal [m], the alveolar nasal [n], and the velar nasal [ŋ]. Because airflow is blocked in the mouth for these, they are sometimes called nasal stops, in contrast to the plosives which are oral stops.
Instead of blocking airflow completely, it’s possible to hold the articulators close together and allow air to flow turbulently through the small space. Sounds with this kind of turbulence are called fricatives. English has labiodental fricatives [f] and [v], dental fricatives made with the tongue between the teeth, [θ] and [ð], alveolar fricatives [s] and [z], post-alveolar fricatives [ʃ] and [ʒ], and the glottal fricative [h]. Other languages also have fricatives at other places of articulation.
If you bring your articulators close together but let the air flow smoothly, the resulting sound is called an approximant. The glides [j] and [w] are classified as approximants when they behave like consonants. The palatal approximant [j] is made with the tongue towards the palate, and the [w] sound has two places of articulation: the back of the tongue is raised towards the velum and the lips are rounded, so it is called a labial-velar approximant.
The North American English [ɹ] sound is an alveolar approximant with the tongue approaching the alveolar ridge. And if we keep the tongue at the alveolar ridge but allow air to flow along the sides of the tongue, we get the alveolar lateral approximant [l], where the word lateral means “on the side”. The sounds [ɹ] and [l] are also sometimes called “liquids”
If you look at the official IPA chart for consonants, you’ll see that it’s organized in a very useful way. The places of articulation are listed along the top, and they start at the front of the mouth, at the lips, and move gradually backwards to the glottis. And down the left-hand side are listed the manners of articulation. The top of the chart has the manners with the greatest obstruction of the vocal tract, the stops or plosives, and moves gradually down to get to the approximants, which have the least obstruction and therefore greatest airflow.
In Essentials of Linguistics, we concentrate on the sounds of Canadian English, so we don’t pay as much attention to sounds with retroflex, uvular, or pharyngeal places of articulation. You’ll learn more about these if you go on in linguistics. And you probably noticed that there are some other manners of articulation that we haven’t yet talked about.
A trill involves bringing the articulators together and vibrating them rapidly. North American English doesn’t have any trills, but Scottish English often has a trilled [r]. You also hear trills in Spanish, French and Italian.
A flap (or tap) is a very short sound that is a bit like a stop because it has a complete obstruction of the vocal tract, but the obstruction is so short that air pressure doesn’t build up. Most people aren’t aware of the flap but it’s actually quite common in Canadian English. You can hear it in the middle of these words metal and medal. Notice that even though they’re spelled with “t” and “d”, they sound exactly the same when we pronounce them in ordinary speech. If you’re trying hard to be extra clear, you might say [mɛtəl] or [mɛdəl], but ordinarily, that “t” or “d” in the middle of the word just becomes an alveolar flap, where the tongue taps very briefly at the alveolar ridge but doesn’t allow air pressure to build up. You can also hear a flap in the middle of words like middle, water, bottle, kidding, needle. The symbol for the alveolar flap [ɾ] looks a bit like the letter “r” but it represents that flap sound.
When we’re talking about English sounds, we also need to mention affricates. If you start to say the word cheese, you’ll notice that your tongue is in the position to make a [t] sound. But instead of releasing that alveolar stop completely, like you would in the word tease, you release it only partially and turn it into a fricative, [tʃ]. Same thing for the word jam: you start off the sound with the stop [d], and then release the stop but still keep the articulators close together to make a fricative [dʒ]. Affricates aren’t listed on the IPA chart because they’re a double articulation, a combination of a stop followed by a fricative. English has only the two affricates, [tʃ] and [dʒ], but German has a bilabial affricate [pf] and many Slavic languages have the affricates [ts] and [dz].
To sum up, all consonants involve some obstruction in the vocal tract. We classify consonants according to three pieces of information:
- the voicing: is it voiced or voiceless,
- the place of articulation: where is the vocal tract obstructed, and
- the manner of articulation: how is the vocal tract obstructed.
These three pieces of information make up the articulatory description for each speech sound, so we can talk about the voiceless labiodental fricative [f] or the voiced velar stop [ɡ], and so on.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=51
1. What is the articulatory description for the vowel sound represented by the IPA symbol [i]?
2. What is the articulatory description for the vowel sound represented by the IPA symbol [ɛ]?
3. What is the articulatory description for the vowel sound represented by the IPA symbol [ɑ]?
Remember that the difference between consonants and vowels is that consonants have some obstruction in the vocal tract, whereas, for vowels, the vocal tract is open and unobstructed, which makes vowel sounds quite sonorous. We can move the body of the tongue up and down in the mouth and move it closer to the back or front of the mouth. We can also round our lips to make the vocal tract even longer.
Take a look at the IPA chart for vowels. Instead of a nice rectangle, it’s shaped like a trapezoid. That’s because the chart is meant to correspond in a very direct way with the shape of the mouth and the position of the tongue in the mouth. We classify vowels according to four pieces of information:
The high/mid/low distinction has to do with how high the tongue is in the mouth. Say this list of words:
beet, bit, bait, bet, bat
Now do the same thing, but leave off the “b” and the “t” and just say the vowels. You can feel that your tongue is at the front of your mouth and is moving from high in the mouth for [i] to fairly low in the mouth for [æ].
We can do the same thing at the back of the mouth. Say the words boot, boat.
Now do it again with just the vowels, [u] [o]. Your lips are rounded for both of them, but the tongue is higher for [u] than it is for [o]. The lowest vowel at the back of the mouth is [ɑ]. We don’t round our lips for [ɑ], and we often drop the jaw to move the tongue low and back.
We also classify vowels according to whether the lips are rounded or unrounded. In Canadian English, there are only four vowels that have lip rounding, and they’re all made with the tongue at the back of the mouth:
[u] as in boot
[ʊ] as in book
[o] as in boat
and [ɔ] as in bore
The final piece of information that we use to classify vowels is a little trickier to explain. English makes a distinction between tense and lax vowels, which is a distinction that a lot of other languages don’t have. Tense vowels are made with greater tension in the muscles of the vocal tract than lax vowels. To feel this difference, say the two words sheep and ship. And now make just the vowel sounds, [i], [ɪ]. The [i] sound in sheep and the [ɪ] sound in ship are both produced with the tongue high and front, and without lips rounded. But for [i], the muscles are more tense than for [ɪ]. The same is true for the vowels in late and let, [e] and [ɛ]. And also for the vowels in food and foot, [u] and [ʊ]
It can be hard to feel the physical difference between tense and lax vowels, but the distinction is actually an important one in the mental grammar of English. When we observe single-syllable words, we see a clear pattern in one-syllable words that don’t end with a consonant. There are lots of monosyllabic words with tense vowels as their nucleus, like
day, they, weigh
free, brie, she, tea
do, blue, through, screw
no, toe, blow
But there are no monosyllabic words without a final consonant that have a lax vowel as their nucleus. And if we were to try to make up a new English word, we couldn’t do so. We couldn’t create a new invention and name it a [vɛ] or a [flɪ] or a [mʊ]. These words just can’t exist in English. So the tense/lax distinction is an example of one of those bits of unconscious knowledge we have about our language — even though we’re not consciously aware of which vowels are tense and which ones are lax, our mental grammar still includes this powerful principle that governs how we use our language.
Here’s one more useful hint about tense and lax vowels. When you’re looking at the IPA chart 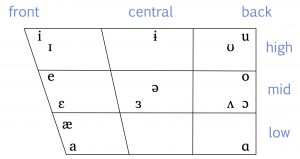 , notice that the symbols for the tense vowels are the ones that look like English letters, while the symbols for the lax vowels are a little more unfamiliar. That can help you remember which is which!
, notice that the symbols for the tense vowels are the ones that look like English letters, while the symbols for the lax vowels are a little more unfamiliar. That can help you remember which is which!
So far, all the vowels we’ve been talking about are simple vowels, where the shape of the articulation stays fairly constant throughout the vowel. In the next unit, we’ll talk about vowels whose shape changes. For simple vowels, linguists pay attention to four pieces of information:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=53
1. What is the diphthong sound in the word in the word proud?
2. What is the diphthong sound in the word in the word rain?
3. What is the diphthong sound in the word in the word sigh?
The last unit talked about simple vowels, where the tongue position stays pretty constant throughout the duration of the vowel. In addition to simple vowels, many languages include diphthongs, where we move our articulators while producing the vowel. This gives the sound a different a different shape at the end from how it begins. The word diphthong comes from the Greek word for “two sounds”.
There are three major diphthongs in English that have quite a noticeable change in the quality of the vowel sound.
Say these English words out loud: fly, tie, ride, smile. Now make the vowel sound [aɪ] again but hold it at the beginning [aaa]. The first part of the sound is the low front [a], but then the tongue moves up quickly at the end of the sound, ending it [ɪ]. So the [aɪ] sound is a diphthong, and it gets transcribed with two consecutive symbols:[aɪ].
In the words now, loud, brown, the tongue again starts low and front [a], and then it moves high and to the back of the mouth, and the lips get rounded too! The second part of this diphthongs is but the high back rounded [ʊ]. The [aʊ] diphthong is transcribed like this: [aʊ].
The third major diphthong in English occurs in words like toy, boil, coin. It starts with the tongue at the back of the mouth and lips rounded [ɔ], then moves to the front with lips unrounded. It is transcribed like this: [ɔɪ].
Some linguists also consider the vowel sound in cue and few to be a diphthong. In this case, the vowel sound starts with the glide [j] and then moves into the vowel [u].
In addition to these major English diphthongs, speakers of Canadian English also have a tendency to turn the mid-tense vowels into diphthongs.
For example, let’s look at the pair of vowels [e] and [ɛ] from the words gate and get. They’re both mid, front, unrounded vowels, but [e] is tense – it’s made with greater tension in the muscles of the vocal tract than [ɛ]. Canadian English speakers pronounce the lax vowel in get as a simple vowel [ɡɛt], but for the tense vowel, we tend to move the tongue up at the end: [ɡeɪt]. We do it so systematically that it’s very hard for us to hear it, but it’s always there.
We do the analogous thing for the mid-back vowel [o] like in show and toe: at the end of the [o] vowel, the tongue moves up a little bit so we produce the vowel as [oʊ]. Notice that the lips are rounded for both parts of this diphthong.
To sum up, a diphthong is a vowel sound that involves movement of the tongue from one position to another. Nearly all dialects of English include the three major diphthongs [aɪ] , [aʊ] , and [ɔɪ]. These ones are called the major diphthongs because they involve large movements of the tongue.
In Canadian English, speakers also regularly produce diphthongs for the tense vowels, [eɪ] and [oʊ], but not all English dialects do this. Some linguists consider these ones to be minor diphthongs.
Adapted from
http://www.oercommons.org/courses/how-language-works-the-cognitive-science-of-linguistics/view
© 2006. Indiana University and Michael Gasser.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation.
URL: www.indiana.edu/~hlw/PhonProcess/accents.html
Edition 3.0; 2006-12-31
Another point to keep in mind is that in most countries there is a standard, prestige accent alongside a number of accents associated with particular regions, social classes, or ethnic groups. Each of these non-standard accents can be described in its “broad” form, the form that is most different from the standard in the country where it is spoken, but what many people are speaking much of the time is something in between a particular non-standard accent and the relevant standard. In this section, we concentrate mostly on broad variants of non-standard accents because they illustrate the range of possible differences best.
When comparing two dialects or accents, one possibility is to see one of them as deviating from the other. A biased view of non-standard dialects often starts this way: the speakers of these dialects are seen as just making mistakes with the standard when what they say is non-standard. But of course, this is not what is actually happening. Speakers of non-standard dialects learned the conventions of these dialects by hearing other speakers speak them, just as the speakers of standard dialects learned the conventions of their dialects. They are no more speaking the standard wrong than the speakers of the standard dialect are speaking their dialect wrong.
Before looking at examples of differences between accents, it might help to have a sense of what the major accents are and where they’re spoken.
There is no “British” accent. England, Scotland, Ireland, and possibly Wales all have their own unofficial standard accents, and the standards of Scotland and Ireland, in particular, are as different from that of England as American accents are. The standard, or prestige, accent of England is usually referred to as Received Pronunciation (RP). This is what the royal family, all recent Prime Ministers, and most BBC announcers speak. It is probably what most Americans think of as an “English” accent, though it is spoken as a native accent by no more than about 10% of the English population. It differs most noticeably from General American in the pronunciation of a few vowels and in the way [ɹ] is treated following vowels. For example, in RP there would be no [ɹ] sounds at all in the phrase the northern fourth of the park.
Within England, there are many identifiable regional accents, probably more than in the United States in fact. Among these, London accent (sometimes called “Cockney”) stands out because it is familiar to many Americans through film and drama characters such as Eliza Dolittle in Pygmalion/My Fair Lady and because it has a number of very characteristic features. Many of the vowels in this accent differ considerably from RP and General American. Other very striking features are the loss of initial [h] (“‘e ‘as an ‘ard ‘eart” = “he has a hard heart“) and the frequent glottal stops in place of other stops in other accents (“iʔ’ll taʔe a loʔ o’ time to seʔle” = “it’ll take a lot of time to settle”). Perhaps the other major accent boundary in England separates the accents of the north from those of the south. Americans may be familiar with the English of Northern England through the speech of the Beatles or the characters in films such The Full Monty. These accents can be identified fairly easily because they make no distinction between the vowels [ʌ] and [ʊ]; both are pronounced like [ʊ], so that the words look and luck are homophones.
Scottish and Irish English share one feature with northern England English; the tense vowels [i], [u], [e] and [o] are not pronounced as diphthongs, as they are in RP and General American. In addition, these accents are like General American, and unlike most accents of England, in how they treat [ɹ] after vowels.
The unofficial standard accent of the United States is usually called General American (GA) or Mainstream US English (MUSE). This is the accent of much of the Midwest and the West and the most frequent accent for US newscasters, though, interestingly, many of the more recent US Presidents have spoken regional varieties rather than GA. As the prestige accent, it has been encroaching on some regional accents, for example, in the northeast, but at the same time, changes within GA are creating what amount to new accents. One striking example of this is Northern Cities accent, spoken in cities such as Chicago, Detroit, Cleveland, and Rochester, and distinct from GA in the pronunciation of lax vowels. So for example, the word socks in the name of the Chicago White Sox is pronounced [saks] in the Northern Cities accent, as compared to [sɑks] in Canadian English.
The Southern US accent is spoken by people mainly in the southeastern part of the country. Like the London accent, this accent has strikingly different vowels from other English accents. African-American Vernacular English (AAVE) is a dialect associated with an ethnic group rather than a region, though of course, you don’t have to be African-American to have learned it. The accent associated with this dialect is similar in many ways to Southern US accent, while the phonology, morphology and syntax of this variety have their own characteristic properties.
People from the northeastern US are often easy to identify by their accents; the accent of New York City stands out within this region, again mostly for its vowels. Some other US cities, especially Pittsburgh, are known for particular pronunciation conventions. In Pittsburgh, for example, [a] may be used where GA has [aʊ], so downtown may be [dantan].
Standard Canadian English (except in the province of Newfoundland) is very similar to General American, and it doesn’t vary much from place to place. One characteristic of Canadian English is the pronunciation of [aɪ] and [aʊ] in certain contexts, which we’ll learn about in Section 4.6.
English is the native language of much of the Caribbean, with some features common to the region and others specific to particular islands. As with other accents, there are characteristic vowels in these accents, and in addition, a tendency in the Caribbean, as there is in some US accents, to make no distinction between [t] and [θ] or between [d] and [ð]. Jamaican English in particular also has quite striking intonation patterns.
English is the native language of most Australians and New Zealanders and a sizable minority of South Africans. While the standard English accents of these countries tend to approach RP, the broad accents of most English speakers in all three countries have tense vowels similar to those in the London accent. The lax front vowels of Australian and New Zealand English differ from those in other accents.
English is spoken as a second language by millions of people, especially in regions that were once colonized by Britain in South Asia and Africa. In some of these regions, there are particular English pronunciation conventions that derive from the phonology of the local languages. For example, in the English of South Asians (Indians, Pakistanis, Bangladeshis, Sri Lankans, Nepalese, Bhutanese, and Maldivians), the alveolar consonants [t], [d], [n], and [l] tend to be replaced by retroflex consonants, which are common in the languages of this region. These non-native conventions are one of the ways that English is becoming even more of an international language.
Exercise 1. For each of the following words, give the IPA symbol and the articulatory description for the first sound in the word:
Exercise 2. For each of the following words, give the IPA symbol and the articulatory description for the vowel sound in the word:
Exercise 3. For each of the following words, give the IPA symbol and the articulatory description for the last sound in the word:
Exercise 4. Listen to these speakers of Australian English and Canadian English compare their pronunciations of various words.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=57
Pay special attention to the word leisure. As accurately as you can, describe the difference between the two pronunciations using the new vocabulary you’ve learned in Chapter 2.
(This exercise is adapted from Linguistics 001: Introduction to Linguistics by Mark Liberman. Used with permission.)
In this chapter, you’ve learned that speaking and listening are the primary linguistic skills, and you’ve started to learn to think about words in terms of their sounds and not their letters. You know the names of the parts of the body that humans use to produce speech, and you know how to classify consonants and vowels according to how they’re produced. In the next Chapter, you’ll get more practice at using the International Phonetic Alphabet to transcribe the sounds of Canadian English.
Now that you know how humans use their articulators to produce speech, and how linguists classify speech sounds, you’re ready to learn how to use the International Phonetic Alphabet to transcribe speech sounds. In this chapter, we learn some of the principles for doing a phonetic transcription of the sounds of Canadian English.
When you’ve completed this chapter, you will be able to:
Learning to use the IPA to transcribe speech can be very challenging, for many reasons. One reason we’ve already talked about is the challenge of ignoring what we know about how a word is spelled to pay attention to how the word is spoken. Another challenge is simply remembering which symbols correspond to which sounds. The tables in Units 2.4 and 3.2 may seem quite daunting, but the more you practice, the better you’ll get at remembering the IPA symbols.
A challenge that many beginner linguists face is deciding exactly how much detail to include in their IPA transcriptions. For example, if you know that Canadian English speakers tend to diphthongize the mid-tense vowels [e] and [o] in words like say and show, should you transcribe them as the diphthongs [eɪ] and [oʊ]? And the segment [p] in the word apple doesn’t sound quite like the [p] in pear; how should one indicate that? Does the word manager really begin with the same syllable that the word human ends with?
Part of learning to transcribe involves making a decision about exactly how much detail to include in your transcription. If your transcription includes enough information to identify the place and manner of articulation of consonants, the voicing of stops and fricatives, and the tongue and lip position for vowels, this is usually enough information for someone reading your transcription to be able to recognize the words you’ve transcribed. A transcription at this level is called a broad transcription.
But it’s possible to include a great deal more detail in your transcription, to more accurately represent the particulars of accent and dialect and the variations in certain segments. A transcription that includes a lot of phonetic detail is called a narrow transcription. The rest of this chapter discusses the most salient details that would be included in a narrow transcription of the most widespread variety of Canadian English.
You can see the official version of the full IPA chart on the website of the International Phonetic Association here.
In Essentials of Linguistics, we concentrate on the IPA symbols for transcribing the speech sounds of Canadian English.
Figure 1 shows the IPA symbols for the consonants in Canadian English:
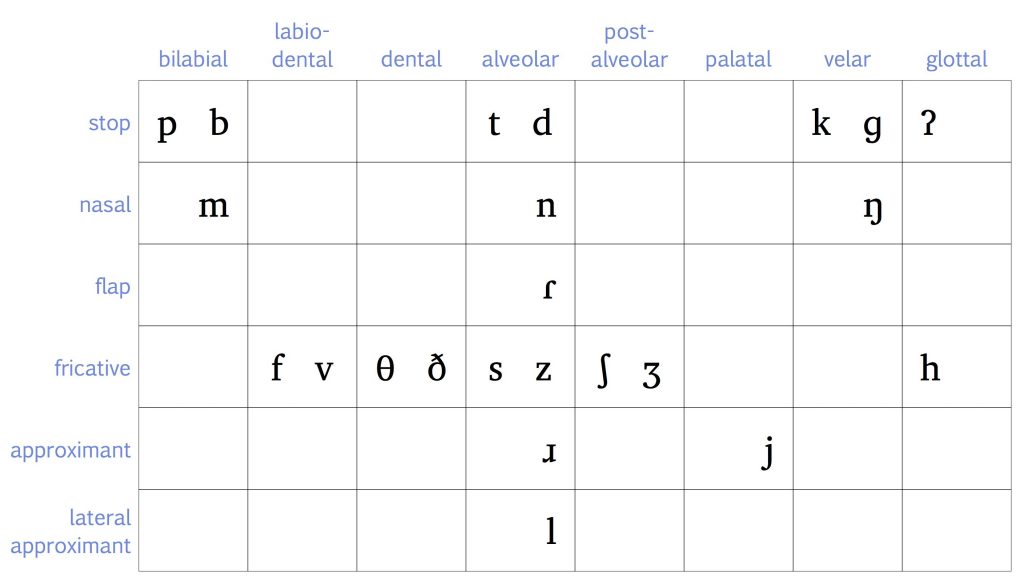
Remember that this table lists the manner of articulation from top to bottom in order of how obstructed the vocal tract is: the greatest obstruction is for stop consonants, and the least obstruction is for approximants. And from left to right, the table depicts a place of articulation, starting at the front of the mouth with the bilabial sounds and moving all the way back to the glottis. When there are two symbols given in one cell, the one on the left is voiceless and the one on the right is voiced.
There are three speech sounds that are part of Canadian English that don’t fit neatly into this table. Remember that affricates have a two-part manner of articulation: they begin with a complete obstruction of the vocal tract, but that obstruction is released only partially. You can think of an affricate like a stop combined with a fricative, and the symbols that we use to transcribe them reflect that. Because they have a two-part manner of articulation, the affricates [tʃ] and [dʒ] don’t fit into the consonant chart. The other sound that doesn’t fit on the chart is the approximant [w]. It has two places of articulation: the lips are rounded, and the body of the tongue moves towards the velum. So the IPA’s name for the segment [w] is a labial-velar approximant.
Figure 2 shows the IPA symbols for the vowels of Canadian English:
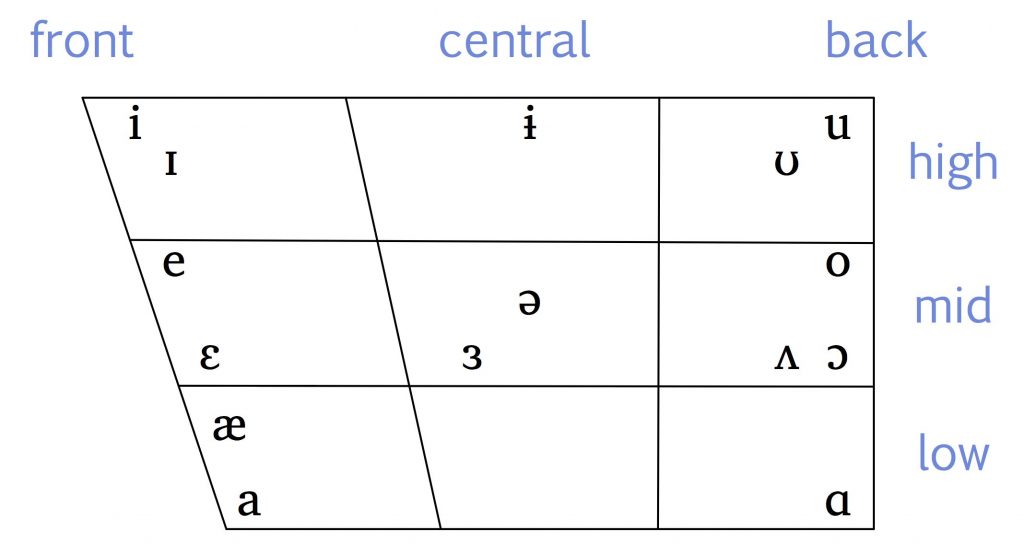
Remember that the vowel trapezoid is meant to correspond to the position of the tongue in the mouth.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=67
1. The video indicated that the word funnel can be transcribed to indicate that the second syllable consists of a syllabic [l̩]. The word elbow is also spelled with the letters ‘el’. Say the two words to yourself several times. Which is the correct transcription for elbow?
2. The words human and manager both contain a syllable that is spelled with the letters ‘man’. In which word does that syllable contain a syllabic [n̩]?
3. In the word umbrella, is the [m] syllabic?
In the word rhythm, the second syllable is unstressed, and it’s pretty short. Most of the time, in ordinary rapid speech, that second syllable doesn’t have a vowel in it at all. Our articulators go right from the [ð] sound at the end of the first syllable into the [m] sound. The [m] itself becomes the nucleus of the syllable. It is said to be a syllabic consonant, and we use a special notation to transcribe it: [ɹɪðm̩]. Look at that little vertical line below the [m] symbol — that’s called a diacritic. Diacritics are special additional notations we add to IPA symbols to give extra information about the sounds. That vertical line is the diacritic for a syllabic consonant.
Here’s an example of a liquid consonant becoming syllabic. When we speak the word funnel, we don’t produce a vowel in the second, unstressed syllable. Instead, we pronounce the [l] as a syllabic [l̩], so that it is the nucleus of the syllable. The notation is the same, with the diacritic for the syllabic [l̩]: [fʌnl̩].

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=69
1. The following city names all contain the letter ‘t’ within the word. In which of them is the letter ‘t’ pronounced as [th]?
2. The following words all contain the segment /k/. In which of them is it pronounced as the allophone [kh]?
3. The following words all contain the segment /p/. In which of them is it pronounced as the allophone [ph]?
To illustrate what aspiration is, I’m going to ask you to say a silly sentence: The spy wanted to buy a blueberry pie.
Did you feel any differences between the words spy, buy and pie? For native speakers of English, the word pie is produced with a little puff of air as the [p] is released. That puff of air is called aspiration. English speakers systematically produce aspiration on voiceless stops at the beginning of a stressed syllable, but not on voiced stops. To understand why we have to think about voicing and about the manner of articulation.
Remember that voiced sounds are produced by vibrating the vocal folds, whereas voiceless sounds have the vocal folds held open so air can pass freely between them. Remember also that producing a stop involves closing off the vocal tract completely for a moment, then releasing the obstruction and allowing air to flow freely again.
Think about the voiced stop at the beginning of the word buy. The lips are closed – that’s the stop closure – and the vocal folds start vibrating for the voiced [b]. Then the lips open and the stop is released, and the vocal folds keep vibrating for the diphthong [aɪ].
But in the word pie, things work differently. The lips are closed for the bilabial stop. But because [p] is a voiceless stop, the vocal folds are not vibrating. We open the lips to release the stop, but 30 or 40 milliseconds pass before we start vibrating the vocal folds. That 30-40 milliseconds between when the stop closure is released and the voicing begins is called the voice onset time or VOT. In English, voiceless stops in certain positions have a VOT of 30-40 milliseconds, so we say that they’re aspirated. But voiced stops have a much shorter VOT, of about 0-10 milliseconds. In other words, the vocal folds start vibrating at almost exactly the same time as the stop closure is released, so voiced stops in English are unaspirated. The diacritic to indicate aspiration on a stop is a little superscript h, like so: [ph, th, kh].
But to make matters even more complicated, it’s not all voiceless stops that get aspirated in English – only voiceless stops at the beginning of a stressed syllable. In words like appear and attack, the voiceless stop isn’t the first sound in the word, but it comes at the beginning of a stressed syllable so it gets aspirated. [əphiɹ] [əthæk]
But in the words apple and nickel, the voiceless stop comes after a stressed syllable and before an unstressed syllable, so it doesn’t get aspirated. [æpəl] [nɪkəl]
We don’t aspirate voiceless stops at the ends of words, like in brick. [bɹɪk]
And we don’t aspirate voiceless stops following an [s], even if they’re at the beginning of a stressed syllable:
Aspiration of voiceless stops is something that native speakers do so regularly and so automatically that it’s very hard for us to perceive it because it’s just always there. To convince you, I’m going to record someone saying this sentence and show you the waveforms. This program is known as a waveform editor. And here’s Kendrick’s voice saying that sentence.
The spy wanted to buy a blueberry pie.
Here’s the waveform: this is a visual representation of the sound waves that Kendrick just produced. See that I can select certain parts of the sentence and play them back. spy, buy, pie
Look first at buy – you can see that there’s very a brief silence: that’s where Kendrick’s lips were closed for the bilabial stop. Then when he releases his lips the waveform gets nice and big for the sonorous vowel [aɪ].
Look over here at pie. You see the same silence where the lips are closed, and the same big waveform for the vowel [aɪ] but before the vowel, there’s this noisy burst of turbulence – that’s the aspiration.
And now look at spy. We see the turbulence at the beginning for the fricative [s], followed by the silence while the lips are closed and the nice sonorous vowel. But there’s no burst of noise following the release of the lips because the [p] in spy was not aspirated. In fact, if I select just the -py portion of spy, what does it sound like? To a native speaker of English, this part sounds like buy, because the [p] is unaspirated.
When you’re transcribing words with the voiceless stops [p t k], your challenge will be to figure out if the stops are aspirated or unaspirated, so you can indicate the aspiration in your narrow transcription. In most varieties of English, aspiration happens in these predictable environments.
One thing that I want you to remember is that this pattern of aspiration is particular to the grammar of English, but stops behave differently in other languages. In French and Spanish, for example, voiceless stops are almost always unaspirated. And some languages, like Thai, actually have a three-way distinction between voiced, unaspirated voiceless, and aspirated voiceless stops.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=71
1. What articulatory process is at work when the word bank is pronounced as [bæŋk]?
2. What articulatory process is at work when a child pronounces the word yellow as [lɛloʊ]?
3. What articulatory process is at work when the word cream is pronounced as [khɹ̥ijm]?
Assimilation can go in the other direction too: sometimes the properties of one speech segment persevere into the next segment. Say these two words out loud: bleed, please. The two [l] sounds in these two words are a little different from each other. For bleed, the vocal folds are vibrating for the voiced [b] and they keep vibrating to produce the voiced [l]. We know that [l] is usually voiced so there’s nothing remarkable about that. But for please, the vocal folds are held apart for the voiceless [ph]. We start making the [l] before the vocal folds start to vibrate, so the [l] becomes voiceless in this context. We say that the [l] following a voiceless stop is devoiced, and it gets transcribed with the diacritic for voicelessness, like this: [l̥]. In this case, the voiceless property of the [p] is persevering; it’s sticking around to have an influence on the [l], so we call it perseveratory assimilation. You might also see this called progressive assimilation because the voicelessness of the first sound progresses, or moves forward, onto the following sound. One thing to note about the diacritic for voicelessness: it only gets used when a sound that is ordinarily voiced becomes voiceless in one of these articulatory processes. An [l] is usually voiced, so if it gets devoiced it gets the diacritic. But a sound like [h] or [s] is already voiceless, so it wouldn’t make any sense to transcribe it with the diacritic.
So assimilation can be anticipatory, where a speech sound is influenced in anticipation of the sound that’s about to be spoken after it, or perseveratory, where a sound is influenced by properties persevering, or lingering, from the sound that was just spoken.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=73
1. What articulatory process is at work when the word idea is pronounced as [aɪdijɚ]?
2. What articulatory process is at work when the word gorilla is pronounced as [ɡɹɪlʌ]?
3. What articulatory process is at work when the word you is pronounced as [jə]?
While we were learning to do IPA transcription we talked about vowel reduction. It’s a very common process in rapid, natural speech. In English, the vowel in an unstressed syllable often gets reduced to the mid-central vowel schwa [ə]. This happens in lots of words. For example, we don’t usually pronounce this word electric as [ilɛktɹɪk]. Instead, because the first syllable is unstressed, the vowel gets reduced, and we say [əlɛktɹɪk]. Likewise, this word today doesn’t get pronounced as [tudeɪ]. The vowel in the first, unstressed syllable gets reduced and we say [tədeɪ].
In fact, sometimes an unstressed vowel gets reduced so much that it disappears altogether! This process is called, obviously, deletion. In some varieties of English, reduced vowels are systematically deleted in certain predictable environments, like in police or garage. Deletion can also occur within consonant clusters. It’s pretty common for speakers to delete the first [ɹ] in surprise or the [d] in Wednesday. Deletion also happens when we borrow words from other languages. For example, take the Greek word pteron, which means “wing”. When we borrow this word and incorporate it into helicopter, we pronounce both the [p] and the [t]. But when it comes at the beginning of a borrowed word, like pterodactyl, we just delete the [p] altogether, since English doesn’t allow two stops in a syllable onset.
Sometimes when we’re speaking, extra segments find their way into our words, as a result of coarticulation. Can you guess what word I’m saying? [phɹɪnts] Was it prince or prints? Only one of them is spelled with a “t”, but we pronounce them both the same way. In prince, an alveolar stop appears between the alveolar nasal and the alveolar fricative. The articulatory process that inserts an extra sound is called epenthesis. In English, this tends to happen between nasals and stops or between nasals and fricatives. Another example is in the word something, where we often epenthesize a little bilabial stop [p] between the bilabial nasal [m] and the voiceless fricative [θ]. Or when George W. Bush famously pronounced the word nuclear as [nukjəlɚ], he was epenthesizing a [j] between the [k] and [l].
Some articulatory processes result from speech errors. Some of these errors are characteristic of children’s speech, and some of them just occur in everyday rapid speech. Children’s speech often includes the process of metathesis, exchanging the position of speech segments. When my niece was little, she used to pronounce the word hospital as [hɑstɪbəl], exchanging the positions of the two stops. Metathesis can also happen when we borrow words from another language. When English speakers want to buy a burrito from the restaurant chain called Chipotle, we often metathesize the [t] and [l] and say, [tʃəpolti], because the “tl” sequence is rare in English.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=75
1. Young children’s voices are usually recognizably different from adult’s voices. Which factor is likeliest to be different between children’s speech and adults’ speech?
2. In English, yes-no questions often conclude with rising pitch, whereas wh-questions often have a falling pitch on the final words. Is this pitch difference a difference in tone or in intonation?
3. English uses pitch as one factor in syllable stress. There are many English pairs of words like record (noun) and record (verb), which are spelled the same but differ in their stress patterns. Which of the following is true for this pair of words?
Some languages use pitch information to signal changes in word meaning. If a language uses pitch this way, the pitch information is called tone. These example words are from Yoruba, a language spoken in Nigeria. If you look just at the segmental level, these words all seem to be transcribed the same. But speakers of Yoruba vary their pitch when they speak these words so that the meaning of the word changes depending on whether the second syllable has a high tone, a mid-tone, or a low tone. Probably the best-known tone language is Mandarin, which has five different tones. Looking at these five words, you can see that they contain the same segments, but it’s the tones that distinguish their meaning.
Languages also use pitch in another way, not to change word meaning, but to signal information at the level of the discourse, or to signal a speaker’s emotion or attitude. When pitch is used this way, it’s called intonation rather than tone. English uses pitch for intonation — let’s look at some examples.
Sam got an A in Calculus.
Sam got an A in Calculus!
Sam got an A in Calculus?
Sam? got an A? in Calculus?
All of these sentences contain the same words (and the same segments) but if we vary the intonation, we convey something different about the speaker’s attitude towards the sentence’s meaning. Notice that we sometimes use punctuation in our writing to give some clues about a sentence’s prosody.
Another component of suprasegmental information is the length of sounds. Some sounds are longer than others. Listen carefully to these two words in English. beat, bead. The vowel sound in both words is the high front tense vowel [i]. But in bead, the vowel is a little longer. This is a predictable process in English — vowels get longer when there’s a voiced sound in the coda of the syllable. The diacritic to indicate that a segment is long looks a bit like a colon [iː].
So a sound can change in length as the result of a predictable articulatory process, or, like intonation, length can signal discourse-level information about an utterance. Consider the difference between, That test was easy, and, That test was eeeeeeeeeeeeeaaasyyyyyyyy. Some languages use length contrastively, that is, to change the meaning of a word. In these words in Yapese, a language of the Western Pacific region, you can see that making a vowel long leads to a completely different word with a new meaning. In these words from Italian, consonant length can change the meaning of a word, so fato means fate, but fatto means fact.
To sum up, suprasegmental information, also known as prosody, is that sound information that’s above the level of the segment. It consists of pitch, loudness, and length. Many languages use prosody to provide discourse-level information, and some languages also use prosody to change word meanings.
Adapted from:
http://www.oercommons.org/courses/how-language-works-the-cognitive-science-of-linguistics/view
© 2006. Indiana University and Michael Gasser.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation.
URL: www.indiana.edu/~hlw/PhonProcess/wild.html
Edition 3.0; 2011-08-30
If you’ve listened carefully to your own pronunciation of English words since you started learning about speech sounds, you might have noticed that the pronunciation that’s transcribed doesn’t always correspond to the way you sometimes say the words and that your pronunciation varies with the situation.
In Unit 2.3, we already saw that the conventions characterizing a particular dialect can change depending on the context the language is used in. What’s appropriate in one context may not be in another. This applies to pronunciation, as well as to vocabulary and grammar.
The dimension we will be concerned with here is sometimes referred to in terms of how “careful” the speech is. The “care” referred is care on the part of the Speaker. To what extent does the Speaker make an effort to accurately produce each of the segments and suprasegmental features of the words? To make sense of this idea, we will have to assume that each word in a dialect has a “careful” pronunciation, that is, how the word would sound if produced in isolation or with some emphasis within a sentence and in a relatively formal setting. In general, as the word gets less emphasis and the setting gets more casual, we find a tendency for Speakers to deviate from the careful pronunciation. These deviations are Speaker-oriented; that is, they can all be seen as making the pronunciation easier in one way or another; they are simplifications. Simplification is possible because in the casual situations where it is most common, the Hearer knows the Speaker well and is better able to predict what the Speaker is saying than a stranger would be. In this unit, we will look at some examples of the simplifications that occur in casual English. We will see that they can often be described in terms of the articulatory processes that we talked about in Units 3.5 and 3.6.
Before we look at the simplifications that happen in English as speech becomes more casual, we need to look at some basic features of English phonology.
First, in English, as in many languages in which stress plays a major role, there are significant differences between stressed and unstressed syllables. Stressed syllables permit all of the possible vowel segments, whereas the vowels in unstressed syllables are most commonly produced as [ə], [ɨ], or [ɪ]. We can observe these differences most clearly when we look at how the pronunciation of a syllable changes when it becomes stressed or unstressed. Consider the second syllables in the following related pairs of words:
melody, melodic
repeat, repetition
In melodic the second syllable is stressed, and the vowel is pronounced [ɑ]. In melody it is unstressed, and the vowel is pronounced [ə]. In the second pair, the second syllable of repeat is stressed and the vowel is [i], but when the second syllable is unstressed, as in repetition, the vowel is [ə].
When a word contains a [t] or [d] in the onset of an unstressed syllable, very often the tongue makes only brief contact with the alveolar ridge, so that instead of a plosive, only a very brief flap [ɾ] is produced. In the following pairs of words, compare the second consonant.
metal, metallic
medal, medallion
In both metal and medal, the first syllable is stressed and the second is unstressed. Both words are pronounced as [mɛɾl̩]. But in metallic and medallion, the second syllable is stressed. In the onset of a stressed syllable, the segments are pronounced as [th] and [d], respectively.
When a verb that ends in a vowel takes an affix that begins with a vowel, like in trying, or showing, the vowel in the second syllable might disappear in casual speech. Likewise, if the past-tense affix -ed or the plural -s is added to a word that ends in a cluster of consonants, then some of those consonants might disappear. Some examples are given below:
| careful speech | casual speech | |
| trying | [tɹajɪŋ] | [tɹaɪŋ] or [tɹaɪn] |
| showing | [ʃowɪŋ] | [ʃoʊŋ] or [ʃoʊn] |
| asked | [æskt] | [æst] |
| thanked | [θæŋkt] | [θæŋt] |
| fifths | [fɪfθs] | [fɪθs] |
If a word contains the same consonant twice, with only an unstressed vowel in between, the vowel and second consonant are often deleted, as in these examples:
| careful speech | casual speech | |
| probably | [pɹɑbəbli] | [pɹɑbli] |
| necessary | [nɛsəsɛri] | [nɛsɛri] |
| mirror | [miɹəɹ] | [miɹ] |
Other possible simplifications may occur across the boundaries between words. Consider what happens when an alveolar consonant ends up before a [j], as in two places in the following sentence.
Write your name on this yellow sheet.
Speaking carefully, most people would pronounce the two parts shown in bold as [tj] and[sj]. But when we speed up and allow ourselves to simplify, these may become [tʃ] and [ʃ]. This is an example of assimilation (for more examples, see Unit 3.5). The alveolar and palatal consonants combine to yield single consonants that are at the postalveolar place of articulation, in between the original places.
If a set of words occur together very frequently, then they can be easily predicted by the hearer, so they are good candidates for simplification by the speaker.
| careful speech | casual speech |
| would have | [wʊdə] |
| going to | [gʊnə] |
| got to | [gɑɾə] |
| want to | [wɑnə] |
| have to | [hæftə] |
| supposed to | [spostə] |
| I’m going to | [æŋgʊnə] or [æmʊnə] |
| What did you think? | [wʌdʒə θɪŋk] |
| How have you been? | [hawvjə bɪn] |
| I don’t know | [ædəno] |
Let’s summarize what we found for simplified speech in English. First, how likely a word or sequence of words is to be simplified depends on at least on these factors.
Second, the simplifications that occur involve assimilation; the reduction of vowels, often to [ə]; the merging of sequences of the same consonant; the deletion of [ə] and of some initial or final consonants. Many of these processes are general processes in the language. In some cases, however, the simplifications are conventions associated with particular words and must be learned separately.
The following sentences are all the first lines of books. For each, provide an IPA transcription, as narrow as you are able, of how the sentence would be spoken in Canadian English. (Do not try to transcribe the title of the novel or the author’s name.)
You have now had a good deal of practice at transcribing words and sentences in Canadian English, including the salient phonetic details for narrow IPA transcription of English. You’re starting to see that there can be variability in how a given segment is pronounced, even if it gets represented with a single IPA symbol. Articulatory processes play a sizeable role in how speech sounds vary, and suprasegmental information contributes to variability as well. In the next chapter, we’ll see how the mind responds to the variability that our articulators produce.
While the previous two chapters concentrated on how speech sounds are produced in the mouth, this chapter focuses on how speech sounds are organized in the mind. While two different languages might contain the same speech sounds, the mental grammar of each language could treat those sounds very differently. The challenge to studying mental grammar is that we can’t observe the mind directly, so in this chapter, we’ll learn how we can observe language behaviour to draw conclusions about mental grammar.
When you’ve completed this chapter, you will be able to:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=84
1. Are the phonetically different segments [m] and [n] phonemically contrastive in English?
2. Are the phonetically different segments [p] and [pʰ] phonemically contrastive in English?
3. Do the words sight and site form a minimal pair in English?
In the last couple of chapters, we’ve seen lots of ways that sounds can differ from each other: they can vary in voicing, in place and manner of articulation, in pitch or length. Within the mental grammar of each language, some of these variations and meaningful and some are not. Each language organizes these meaningful variations in different ways. Let’s look at some examples.
In the English word please, I could pronounce it with an ordinary voiced [l]: [phliz] it would be a little unnatural but it’s possible. Or, because of perseveratory assimilation, I could devoice that [l] and pronounce it [phl̥iz]. We’ve got two slightly different sounds here: both are alveolar lateral approximants, but one is voiced and one is voiceless. But if I pronounce the word [phliz] or [phl̥iz], it means the same thing. The voicing difference in this environment is not meaningful in English and most people never notice if the [l] is voiced or not.
In the words van and fan, each word begins with a labio-dental fricative. In van, the fricative is voiced and in fan it’s voiceless. In this case, the difference in voicing is meaningful: it leads to an entirely different word, and all fluent speakers notice this difference! Within the mental grammar of English speakers, the difference between voiced and voiceless sounds is meaningful in some environments but not in others.
Here’s another example. I could pronounce the word free with the ordinary high front tense vowel [i]. Or I could make the vowel extra long, freeeee. (Notice that we indicate a long sound with this diacritic [iː] that looks a bit like a colon.) But this difference is not meaningful: In English, both [fri] and [friː] are the same word. In Italian, a length difference is meaningful. The word fato means “fate”. But if I take that alveolar stop and make it long, the word fatto means a “fact”. The difference in the length of the stop makes [fatɔ] and [fatːɔ] two different words. (N.B., In the video there’s an error in how these two words are transcribed; it should be with the [a] vowel, not the [æ] vowel.)
So here’s the pattern that we’re observing. Sounds can vary; they can be different from each other. Some variation is meaningful within the grammar of a given language, and some variation is not.
Until now, we’ve been concentrating on phonetics: how sounds are made and what they sound like. We’re now starting to think about phonology, which looks at how sounds are organized within the mental grammar of each language: which phonetic differences are meaningful, which are predictable, which ones are possible and which ones are impossible within each language. The core principle in phonology is the idea of contrast. Say we have two sounds that are different from each other. If the difference between those two sounds leads to a difference in meaning in a given language, then we say that those two sounds contrast in that language.
So for example, the difference between fan and van is a phonetic difference in voicing. That phonetic difference leads to a substantial difference in meaning in English, so we say that /f/ and /v/ are contrastive in English. And if two sounds are contrastive in a given language, then those two sounds are considered two different phonemes in that language.
So here’s a new term in linguistics. What is a phoneme? A phoneme is something that exists in your mind. It’s a mental category, into which your mind groups sounds that are phonetically similar and gives them all the same label. That mental category contains memories of every time you’ve heard a given sound and labelled it as a member of that category. You could think of a phoneme like a shopping bag in your mind. Every time you hear the segment [f], your mental grammar categorizes it by putting it in bag labelled /f/. /v/ contrasts with /f/ — it’s a different phoneme, so every time you hear that [v], your mind puts it in a different bag, one labelled /v/.
If we look inside that shopping bag, inside the mental category, we might find some phonetic variation. But if the variation is not meaningful, not contrastive, our mental grammar does not treat those different segments as different phonemes. In English, we have a phonemic category for /l/, so whenever we hear the segment [l] we store it in our memory as that phoneme. But voiceless [l̥] is not contrastive: it doesn’t change the meaning of a word, so when we hear voiceless [l̥] we also put it in the same category in our mind. And when we hear a syllabic [l̩], that’s not contrastive either, so we put that in the same category. All of those [l]s are a little different from each other, phonetically, but those phonetic differences are not contrastive because they don’t lead to a change in meaning, so all of those [l]s are members of a single phoneme category in English.
Now, as a linguist, I can tell you that voiceless [f] and voiced [v] are two different phonemes in English, while voiceless [l̥] and voiced [l] are both different members of the same phoneme category in English. But as part of your developing skills in linguistics, you want to be able to figure these things out for yourself. Our question now is, how can we tell if two phonetically different sounds are phonemically contrastive? What evidence would we need? Remember that mental grammar is in the mind — we can’t observe it directly. So what evidence would we want to observe in the language that will allow us to draw conclusions about the mental grammar?
If we observe that a difference between two sounds — a phonetic difference — also leads to a difference in meaning, then we can conclude that the phonetic difference is also a phonemic difference in that language. So our question really is, how do we find differences in meaning?
What we do is look for a minimal pair. We want to find two words that are identical in every way except for the two segments that we’re considering. So the two words are minimally different: the only phonetic difference between them is the difference that we’re interested in. If we can find such a pair, where the minimal phonetic difference leads to a difference in meaning, it’s contrastive, then we can conclude that the phonetic difference between them is a phonemic difference.
We’ve already seen one example of a minimal pair: fan and van are identical in every way except for the first segment. The phonetic difference between [f] and [v] is contrastive; it changes the meaning of the word, so we conclude that /f/ and /v/ are two different phonemes. Can you think of other minimal pairs that give evidence for the phonemic contrast between /f/ and /v/? Take a minute, pause the video, and try to think of some.
Here are some more minimal pairs that I thought of for /f/ and /v/: vine and fine, veal and feel. Minimal pairs don’t have to have the segments that we’re considering at the beginning of the word. Here are some pairs that contrast at the end of the word: have and half, serve and surf. Or the contrast can occur in the middle of the word, like in reviews and refuse. What’s important is that the two words are minimally different: they are the same in all their segments except for the two that we’re considering. And it’s also important to notice that the minimal difference is in the IPA transcription of the word, not in its spelling.
So we’ve got plenty of evidence from all these minimal pairs in English that the phonetic difference between /f/ and /v/ leads to a meaning difference in English, so we can conclude that, in English, /f/ and /v/ are two different phonemes.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=86
1. Remember that in English, voiceless stops are aspirated at the beginning of a word and the beginning of a stressed syllable, but never in the middle of a word nor at the end of a word. Which term best describes this pattern?
2. The symbol [l̴] represents a velarized [l]. Looking at the following set of transcribed English words, what can you conclude about [l] and [l̴] in English?
leaf [lif] fall [fɑl̴]
luck [lʌk] spill [spɪl̴]
lemon [lɛmən] wolf [wʊl̴f]
3. Remembering that the alveolar flap [ɾ] appears in a predictable environment in English (see Section 3.9), which statement is true for English?
In our last unit, we learned about the notion of a phoneme. Remember that a phoneme is something that exists in your mind: it’s like a shopping bag in which your mind stores memories of examples of phonetically similar sounds that are all members of one category. Not all the sounds that you store in one phoneme category have to be identical; in fact, your mental category has room for a lot of variation. Any variants that are not contrastive, that don’t lead to a meaning change, are members of that same phoneme category and are called allophones.
We’ve already seen some examples of allophones of English phonemes as we’ve been learning to transcribe sounds. We know that the alveolar lateral approximant [l] has a voiceless variant [l̥] and a syllabic variant [l̩], but our minds categorize all of them as members of the same phoneme. This shopping-bag metaphor is going to get a little unwieldy, so let’s look at another notation that we can use to represent this phoneme category.
We say that /l/ is the label for the phoneme category itself, it’s the most general form of the phoneme. Notice that instead of using square brackets, for the symbol that represents the whole category we use slashes. In any given word, the phoneme /l/ might get spoken as any one of its allophones, each of which gets represented in square brackets. But where does each allophone appear? Which allophones do we use in which words? One of the big things that phonology is concerned with is the distribution of allophones: that is, what phonetic environments each allophone appears in. The distribution of allophones is a key part of the mental grammar of each language — it’s something that all speakers know unconsciously.
Some allophones appear in free variation, which means that it’s pretty much random which variant appears in any environment. But most allophones are entirely predictable: linguists say that allophonic variation is phonetically conditioned because it depends on what other sounds are nearby within the word.
Let’s start by looking at free variation because it’s the simpler case. Take our phoneme /l/, as in the words lucky and lunch. Most of the time you pronounce these words with a plain old ordinary voiced alveolar lateral approximant. But sometimes you might be speaking extra clearly — maybe you’re trying to talk to a relative who’s hard of hearing, or maybe you’re concentrating on teaching some speech sounds to a language learner. So instead of making the /l/ sound at the alveolar ridge, you stick your tongue right out between your teeth and say lucky or lunch. Now you’re making a dental [l̪], not an alveolar [l], but it’s still a member of the phoneme category for /l/ — it doesn’t change the meaning of the word so this phonetic difference is not contrastive. It’s just free variation within the category.
But most allophonic variation is predictable: different allophones show up in different environments. Let’s look at a few words. If we look at this set of words: plow, clap, clear, play, we can see that whenever /l/ follows a [p] or [k], it is devoiced. But now look at this other set of words (blue, gleam, leaf, fall, silly), when /l/ appears in any other environment, like following a voiced stop, or at the beginning of a word, at the end of a word, or in the middle of a word, it’s the ordinary [l]. If we looked at a whole lot more words and recorded a lot of English speakers, we’d find that whenever /l/ is in a consonant cluster following a voiceless aspirated stop, it also becomes voiceless, but when /l/ is in other environments, it stays voiced. We never find voiceless [l̥] in other environments, and we almost never find voiced [l] following a voiceless stop. That pattern is called complementary distribution.
That’s an important phrase, and it’s going to come up a lot in the next few units. It means that there’s no overlap in where we find the allophones: We see voiceless [l̥] following voiceless stops, but never anywhere else, and we never see voiced [l] in that environment. Likewise, we see voiced [l] in lots of different environments, but we never see voiceless [l̥] in any of those places. When we see complementary distribution, that’s good evidence that the two segments we’re considering are allophones of one phoneme. Can you think of any other examples of English phonetic segments that are in complementary distribution? Think about what happens when you’re transcribing voiceless stops.
So let’s sum up. If we have two phonetic segments that are related but different from each other, and we find some minimal pairs to show that this phonetic difference is contrastive, then we conclude that those two segments are two different phonemes.
And if we have two phonetic segments that are related but different, and they’re not contrastive, then we look to see what the distribution of these segments is, that is, what environments we see them in. If they’re not contrastive and they’re in complementary distribution, then we conclude that they’re allophones of the same phoneme.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=88
1. Which feature distinguishes the segments [w] and [o]?
2. Which feature distinguishes the segments [p] and [f]?
3. Which feature distinguishes the segments [p] and [b]?
In our thinking about speech sounds so far, we’ve focused almost entirely on segments. Segments are the individual speech sounds, each of which gets transcribed with an individual symbol in the IPA. We’ve seen that any given segment can influence the segments that come before and after it, through coarticulation and other articulatory processes. And we’ve also seen that segments can be grouped together into syllables, which we look at in more detail in another unit. Within the grammar of any language, two different segments might contrast with each other or might not.
So we’ve been talking as if segments are the smallest unit in speech, but in fact, each speech segment is made up of smaller components called features. Each feature is an element of a sound that we can control independently. To see how features work, let’s look at a couple of examples. We can describe the segment [b], for example, as being made up of this set of features. First, [b] is a consonant (meaning it has some obstruction in the vocal tract), so it gets the feature consonant indicated with a plus sign to show that the consonant feature is present. Looking at the next feature, sonorant, notice that it’s indicated with a minus sign, meaning that [b] is not a sonorant. The feature sonorant, of course, has to do with sonority. We know that stops have very low sonority because the vocal tract is completely closed for stops, so stops are all coded as [-sonorant]. The next feature, syllabic, tells us whether a given segment is the nucleus of a syllable or not. Remember that the most common segments that serve as the nucleus of a syllable are vowels, but stops certainly cannot be the nucleus, so /b/ gets labelled as [-syllabic]. These first three features, consonant, sonorant, and syllabic allow us to group all speech segments into the major classes of consonants, vowels, and glides. We’ll see how in a couple of minutes.
This next set of features has to do with the manner of articulation. The feature continuant tells us how long a sound goes on. Stops are very short sounds; they last for only a brief moment, so [b] gets a minus sign for continuant. We also know that [b] is not made by passing air through the nasal cavity, so it also gets a minus sign for the feature nasal. And [b] is a voiced sound, made with vocal folds vibrating, so it is [+voice].
The last feature we list for [b] is [LABIAL] because it’s made with the lips. (Stay tuned for an explanation of why some features are listed in lower-case and some in upper-case.)
This whole list of features is called a feature matrix; it’s the list of the individual features that describe the segment [b], in quite a lot of detail! Because features are at the phonetic level of representation, we use square brackets when we list them. You often see a feature matrix listed with a large pair of square brackets, like this, but we’ll just use individual square brackets on each feature.
Now I want you to notice something. If we take this whole feature matrix and change the value of just one feature, changing the feature voice from plus to minus, now we’re describing a different segment, [p]: [p] has every feature in common with [b] except for voicing. Likewise, if we take the feature matrix for [b] and change the value of the feature continuant from minus to plus, now we’re describing the segment [v], which has all the same features as [b] except that it can continue for a long time because it’s a fricative. Or if we take the feature matrix for [b] and change the feature nasal from minus to plus, this has the effect of also changing the sonorant feature to plus as well, because circulating air through the nasal cavity adds sonority. Now, this feature matrix describes the properties of the segment [m].
So each feature is something that we can control independently of the others with our articulators. And changing just one feature is enough to change the properties of a segment. That change might lead to a phonemic contrast within the mental grammar of a language, or it might just result in an allophone of the same phoneme.
It turns out that segments that have a lot of features in common tend to behave the same way within the mental grammar of a language. And we can use these features to group segments into natural classes that capture some of these similarities in their behaviour.
Let’s look again at the feature matrix for /b/. If we take away the feature that describes its place of articulation, we end up with a smaller list of features. This smaller list describes not just a single segment, but a class of segments: all the voiced stops. By not mentioning the place feature, we’ve allowed this matrix to include segments from any place of articulation, as long as they share all these other features. These three segments have all these features in common: they’re a natural class. If we remove another feature, the voicing feature, the natural class gets bigger: now we’ve got a feature matrix that describes all the stops in English, including those that are [+voice] and those that are [-voice]. So you can see that this system of features is very powerful for describing classes of segments that have things in common. We’ll learn more about natural classes in the next unit.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=90
1. In the set of segments listed below, which segment must be excluded to make the remaining segments constitute a natural class?
2. In the following set of segments, which segment must be excluded to make the remaining segments constitute a natural class?
3. This set of segments constitutes a natural class: [i ɛ æ]. Which segment could you add to the set while still preserving the natural class?
We saw in the last unit that a natural class is a group of speech segments that have some features in common. Because they share features, they also tend to behave similarly to each other in the grammar of a language. We also learned how to use the notation of a feature matrix to describe the features that the members of a natural class have in common. Remember that the more features we list, the smaller the natural class gets, and the fewer features we list, the larger the class we’re describing.
The two largest natural classes can be described with just one feature! All segments that have an obstruction in the vocal tract are [+consonant], and the vowels, which have no obstruction in the vocal tract, are [-consonant]. Notice that the feature consonant is binary, meaning it has exactly two values: plus or minus. This means that we don’t need a separate feature to label the sounds that are vowels: using the binary feature notation we can just say that consonants are [+consonant] and all vowels are [-consonant].
Now, why did I say that most consonants are [+consonant]? Could there be consonants that aren’t totally consonants? Think back to when we first started learning to categorize sounds. Remember we said the glides /j/ and /w/ have very little obstruction in the vocal tract. So even though /j/ and /w/ often behave like consonants, they get labelled as [-consonant] in the feature system. This is how we indicate that also they share some properties with vowels, namely, the properties of having the vocal tract unobstructed.
The next feature that groups segments into the major classes has to do with sonority, or acoustic energy. Because of the relatively open vocal tract, all vowels are [+sonorant]. But not all consonants are [-sonorant]. Approximants also have a relatively open vocal tract, so all glides and liquids are also [+sonorant]. And when air circulates through the nasal cavity, that also creates a lot of acoustic energy so all the nasal consonants are also [+sonorant]. All other sounds, that is, stops, fricatives, affricates, and so on, are minus sonorant because they have lower sonority. Informally, we call the non-sonorant class of sounds obstruents, but we don’t need a separate feature label for obstruents because of how the binary feature system works: we just identify them as [-sonorant].
The third major feature groups sounds according to whether they can be the nucleus of a syllable or not. There’s a lot of overlap between sounds that are [+sonorant] and [+syllabic], but the two classes aren’t totally identical. I’m sure you can already guess that all vowels have the feature [+syllabic]. By default, all consonants are [-syllabic], but remember that some consonants can sometimes serve as the nucleus of a syllable — do you remember which ones? The liquids and nasals become [+syllabic] only when they’re the nucleus of a syllable.
These three features are called the major class features because they allow us to group segments into these broad categories. At one end of the spectrum, we have the vowels, with no obstruction in the vocal tract, so they’re sonorant, and they can serve as the nucleus of a syllable. At the other end, we have the obstruents: these are the consonants that have low sonority and can’t be the nucleus of a syllable. And then in between, we have the sonorant consonants, which are usually [-syllabic] but can become [+syllabic], so if we don’t list that feature, we indicate that it can be either plus or minus. And then there are the glides, which are almost like vowels except they’re [-syllabic]. There are a few details to notice here: the nasals and liquids are consonants that are sonorant, and that can become syllabic. The glides are sonorants, but they don’t serve as the nucleus of a syllable, and they don’t even count as consonants!
The next set of features we should consider are those that describe manners of articulation. The continuant feature has to do with whether air is allowed to flow in the oral cavity (that is, in the mouth). So the main job the continuant feature does is to distinguish between the stops, which are [-continuant] because airflow is blocked, and all other sounds. Notice that the nasals count as [-continuant] along with the plosive stops because they involve a complete closure in the mouth.
Speaking of nasals, the feature [+nasal] labels nasal sounds. /m n ŋ/ are obviously [+nasal], and in English, all other sounds are [-nasal] by default. But sometimes assimilation leads a vowel to take on a nasal feature. In the word pants, for example, the [æ] vowel becomes nasalized in anticipation of the following nasal sound, which we would label as a change from [-nasal] to [+nasal].
The voice feature is pretty obvious: if the vocal folds are vibrating, then a segment is [+voice]. So all the voiced consonants are [+voice] and the voiceless consonants are [-voice]. In English, the vocal folds vibrate for vowels, so the vowels are also [+voice].
Now let’s look at the features that describe which articulators are active in producing a sound. Notice that the notation for the place features is different: these ones are not binary features so there’s no plus or minus, and they’re written in all capital letters to distinguish them from the binary features. The idea is that there’s no known language that makes meaningful phonological distinctions on the basis of what a sound’s place of articulation is NOT, so we don’t need a minus-value for these features. The feature [LABIAL] identifies any sound that involves the lips. [CORONAL] classifies sounds that are produced using the tip of the tongue, and [DORSAL] classifies sounds that are produced with the body and back of the tongue.
Let’s start by looking at labial sounds. If a sound doesn’t involve the lips at all, then we don’t even list [LABIAL] in its feature matrix. But if it does involve the lips, then we specify whether the lips are [+round], like the rounded vowels and the glide [w], or [-round], like for the bilabial and labio-dental consonants.
We label sounds that are made with the tip of the tongue with the feature [CORONAL], and then we can classify them further according to where the tip is. The word anterior is just a fancy word for “front”. The dental and alveolar sounds are made with the tip of the tongue towards the front of the mouth and are [+anterior]. Post-alveolar sounds have the tip of the tongue pointing farther back so they’re [-anterior]. There’s another distinction for the coronal sounds. We use the label [+strident] for the sounds that are acoustically noisy and sound like hissing, that is, [s z ʃ ʒ tʃ dʒ]. The other coronals are [-strident]. You’ll see why this distinction matters in one of the exercises at the end of this chapter.
Sounds that are made not with the tip of the tongue but with the tongue body have the feature [DORSAL]. Only a few consonants in English have the feature [DORSAL]: the velar sounds [k ɡ ŋ] and the glides [j w]. And because the body of the tongue is the primary articulator that we use to make different vowel sounds, all vowels have the feature [DORSAL].
Once we’ve identified a sound as a dorsal sound, then we use binary features to specify the position of the tongue body. We specify vowel height with the features [±high] and [±low]. All high sounds are [-low], and all low sounds are [-high], but there are also vowels that are both [-low] and [-high]: the mid vowels! We identify the front or back position of the tongue with [±back], but we don’t need to include a [±front] feature because these central vowels pattern with the natural class of back vowels.
There’s one other feature we need for categorizing the vowels of English, and that’s the tense/lax distinction. We label the tense vowels as [+tense] and the lax vowels as [-tense].
There’s a full chart of features for the segments of English presented below, but don’t be intimidated by it. A feature matrix is just a more organized way of presenting the information that you already learned about phonetic segments. If you start to think of segments in terms of natural classes and what features the natural class has, you’ll start to get the hang of it.
| p | b | t | d | k | ɡ | f | v | s | z | θ | ð | ʃ | ʒ | m | n | ŋ | l | ɹ | j | w | |
| Major Class Features | |||||||||||||||||||||
| [consonant] | + | + | + | + | + | + | + | + | + | + | + | + | + | + | + | + | + | + | + | – | – |
| [sonorant] | – | – | – | – | – | – | – | – | – | – | – | – | – | – | + | + | + | + | + | + | + |
| [syllabic] | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – |
| Manner Features | |||||||||||||||||||||
| [nasal] | – | – | – | – | – | – | – | – | – | – | – | – | – | – | + | + | + | – | – | – | – |
| [continuant] | – | – | – | – | – | – | + | + | + | + | + | + | + | + | – | – | – | + | + | + | + |
| [lateral] | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | + | – | – | – |
| [voice] | – | + | – | + | – | + | – | + | – | + | – | + | – | + | + | + | + | + | + | + | + |
| Place Features | |||||||||||||||||||||
| LABIAL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||
| [round] | – | – | – | – | – | + | |||||||||||||||
| CORONAL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [anterior] | + | + | + | + | + | + | – | – | + | + | + | ||||||||||
| [strident] | – | – | + | + | – | – | + | + | – | – | – | ||||||||||
| DORSAL | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||
| [high] | + | + | + | + | + | ||||||||||||||||
| [back] | + | + | + | – | + | ||||||||||||||||
| i | ɪ | e | ɛ | æ | u | ʊ | o | ʌ | ɔ | ɑ | |
| Major Class Features | |||||||||||
| [consonant] | – | – | – | – | – | – | – | – | – | – | – |
| [sonorant] | + | + | + | + | + | + | + | + | + | + | + |
| [syllabic] | + | + | + | + | + | + | + | + | + | + | + |
| Manner Features | |||||||||||
| [continuant] | + | + | + | + | + | + | + | + | + | + | + |
| [voice] | + | + | + | + | + | + | + | + | + | + | + |
| Place Features | |||||||||||
| LABIAL | ✓ | ✓ | ✓ | ✓ | |||||||
| [round] | + | + | + | + | |||||||
| DORSAL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| [high] | + | + | – | – | – | + | + | – | – | – | – |
| [low] | – | – | – | – | + | – | – | – | – | – | + |
| [back] | – | – | – | – | – | + | + | + | + | + | + |
| [tense] | + | – | + | – | – | + | – | + | – | – | + |

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=96
1. Which phonological rule accurately represents the process, “vowels become nasalized before a nasal consonant”?
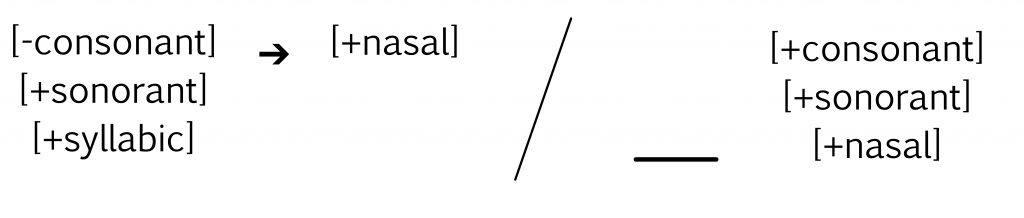
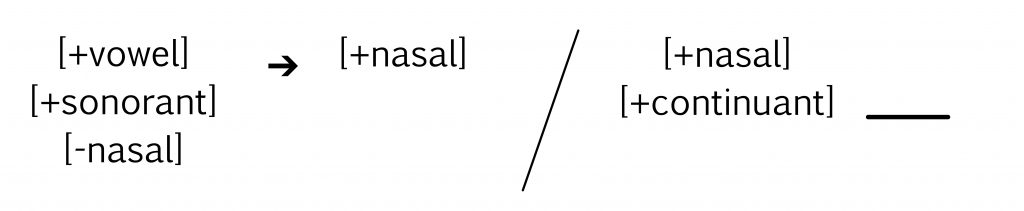
2. Which sentence accurately describes the process depicted in this phonological rule?

3. Which sentence accurately describes the process depicted in this phonological rule?

Earlier in this chapter, we talked about the difference between phonemic and phonetic representations. Remember that when we talk about a phonemic representation, we’re referring to how a sound or a word is represented in our mind. At the phonemic level, the mind stores segmental information, but not details about allophonic variation. But the phonetic representation is how we actually speak words, and because of coarticulation and various articulatory processes, when we speak a given phoneme, it gets produced as the particular allophone that’s conditioned by the surrounding environment. For example, the word clean is represented phonemically like this /klin/ in our minds but when we speak, these particular phonetic details [khl̥in] are part of what we say. We speak in allophones but we hear in phonemes.
The systematic, predictable relationship between the phonemic and phonetic representations is part of the mental grammar of every fluent speaker of a language. Phonologists have developed a notation for depicting this relationship, which is sometimes known as a derivation or a rule. Remember of course that when we talk about rules in linguistics, we don’t mean those prescriptive rules that your high school English teacher wanted you to follow. We mean the principles that our mental grammar uses to link the underlying phonemic representation to the surface form. Our mental grammar keeps track of every predictable phonetic change that happens to a given natural class of sounds in a given phonetic environment.
Let’s think about that now familiar process of liquid devoicing. We’ve seen lots of English examples like clean where the voiced [l] becomes voiceless following the voiceless [kh] because of perseveratory assimilation. In fact, we’ve seen enough data from English to observe that this doesn’t just happen to one segment; it happens to the natural class of liquids in the environment of another natural class: voiceless stops.
The way that we write a derivation takes a particular form that looks like this. This notation is read as “A becomes B in the environment between X and Y”. The left side represents the phonetic change that happens: a particular phoneme or natural class of phonemes becomes a given allophone or undergoes a change to one or more features. The right-hand side shows the phonetic environment that the change occurs in.
So how would we use this notation to represent the predictable process of liquid devoicing? Let’s start by describing the pattern in words. The change happens to the liquids [l] and [ɹ]. What happens to them is that they go from voiced to voiceless. And where it happens is following voiceless stops. So now let’s describe the pattern using a feature matrix.
We start with the feature matrix for the liquids. They’re consonants that are sonorant but not nasal and by default, they’re [+voice]. The change that happens is that their voice feature goes from plus to minus. The other features stay the same so we don’t list them in the feature matrix that describes the change.
Now we have to say where this change happens. The big slash just means “in the environment” and we know that this change happens following something, so we put the horizontal line that indicates the location of the change following the feature matrix that represents the environment and then we fill in the details of the particular environment. Voiceless stops are consonants that are [-continuant] and [-voice].
We could say that [l] becomes voiceless [l] in the environment following [p] or [k] and [ɹ] becomes voiceless [ɹ] in the environment following [p] or [t] or [k] but using feature matrices captures the broader generalization that this allophonic variation happens to an entire natural class in the environment of another natural class.
Exercises 3 and 4 are adapted from How Language Works available here.
© 2006. Indiana University and Michael Gasser.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation. )
Exercise 1. In some varieties of English, mostly spoken in the Midwestern U.S.A., the vowel in the first, unstressed syllable of the word is deleted in words like police, believe, parade, pollution, terrific, collision, but is not deleted in words like detective, dependent, majestic, pedantic. Answer the following questions about the natural class of sounds that follow the deleted vowel.
Exercise 2. Here is a set of data transcribed from German. Examine the data and pay attention to these three segments:
[ç] (voiceless palatal fricative)
[ʃ] (voiceless post-alveolar fricative)
[x] (a voiceless velar fricative)
You may also wish to know the following:
[ø] is a mid-high, front, rounded tense vowel
[y] is a high, front, rounded tense vowel
| [ɪç] | I | [byʃə] | bushes | [bux] | book |
| [manç] | some | [tuʃə] | ink | [dɑx] | roof |
| [durç] | through | [nɑʃən] | nibble | [nɑxən] | small boat |
| [tøçtər] | daughters | [kɪrʃə] | cherry | [nɔx] | still, yet |
| [meːdçən] | girl | [fɪʃtə] | fished | [tux] | scarf |
| [kɪrçə] | church | [mɛnʃən] | people | [kuxən] | cake |
| [fɪçtə] | pine | [ʃpiːlən] | to play | [ɑxɑːt] | agate |
| [mɛnçən] | little man | [ʃtɑːt] | state | [lɑxst] | (you) laugh |
Exercise 3. The Japanese phoneme /s/ has two allophones: [s] and [ʃ]. Examine the following dataset, and then describe in words what environments each allophone appears in.
| [saja] pod | [heso] navel | [ʃite] doing |
| [kasa] umbrella | [suʃi] sushi | [kuʃi] skewer |
| [senkjo] election | [hanasu] speak | [saʃimi] sashimi |
| [mise] store | [ʃiku] spread | [meʃi] rice |
| [sono] that | [ʃima] island | [sasemaʃita] caused |
Exercise 4. In Modern English, as you know, the fricatives [f, v, θ, ð, s, z] are six different phonemes. But in Old English, these six segments were categorized as only three different phonemes, each with a voiced and a voiceless allophone, [f, v], [θ, ð], [s, z]. The following words from Old English show the distribution of these segments.
| [fæder] | father | [iːzern] | iron |
| [l̥ɑːf] | bread | [wrɑθ] | angry |
| [fæðm] | fathom | [kweðɑn] | to say |
| [stɑvɑs] | letters | [eorðe] | earth |
| [smiθ] | blacksmith | [yvele] | evil |
| [ræːzɑn] | to attack | [heovon] | sky |
| [θɑːx] | thrived | [furðor] | further |
| [æːvre] | always | [ræːzde] | attacked |
You’ve now seen that the mental grammar of every language organizes speech sounds differently. A pair of sounds that contrast with each other in one language might be allophones of the same phoneme in another language. Even without knowing another language, you can now use the tools that linguists use to analyze phonological data from a language: you can look for minimal pairs to find evidence of phonemic contrast, or you can analyze environments and identify complementary distribution to find evidence of allophonic variation.
Many processes of allophonic variation in the world’s languages apply not just to pairs of segments, but to natural classes of sounds. The notation of feature matrices helps to identify the natural classes that undergo allophonic variation, and the natural classes of environments that lead to (or “condition”) this variation.
This chapter illustrates how the phonological component of mental grammar develops in a language learner, whether in an infant learning their first language, or an adult learning a second, third, or later language.
When you’ve completed this chapter, you will be able to:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=104
1. The phonology of Thai contains a three-way contrast between voiced /b/, voiceless /p/, and aspirated /ph/. How likely is it that a six-month-old baby growing up in an English-speaking household would be able to hear the difference between Thai [p] and [ph]?
2. Arabic phonology includes a contrast between uvular and pharyngeal fricatives. How likely is it that a two-year-old growing up in an English-speaking household would be able to hear the difference between these two places of articulation?
3. In the various dialects of Chinese, there is no phonemic contrast between tense and lax vowels. How likely is it that a four-month-old baby growing up in a Mandarin Chinese-speaking household would be able to hear the contrast between English [e] and [ɛ]?
So far we’ve been focusing primarily on English, but it’s important to remember that the phonology of each language is specific to that language: the patterns of which features and segments contrast with each other and which are simply allophones is different in each language of the world. So, for example, we know that in English, aspirated [ph] and unaspirated [p] are both allophones of a single phoneme. But in Thai, these two segments contrast with each other and are two different phonemes. The phonetic difference is the same, but how that difference is organized in the mental grammar is different in the two languages. This has effects when adults are trying to learn a second language.
Now, it’s a stereotype that people who are native speakers of Japanese often have difficulty when they’re learning some sounds of English, particularly in learning the difference between English /ɹ/ and /l/. These two sounds are contrastive in English, and we have lots of minimal pairs that provide evidence for that contrast, like rake and lake, fall and far, cram and clam. But neither of these segments is part of the Japanese phoneme inventory. Japanese has one phoneme, the retroflex flap [ɽ], that is phonetically a little bit similar to English /l/ and a little bit similar to English /ɹ/. So given that English /ɹ/ and /l/ are both phonetically different to the Japanese /ɽ/, and are phonetically different from each other, why is this phonemic contrast hard for Japanese learners to master?
 To answer this question, we have to look at babies. Babies learn the phonology of their native language very early. When they are just born, we know that babies can recognize all kinds of phonetic differences. You might be wondering how we can tell what sounds a baby can recognize — we can’t just ask them, “Are these two sounds the same or different?” But we can use a habituation technique to observe whether they notice a difference or not. Babies can’t do much, but one thing they’re very good at is sucking. Using an instrument called a pressure transducer, which is connected to a pacifier, we can measure how powerfully they suck. When a baby is interested in something, like a sound that she’s hearing, she starts to suck harder. If you keep playing that same sound, eventually she’ll get bored and her sucking strength will decrease. When her sucking strength drops off, we say that the baby has habituated to the sound. But if you play a new sound, she gets interested again and starts sucking powerfully again. So we can observe if a baby notices the difference between two sounds by observing whether her sucking strength increases when you switch from one sound to the other. For newborn infants, we observe habituation with sucking strength, and for babies who are a little older, we can observe habituation just by where they look: they’ll look toward a source of sound when they’re interested in it, then look away when they get habituated. If they notice a change in the sound, they’ll look back toward the sound.
To answer this question, we have to look at babies. Babies learn the phonology of their native language very early. When they are just born, we know that babies can recognize all kinds of phonetic differences. You might be wondering how we can tell what sounds a baby can recognize — we can’t just ask them, “Are these two sounds the same or different?” But we can use a habituation technique to observe whether they notice a difference or not. Babies can’t do much, but one thing they’re very good at is sucking. Using an instrument called a pressure transducer, which is connected to a pacifier, we can measure how powerfully they suck. When a baby is interested in something, like a sound that she’s hearing, she starts to suck harder. If you keep playing that same sound, eventually she’ll get bored and her sucking strength will decrease. When her sucking strength drops off, we say that the baby has habituated to the sound. But if you play a new sound, she gets interested again and starts sucking powerfully again. So we can observe if a baby notices the difference between two sounds by observing whether her sucking strength increases when you switch from one sound to the other. For newborn infants, we observe habituation with sucking strength, and for babies who are a little older, we can observe habituation just by where they look: they’ll look toward a source of sound when they’re interested in it, then look away when they get habituated. If they notice a change in the sound, they’ll look back toward the sound.
Using this technique, linguists and psychologists have learned that babies are very good at noticing phonetic differences, and they can tell the difference between all kinds of different sounds from many different languages. But this ability changes within the first year of life. A researcher named Janet Werker at the University of British Columbia looked at children and adults’ ability to notice the phonetic difference between three different pairs of syllables: the English contrast /ba/ and /da/, the Hindi contrast between a retroflex stop /ʈa/ and a dental stop /t̪a/, and a Salish contrast between glottalized velar /kʼi/ and uvular /qʼi/ stops. Each of these pairs differs in place of articulation, and within each language, each pair is contrastive. Werker played a series of syllables and asked English-speaking adults to press a button when the syllables switched from one segment to the other. As you might expect, the English-speaking adults were perfect at the English contrast but did extremely poorly on the Hindi and Salish contrasts.
Then Werker tested babies’ ability to notice these three phonetic differences, using the head-turn paradigm. These babies were growing up in monolingual English-speaking homes. At age six months, the English-learning babies were about 80-90% successful at noticing the differences in English, in Hindi and in Salish. But by age ten months, their success rate had dropped to about 50-60%, and by the time they were one year old, they were only about 10-20% successful at hearing the phonetic differences in Hindi and Salish. So these kids are only one year old, they’ve been hearing English spoken for only one year, and they’re not even really speaking it themselves yet, but already their performance on this task is matching that of English-speaking adults. The difference between retroflex [ʈa] and dental [t̪a] is not contrastive in English, so the mental grammar of the English-learning baby has already categorized both those sounds as just unusual-sounding allophones of English alveolar /ta/. Likewise, the difference between a velar and a uvular stop, which is contrastive in Salish, is not meaningful in English, so the baby’s mind has already learned to treat a uvular stop as an allophone of the velar stop, not as a separate phoneme.
So if we go back to our question of why it’s so hard for adults to learn the phonemic contrast in a new language, like the Japanese learners who have difficulty with English /l/ and /ɹ/, the answer is because, by the time they’re one year old, the mental grammar of Japanese-learning babies has already formed a single phoneme category that contains English /l/ and /ɹ/ as allophones of that one phoneme. To recognize the contrast in English, a Japanese learner has to develop two separate phoneme categories.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=106
1. In Canadian French, the front tense vowels [y] and [i] become the lax vowels [ʏ] and [ɪ] in certain environments. Is it likely to be easy or difficult for a native speaker of Canadian French to learn the English contrast between /i/ and /ɪ/ (as in sleep and slip)?
2. Arabic includes a contrast between a voiceless velar fricative [x] and a voiced velar fricative [ɣ]. Is this contrast likely to be easy or difficult for native speakers of English to learn?
3. In Cree, voiceless stops become voiced between vowels. Given that Cree has both voiced and voiceless stops in its phonetic inventory, is it likely to be easy or difficult for a native speaker of Cree to learn the phonemic contrast between /b/ and /p/ in English?
In the last unit, we learned that babies have set up the phoneme categories of their native language by the time they’re only twelve months old. This is part of the reason that it can be challenging to learn a new language as an adult. A psycholinguist by the name of Catherine Best has proposed a theory to predict which phoneme contrasts will be hard for second-language learners to learn, and which will be easy. For simplicity, let’s use the term L1 for your native language, the language you learn from infancy. And an L2 is any language you learn later than that, as an older child, a teenager, or an adult. Best’s theory of L2 learning centres around the concepts of phonemes and allophones.
Best predicts that there are two kinds of phoneme contrasts that are easy to learn in an L2. If the L2 has a phoneme contrast that maps onto a phoneme contrast in the learner’s L1, then that contrast should be easy to learn in the L2. She also predicts that if the L2 has a phoneme contrast that’s completely new, with two segments that don’t exist at all in the learner’s L1, then this contrast should be easy as well because the learner can set up two new phoneme categories from scratch.
The kind of phoneme contrast that’s hard to learn is when two contrasting phonemes in the L2 map onto a single phoneme category in the learner’s L1. In this case, the learner will have spent a lifetime treating the phonetic difference as allophonic variation, and not a meaningful contrast, so it’s a challenge to learn to pay attention to the difference as meaningful.
Catherine Best and her colleagues have tested this theory by investigating how English-speaking adults learn phonemic contrasts in Zulu. Zulu is a language that has about 27 million speakers, most of them in South Africa. First, researchers asked the English-speakers to tell the difference between voiced and voiceless lateral fricatives in Zulu. English doesn’t have lateral fricatives, but English does have lots of pairs of fricatives that contrast in their voicing, so the theory predicts that it should be easy for English listeners to map the voicing difference between the Zulu fricatives onto those English voicing contrasts and recognize this phonetic difference. And that prediction was upheld: The English listeners were about 95% correct.
Then they asked the English speakers to tell the difference between three Zulu clicks: a dental, an alveolar, and a palato-alveolar click. English doesn’t have any clicks at all, so the English listeners should be able to simply pay attention to the phonetic differences between these segments, without any interference from their English phonology. The English listeners were about 80% correct at these sounds.
Last, they asked the English listeners to tell the difference between two different kinds of bilabial stops in Zulu: the plosive stop is similar to the English /b/ sound. The other is an implosive /ɓ/, which is made by obstructing airflow at the lips, but when the stop is released, air flows into the mouth instead of out of the mouth. The English adults were only about 65% correct at hearing this difference, not a whole lot better than chance. This is consistent with Best’s proposal that because the English listeners have only one phoneme category for voiced bilabial stops, their mental grammar simply treats the implosive as an allophone of that phoneme. So it’s very hard to hear the phonetic difference between the two sounds in the L2 because the mental grammar of the L1 considers them both members of the same phoneme category.
Exercise 1. Look back at Exercise 3 in Chapter 4. Given what you concluded about the phonology of Japanese in that exercise, predict whether it would likely be easy or difficult for an L1 speaker of Japanese to learn the English contrast between words like sip/ship, sign/shine, class/clash. Explain how you arrived at your conclusion.
Exercise 2. Look again at Exercise 2 in Chapter 4. In that exercise, you concluded that German has a phoneme [ʃ] that contrasts with another phoneme that has two allophones, [x] and [ç] (a voiceless velar fricative and voiceless palatal fricative, respectively). Given what you know about English phonology, how easy or difficult will it be for an L1 speaker of English to learn this contrast in German? Explain how you arrived at your conclusion.
You’ve now learned that infants acquire the phonemic categories of their native language very young, even before they can reliably produce sounds or words! This is one of the reasons that it can be challenging to learn another language when we’re older, because our mind has already set up phoneme categories for our native language and has learned to efficiently categorize speech sounds into these native categories. Learning a new language can involve dividing up existing categories into new ones, shifting the boundaries of our L1 categories, or creating entirely new categories for our L2.
In this chapter, we look more closely at words and at the meaningful pieces that combine to create words — morphemes. When you’ve finished this chapter, you’ll be able to:
What’s a word? It seems almost silly to ask such a simple question, but if you think about it, the question doesn’t have an obvious answer. A famous linguist named Ferdinand de Saussure said that a word is like a coin because it has two sides to it that can never be separated. One side of this metaphorical coin is the form of a word: the sounds (or letters) that combine to make the spoken or written word. The other side of the coin is the meaning of the word: the image or concept we have in our mind when we use the word. So a word is something that links a given form with a given meaning.
Linguists have also noticed that words behave in a way that other elements of mental grammar don’t because words are free. What does it mean for a word to be free? One observation that leads us to say that words are free is that they can appear in isolation, on their own. In ordinary conversation, we don’t often utter just a single word, but there are plenty of contexts in which a single word is indeed an entire utterance. Here are some examples:
What are you doing? Cooking.
What are you cooking? Soup.
How does it taste? Delicious.
Can I have some? No.
Each of those single words is perfectly grammatical standing in isolation as the answer to a question.
Another reason we say that words are free is that they’re moveable: they can occupy a whole variety of different positions in a sentence. Look at these examples:
Penny is making soup.
Soup is delicious.
I love to eat soup when it’s cold outside.
The word soup can appear as the last word in a sentence, as the first word, or in the middle of a sentence. It’s free to be moved around.
The other important observation we can make about words is that they’re inseparable: We can’t break them up by putting other pieces inside them. For example, in the sentence,
Penny cooked some carrots.
The word carrot has a bit of information added to the end of it to show that there’s more than one carrot. But that bit of information can’t go just anywhere: it can’t interrupt the word carrot:
*Penny cooked some car-s-rot.
This might seem like a trivial observation – of course, you can’t break words up into bits! – but if we look at a word that’s a little more complex than carrots we see that it’s an important insight. What about:
Penny bought two vegetable peelers.
That’s fine, but it’s totally impossible to say:
*Penny bought two vegetables peeler.
even though she probably uses the peeler to peel multiple vegetables. It’s not that a plural -s can’t go on the end of the word vegetable; it’s that the word vegetable peeler is a single word (even though we spell it with a space between the two parts of it). And because it’s a single word, it’s inseparable, so we can’t add anything else into the middle of it.
So we’ve seen that a word is a free form that has a meaning. But you’ve probably already noticed that there are other forms that have meaning and some of them seem to be smaller than whole words. A morpheme is the smallest form that has meaning. Some morphemes are free: they can appear in isolation. (This means that some words are also morphemes.) But some morphemes can only ever appear when they’re attached to something else; these are called bound morphemes.
Let’s go back to that simple sentence,
Penny cooked some carrots.
It’s quite straightforward to say that this sentence has four words in it. We can make the observations we just discussed above to check for isolation, moveability, and inseparability to provide evidence that each of Penny, cooked, some, and carrots is a word. But there are more than four units of meaning in the sentence.
Penny cook-ed some carrot-s.
The word cooked is made up of the word cook plus another small form that tells us that the cooking happened in the past. And the word carrots is made up of carrot plus a bit that tells us that there’s more than one carrot.
That little bit that’s spelled –ed (and pronounced a few different ways depending on the environment) has a consistent meaning in English: past tense. We can easily think of several other examples where that form has that meaning, like walked, baked, cleaned, kicked, kissed. This –ed unit appears consistently in this form and consistently has this meaning, but it never appears in isolation: it’s always attached at the end of a word. It’s a bound morpheme. For example, if someone tells you, “I need you to walk the dog,” it’s not grammatical to answer “-ed” to indicate that you already walked the dog.
Likewise, the bit that’s spelled –s or –es (and pronounced a few different ways) has a consistent meaning in many different words, like carrots, bananas, books, skates, cars, dishes, and many others. Like –ed, it is not free: it can’t appear in isolation. It’s a bound morpheme too.
If a word is made up of just one morpheme, like banana, swim, hungry, then we say that it’s morphologically simple, or monomorphemic.
But many words have more than one morpheme in them: they’re morphologically complex or polymorphemic. In English, polymorphemic words are usually made up of a root plus one or more affixes. The root morpheme is the single morpheme that determines the core meaning of the word. In most cases in English, the root is a morpheme that could be free. The affixes are bound morphemes. English has affixes that attach to the end of a root; these are called suffixes, like in books, teaching, happier, hopeful, singer. And English also has affixes that attach to the beginning of a word, called prefixes, like in unzip, reheat, disagree, impossible.
Some languages have bound morphemes that go into the middle of a word; these are called infixes. Here are some examples from Tagalog (a language with about 24 million speakers, most of them in the Philippines).
| [takbuh] | run | [tumakbuh] | ran |
| [lakad] | walk | [lumakad] | walked |
| [bili] | buy | [bumili] | bought |
| [kain] | eat | [kumain] | ate |
It might seem like the existence of infixes is a problem for our claim above that words are inseparable. But languages that allow infixation do so in a systematic way — the infix can’t be dropped just anywhere in the word. In Tagalog, the position of the infix depends on the organization of the syllables in the word.
The previous unit showed us that a morpheme is the smallest unit that pairs a consistent form with a consistent meaning. But when we say that the form of a morpheme is consistent, there’s still some room for variability in the form. Think back to what you know about phonology and remember that a given phoneme can show up as different allophones depending on the surrounding environment. Morphemes work the same way: a given morpheme might have more than one allomorph. Allomorphs are forms that are related to each other but slightly different, depending on the surrounding environment.
A simple example is the English word a. It means something like “one of something, but not any particular one”, like in these examples:
a book
a skirt
a friend
a phone call
But if the word following a begins with a vowel and not a consonant, then the word a changes its form:
an apple
an ice cream cone
an iguana
an idea
The two forms a and an are slightly different in their form, but they clearly both have the same meaning. And each one shows up in a different predictable environment: a before words that start with consonants and an before words that begin with vowels.
Another example of allomorphy in English is in the plural morpheme. In written English, the form of the plural morpheme is spelled -s, as in:
carrots
books
hats
friends
apples
iguanas
But it’s spelled –es in words like:
churches
bushes
quizzes
And in fact, even in the cases where it’s spelled -s, it’s pronounced as [s] for words that end in a voiceless segment (carrots, books, cliffs) and as [z] for words that end in voiced sounds (worms, dogs, birds). So it’s got two written forms (-s and -es) and three spoken forms ([s], [z], [ɨz]), but a consistent meaning of “more than one”. Each form is an allomorph of the plural morpheme. Can you figure out what the relevant environment is that predicts which allomorph appears where?

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=117
1. What type of grammatical information does the inflectional affix in the word speeches communicate?
2. What type of grammatical information does the inflectional affix in the word climbed communicate?
3. What type of grammatical information does the inflectional difference between he and him indicate?
We saw in our last units that words can be made up of morphemes, which are the smallest linguistic unit that links form with meaning. Morphemes can do a couple of quite different jobs in a word.
Inflectional morphemes are morphemes that add grammatical information to a word. When a word is inflected, it still retains its core meaning, and its category stays the same. We’ve actually already talked about several different inflectional morphemes:
The number on a noun is inflectional morphology. For most English nouns the inflectional morpheme for the plural is an –s or –es (e.g., books, cars, dishes) that gets added to the singular form of the noun, but there are also a few words with irregular plural morphemes. Some languages also have a special morpheme for the dual number, to indicate exactly two of something. Here’s an example from Manam, one of the many languages spoken in Papua New Guinea. You can see that there’s a morpheme on the noun woman that indicates dual, for exactly two women, and a different morpheme for plural, that is, more than two women.
| Manam (Papua New Guinea) | ||
| /áine ŋara/ | that woman | singular |
| /áine ŋaradiaru/ | those two women | dual |
| /áine ŋaradi/ | those women | plural |
The tense on a verb is also inflectional morphology. For many English verbs, the past tense is spelled with an –ed, (walked, cooked, climbed) but there are also many English verbs where the tense inflection is indicated with a change in the vowel of the verb (sang, wrote, ate). English does not have a bound morpheme that indicates future tense, but many languages do.
Another kind of inflectional morphology is agreement on verbs. If you’ve learned French or Spanish or Italian, you know that the suffix at the end of a verb changes depending on who the subject of the verb is. That’s agreement inflection. Here are some examples from French. You can see that there’s a different morpheme on the end of each verb depending on who’s doing the singing.
| French | ||
| 1st | je chante | I sing |
| 2d | tu chantes | you sing |
| 3d | elle chante | she sings |
| 1st | nous chantons | we sing |
| 2d | vous chantez | you (pl.) sing |
| 3d | elles chantent | they sing |
And in some languages, the morphology on a noun changes depending on the noun’s role in a sentence; this is called case inflection. Take a look at these two sentences in German: The first one, Der Junge sieht Sofia, means that, “The boy sees Sofia”. Look at the form of the phrase, the boy, “der Junge”. Now, look at this other sentence, Sofia sieht den Jungen, which means that “Sofia sees the boy”. In the first sentence, the boy is doing the seeing, but in the second, the boy is getting seen, and the word for boy, Junge has a different morpheme on it to indicate its different role in the sentence. That’s an example of case morphology, which is another kind of inflection.
| German | |
| Der Junge sieht Sofia. | The boy sees Sofia. |
| Sofia sieht den Jungen | Sofia sees the boy. |

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=119
1. Which of the following best describes the derivation of the word assignment?
2. Which of the following best describes the derivation of the word skillful?
3. Which of the following best describes the derivation of the word simplify?
The last unit talked about inflection, which is one of the jobs that morphology can do. The other big job that morphemes have is a derivation. The derivation is the process of creating a new word. The new, derived word is related to the original word, but it has some new component of meaning to it, and often it belongs to a new category.
One of the most common ways that English derives new words is by affixing a derivational morpheme to a base. For example, if we start with a verb that describes an action, like teach and we add the morpheme –er, we derive a morphologically complex noun, teacher, that refers to the person who does the action of teaching. That same -er morpheme does the same job in singer, dancer, baker, and writer.
| Verb | Suffix | Noun |
| teach | -er | teacher |
| sing | -er | singer |
| dance | -er | dancer |
| bake | -er | baker |
| write | -er | writer |
If we start with an adjective like happy and add the suffix –ness, we derive the noun that refers to the state of being that adjective, happiness.
| Verb | Suffix | Noun |
| teach | -er | teacher |
| sing | -er | singer |
| dance | -er | dancer |
| bake | -er | baker |
| write | -er | writer |
Adding the suffix –ful to a noun derives an adjective, like hopeful.
| Noun | Suffix | Adjective |
| hope | -ful | hopeful |
| joy | -ful | joyful |
| care | -ful | careful |
| dread | -ful | dreadful |
Adding the suffix–ize to an adjective like final derives a verb like finalize.
| Adjective | Suffix | Verb |
| final | -ize | finalize |
| modern | -ize | modernize |
| social | -ize | socialize |
| public | -ize | publicize |
Notice that each of the morphologically complex derived words is related in meaning to the base, but it has a new meaning of its own. English also derives new words by prefixing, and while adding a derivational prefix does lead to a new word with a new meaning, it often doesn’t lead to a category change.
| Prefix | Verb | Verb |
| re- | write | rewrite |
| re- | read | reread |
| re- | examine | reexamine |
| re- | assess | reassess |
Each instance of derivation creates a new word, and that new word could then serve as the base for another instance of derivation, so it’s possible to have words that are quite complex morphologically.
For example, say you have a machine that you use to compute things; you might call it a computer (compute + -er).Then if people start using that machine to perform a task, you could say that they’re going to computerize (computer + -ize) that task. Perhaps the computerization (computerize + -ation) of that task makes it much more efficient. You can see how many words have many steps in their derivations.
An interesting thing to note is that once a base has been inflected, then it can no longer go through any derivations. We can inflect the word computer so that we can talk about plural computers, but then we can’t do derivation on the plural form (*computers-ize). Likewise, we can add tense inflection to the verb computerize and talk about how yesterday we computerized something, but then we can’t take that inflected form and use it as the base for a new derivation (*computerized-ation). Inflection always occurs as the last step in word formation.
Talking about morphology when your primary language is English is sometimes a little disappointing because English does not have very much inflectional morphology. Many other languages do much more interesting jobs with inflectional morphology. Many of the Indigenous Languages spoken by the First Peoples of what is currently Canada have rich morphological systems that communicate a great deal of information.
Inuktitut is one of the dialects spoken by the Inuit people who live in the Arctic region. There is a good deal of dialect variation across the Inuit languages. Inuktitut is the variety that is the official language of the territory of Nunavut, and has about 40,000 speakers.
All languages make a distinction between singular and plural nouns, but some languages, like Inuktitut, also use inflectional morphology to indicate dual number when there are exactly two of something, as in the following examples:
| matu | door |
| matuuk | doors (two) |
| matuit | doors (three or more) |
| nuvuja | cloud |
| nuvujaak | clouds (two) |
| nuvujait | clouds (three or more) |
| qarasaujaq | computer |
| qarasaujaak | computers (two) |
| qarasaujait | computers (three or more) |
The three-way distinction between singular, dual, and plural in Inuktitut applies not only to nouns but also to verbs that agree with their noun subjects:
| nirijunga | I eat |
| nirijuguk | the two of us eat |
| nirijugut | we (three or more) eat |
| nirijutit | you (one of you) eat |
| nirijusik | you two eat |
| nirijusi | you (three or more) eat |
| nirijuq | he or she eats |
| nirijuuk | the two of them eat |
| nirijut | they (three or more) eat |
The Cree languages are the Indigenous languages that have the greatest number of speakers, about 80,000 according to Statistics Canada’s 2016 Census.
You might know a language that categorizes nouns according to their gender, like French, which makes a distinction between masculine and feminine nouns, adjectives, and determiners. Of course, grammatical gender has a quite arbitrary relationship to concepts of social and biological gender. Other languages categorize nouns along different criteria. Cree distinguishes words along a dimension called animacy. The animacy distinction is approximately related to whether something is alive or not, but the categories for animate vs. inanimate things are somewhat arbitrary, just the like the categories for masculine vs. feminine things in languages that mark grammatical gender. The animacy of a noun affects which demonstrative determiners may be used with it, the form of the plural morphology, and the morphology of the verb that agrees with it.
In Plains Cree (Nêhiyawêwin), the noun atim (dog) is animate, while astotin (hat) is inanimate. The sentences below shows how the noun’s animacy affects the other words in the sentence.
| animate | inanimate | |
| singular | atimdog | astotinhat |
| plural | atimwakdogs | astotinahats |
| singular demonstrative | awa atimthis dog | ôma astotinthis hat |
| plural demonstrative | ôki atimwakthese dogs | ôhi astotinathese hats |
| singular transitive verb | niwâpamâw atim.I see a dog. | niwâpahtên astotinI see a hat. |
| plural transitive verb | niwâpamâwak atimwak.I see dogs. | niwâpahtên astotinaI see hats. |
All languages make at least a three-way distinction among pronouns — the first person (I/me in English) is the person talking; second person (you) is the person being addressed, and third person (she, he, they, it, etc.) is anybody or anything else. Some languages make even more distinctions in pronouns.
In Ojibwe (Anishnaabemowin), which has about 20,000 speakers, there are two pronouns for the first-person plural. The pronoun niinwi refers to the speaker plus other people but not the person being addressed (that is, “we but not you”). This is known as the exclusive we. The pronoun for inclusive we (“all of us including you”) is kiinwi. The distinction between inclusive and exclusive we is sometimes referred to as clusivity.
Cree also makes an inclusive/exclusive distinction in the first-person plural. The inclusive form is niyanân and the exclusive form is kiyânaw.
In the third person, Cree makes a distinction between proximate and obviative third person. You might think of this distinction as something similar to the near/far distinction between this and that in English, where this is used for something that is closer to the speaker and that is for something farther away. But, like in English, the proximate/obviative distinction is not just about physical distance; it can also allude to distance in time, or within a conversation, to someone that has been mentioned recently (proximate) versus someone that is being mentioned for the first time (obviative). The distinction is marked on the verbal morphology, as illustrated below:
| proximate | Regina wîkiwak. They live in Regina. | kiskinwahamâkosiwak. They are in school. |
| obviative | Regina wîkiyiwa. Their friend/someone else lives in Regina. | kiskinwahamâkosiyiwa. Their friend/someone else is in school. |
These few examples illustrate that the rich morphological systems of these languages can communicate a great deal of information efficiently.
Exercise 1. For each of the following words, identify the affix(es) in the word. For each affix, say whether it is derivational or inflectional. For inflectional affixes, say what grammatical information the affix indicates.
purity
newest
misunderstand
Canadian
unlikely
weaken
nieces
expectantly
Exercise 2. The regular English plural morpheme has several allomorphs, including two different spellings (-s and -es) and three different pronunciations [s, z, ɨz]. Say the following words aloud to yourself and determine which allomorph appears on each word. The form of the allomorph depends on the final sound in the base. What is the natural class of sounds that predicts the appearance of each allomorph?
| books | chips | buses | fans |
| tomatoes | wishes | cuffs | farms |
| cars | judges | shirts | rainbows |
| quizzes | myths | gloves | flies |
| grapes | caves | peas | toys |
| clocks | beaches | dances |
In this chapter, we saw that many words are made up of meaningful pieces called morphemes. In English, the most common bound morphemes are suffixes and prefixes, which can be affixed to words to derive new words, or can convey grammatical information via inflection. Although English has a very productive system of derivational morphology, its inflectional morphology is quite sparse. We looked at some Indigenous languages to examine the kinds of grammatical information that can be represented with inflectional morphemes.
In this chapter, we start observing how words behave so that we can group them into categories. Syntactic categories, which you might think of as “parts of speech”, group words that behave similarly into similar categories. Once we’ve figured out what category a word belongs to, we can predict how it will interact with other words from other categories, for example in compound words (Unit 7.2), and in phrases and sentences (Unit 8.4).
When you’ve completed this chapter, you will be able to:
In Linguistics, we observe how parts of language behave. When we find a set of words that all behave similarly, we can group them into a category, specifically, into a syntactic category. You might have learned about some of these categories as “parts of speech”. This unit gives an overview of the behaviour of the biggest categories.
You’ve probably learned that nouns are words that describe a person, place or thing. But when we’re studying morphology and syntax, we categorize words according to their behaviour, not according to their meaning.There are two elements to a word’s behaviour:
What behaviour can we observe that allows us to categorize words as nouns? Looking at the inflectional morphology, we observe that most nouns in English have a singular and a plural form:
| singular | plural |
| tree | trees |
| book | books |
| song | songs |
| idea | ideas |
| goal | goals |
English uses a plural morpheme on a noun to indicate that there is more than one of something. But there is a subcategory of nouns that don’t have plural forms. Mass nouns like rice, water, money, oxygen refer to things that aren’t really countable, so the nouns don’t get pluralized. Nouns that refer to abstract things (such as justice, beauty, happiness) behave like mass nouns too. If they don’t have plural forms, why do we group them into the larger category of nouns? It’s because their syntactic distribution behaves like that of count nouns. Most English nouns, singular, plural, or mass, can appear in a phrase following the word the:
| the tree, the trees |
| the book, the books |
| the song, the songs |
| the idea, the ideas |
| the goal, the goals |
| the rice |
| the money |
| the beauty (e.g., the beauty of the scenery) |
| the happiness (e.g., the happiness of the children) |
In their syntactic distribution, pronouns (I, me, you, we, us, they, them, he, him, she, her, it) do the job that noun phrases do. A pronoun rarely appears with the, but it can replace an entire noun phrase:
| The woman read the book. |
| *The she read the book. |
| She read it. |
In Essentials of Linguistics, we’ll group pronouns into the larger category of nouns, remembering that they’re a special case.
Verbs behave differently to nouns. Morphologically, verbs have a past tense form and a progressive form. For a few verbs, the past tense form is spelled or pronounced the same as the bare form.
| bare form | past tense form | progressive form |
| sing | sang | singing |
| think | thought | thinking |
| stay | stayed | staying |
| bake | baked | baking |
| remember | remembered | remembering |
| read [ɹid] | read [ɹɛd] | reading |
| set | set | setting |
Adjectives appear in a couple of predictable positions. One is between the word the and a noun:
the red car
the clever students
the unusual song
the delicious meal
The other is following any of the forms of the verb be:
That car is red.
The students are clever.
The song is unusual.
The meal was delicious.
Many adjectives can be intensified with the words very or more:
very clever
more unusual
very delicious
And some adjectives (but not all) have comparative and superlative forms:
red – redder – reddest
smart – smarter – smartest
tall – taller – tallest
tasty – tastier – tastiest
The behaviour of adverbs is a little more difficult to observe. Unlike adjectives, adverbs don’t have comparative or superlative forms, but like adjectives, they can be intensified with very or more:
very quickly
very cleverly
more importantly
The above examples illustrate that many adverbs are derived by affixing -ly to an adjective, but there are also many adverbs that are not derived this way, and there are also some common English words that have the -ly affix that aren’t adverbs but adjectives, like friendly, lonely, lovely, so the affix is not a reliable clue. The syntactic distribution of adverbs is also a little slippery. Adverbs can precede or follow verbs (or verb phrases; see Unit 8.5) to provide information about the verb:
The children sang beautifully.
The students complained loudly about the pop quiz.
They had just arrived when the fire alarm rang.
Samira tripped and nearly broke her wrist.
The visitors will arrive tomorrow.
And adverbs can precede adjectives or other adverbs to provide information about the adjective/adverb:
This meal is surprisingly tasty.
An extremely expensive car drove by.
The children finished their homework remarkably quickly.
Because their behaviour is more variable than that of words in the other open-class categories, adverbs can be a challenge to identify. In the rest of this book, we’ll label adverbs as “A”, the same label that we use for adjectives.
The three syntactic categories of nouns, verbs and adjectives, are called open-class categories. The categories are considered open because when new words get added to the language, they are almost always in one of these three categories — the categories are open to new members. These categories are sometimes also called lexical categories or content words because these categories are the ones that do most of the lexical semantic work in a sentence: they convey most of the meaning of a sentence. The semantic content of the words from other categories (like the, of, in, that, etc.) is not as obvious as the semantics of the words from lexical categories.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=132
1. In the sentence, “The room contained a bearskin rug,” what kind of compound is bearskin?
2. In the sentence, “Randy worked as a cowhand on the ranch,” what kind of compound is cowhand?
3. In the sentence, “Hyunji manages a bookshop,”, what kind of compound is bookshop?
We’ve seen that English frequently uses affixation to derive new words. Affixation is quite productive, meaning that our mental grammar uses the process for many different words, even for new words that come into the language. You’ve probably generated new words yourself sometimes by adding affixes to existing words.
Another extremely productive derivational process in English is compounding. Compounding is different from affixation. In affixation, a bound morpheme is affixed to a base. Compounding derives a new word by joining two morphemes that would each usually be free morphemes.
For example, if I take the free morpheme green, an adjective, and combine it with the free morpheme house, a noun, I get the new word greenhouse. We can tell that this is a new word because its meaning is different from what we would get if we just combined the two words to make a phrase. We could walk down the street describing houses: This is a brown house and this one here is a tall house and here is a red house and here is a greenhouse. But a greenhouse is something different from a house that’s green! It’s a new word, derived by compounding.

Credit: Joe Shlabotnik on Flickr; Attribution 2.0 Generic (CC BY 2.0)

Image “Greenhouse at Wilson Farm, East Lexington MA“ by John Phelan is licensed under CC BY 3.0.
Another way that words derived by compounding differ from words derived by affixation is that a compound word doesn’t really have a base or root that determines the meaning of the word. Instead, both pieces of a compound make a sizeable contribution to the meaning. For example, yoga pants are pants that you wear to do yoga, and emerald green is the particular colour of green that emeralds are. So it doesn’t make sense to say that compounds have a root.
On the other hand, there is one part of a compound that has a special role, which we can see if we think about the categories of the words that make up a compound. If you look at these examples,
dry clean
stir fry
outrun
power wash
Each compound is made up of a different category of the word on the left plus a verb on the right. But in each case, the compound word is a verb. Even if both parts of a compound contribute to the meaning of the compound, it’s the head of a compound that determines its category. We say that English is a head-final language because in English the second part of the compound determines the category of the compound. Some languages are head-initial, with the head as the first element in a compound.
In many compounds, the head determines the category and also constrains the meaning of the compound. So dog food is a kind of food, not a kind of dog, and yoga pants are a kind of pants, not a variety of yoga. Compounds like this, where the meaning relationship between the head and the whole compound is obvious, are called endocentric. But in some compounds, the meaning relationship is not so transparent. For example, a redhead is a person, not a kind of head; a nest egg is money that you’ve saved, not a kind of egg; a workout is not a particular kind of out, and facebook is not a book at all! Compounds where the meaning of the head does not predict the meaning of the compound are said to be exocentric.
In Unit 7.1 we saw that linguists group words into syntactic categories according to how they behave. Content words convey a lot of the meaning of a sentence. But not many sentences would be complete if they contained only nouns, verbs, or adjectives. There are also several smaller categories of words called closed-class categories because the language does not usually add new words to these categories. These categories don’t have many members, maybe only a few dozen, in contrast with the many thousands of words in the open-class categories. They’re the function words or non-lexical categories that do a lot of grammatical work in a sentence but don’t necessarily have obvious semantic content.
The category of determiners doesn’t have many members but its members occur very frequently in English. The two little words the and a are the most recognizable members. Determiners most often appear before a noun, as in:
a student
an orange
the snake
the ideas
Any word that can appear in the same position as the counts as a determiner, like demonstratives:
those students
these oranges
that snake
this idea
Quantifiers and numerals also behave like determiners:
many students
twelve oranges
most snakes
several ideas
And the words that you might have encountered as “possessive adjectives” or “possessive pronouns” behave like determiners as well:
my sister
your idea
their car
The category of prepositions seems to have slightly more obvious semantic content than most other closed classes. Prepositions often represent relationships in space and time. They also have consistent syntactic distribution, usually appearing with a noun phrase immediately following them:
on the table
in the basket
around the block
through the centuries
near campus
after class
A very small category of words that does an important job are the conjunctions. There are only three conjunctions, and, or, but. The job that conjunctions do is to conjoin two words or phrases that belong to the same category:
oranges and lemons
brushed her teeth and went to bed
strong and fast
soup or salad
singing or dancing
hated her roommate but loved her roommate’s sister
small but mighty
You might have learned that words like because and although are a type of conjunction, but they don’t behave like and, or, but. Their behaviour is more similar to a category of words we label as complementizers. Complementizers are function words that introduce a clause, which is a sentence embedded inside a larger sentence:
Sam told us that she loved baseball.
She hoped that the Blue Jays would win the World Series.
Leilani wondered whether it would rain that afternoon.
She asked her roommate if she had heard the forecast.
The roommate checked the forecast because she wanted to go for a run.
She decided to go running although a storm was forecast.
Mel washed the dishes while the cupcakes were in the oven.
Auxiliaries are what you might have called “helping verbs” when you first learned about grammar: they help a lexical verb by providing grammatical information about a verb’s tense or aspect, or other subtle elements of meaning. There are nine modal auxiliaries, which never change their form because they are never inflected.
Kieran can sing really well.
Laura could climb that rock wall.
We shall decide by drawing straws.
You should take a nap.
The guests will arrive soon.
Malik would like to read that book.
You may leave after you’ve finished the test.
The road might be slippery.
Drivers must obey all traffic laws.
The verbs have, be, and do sometimes behave like auxiliaries and sometimes like ordinary lexical verbs. Unlike the modal auxiliaries, have, be and do get inflected (had, has, having, am, is, are, was, were, been, being, did, done, doing), so even when they are auxiliaries, they are non-modal. Their inflection is not a clue to whether they are auxiliaries or not, so we have to look at their behaviour in the context of a sentence.
If a sentence includes a lexical verb or main verb, then have, be or do in that sentence is likely to be an auxiliary, helping the lexical verb. In the following examples, the auxiliary verbs are underlined and the lexical verbs (also known as main verbs) are bolded:
Arlene is writing a novel.
Beulah has arrived in Saskatoon.
Carmen is planning her vacation.
Doris did not buy any vegetables.
Evlien has been thinking about switching programs.
In addition to their auxiliary functions, have, be and do also have some lexical meaning of their own. If there’s no other verb in the clause, then have, be, or do is probably the main verb of a clause. In these examples the lexical verbs are bolded:
Foster is proud of his sister.
Green vegetables are important for good health.
Harold has an idea for an app.
Ira did his homework before supper.
Javier had a big party.
If have, be or do serves as the lexical verb, then it might also have some auxiliaries helping out:
Foster has been proud of his sister.
Green vegetables might be important for good health.
Harold did have an idea for an app.
Ira could have been doing his homework before supper.
Javier is having a big party.
Notice that not every sentence has an auxiliary, but every sentence does have a lexical verb.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=138
1. Comparing the following sets of words, which would you predict would lead to greater blood flow in more areas of the brain?
2. When shown a picture of a pair of tongs, a patient describes the picture, “You pick up things with it”. Which type of aphasia is this response more typical of?
3. When describing an injury to his knees, a patient says, “no good uh ache and uh uh uh knees and ankles uh home doctor and legs”. Which type of aphasia is this response more typical of?
Lorraine Tyler and her colleagues used functional magnetic resonance imaging (fMRI) to measure blood flow to different regions of the brain. The idea behind fMRI is that brain activity consumes oxygen, and when a particular area of the brain is active, then more blood flows there to bring it more oxygen. The researchers asked people to do an easy task. They showed them lists of three words and asked them to decide if the third word, the one in all caps, was related to the first two. So in this example, sparrows, thrushes, and wrens are all kinds of birds, so the participants would respond Yes. In this next example, hammer, wrench, banana, the first two are tools but the third one is a fruit, so it’s not related to the first two, so the participants would answer No.
Some of the words in this task were nouns, like the lists we just saw, and some were verbs, like these ones: eating, grazing, dining. All of those words are related to eating, so the participant would decide Yes. This is a pretty simple task, but what the researchers found in the fMRI was that there were several areas of the brain that showed greater blood flow for verbs than for nouns! Apparently, the brain was reacting differently to words from these two different syntactic categories, even though the task was the same for both categories.
We also see differences between nouns and verbs in the brains of people with aphasia. Aphasia is the name for any kind of language disorder that results from an injury to the brain, such as a stroke or a tumour. There are different kinds of aphasia that have different kinds of symptoms. Louise Zingeser and Rita Sloan Berndt found a dissociation between nouns and verbs in the speech of two different groups of people with aphasia.
The researchers asked their participants to do a few simple tasks. One was a picture naming tasks, where the researcher would show a line drawing and ask the participant to say what it was, like a fish or a car. In another task, they asked participants to describe how they would go about a particular action, such as making a birthday cake or attending a concert. And in the last task, they gave participants a picture book that depicted a well-known fairy tale but didn’t have any words in it and asked them to tell the story. So from all these tasks, they had a good collection of each person’s speech. For each person, they calculated the ratio of nouns to verbs.
It turns out that in people without any brain injury, the ratio of nouns to verbs is pretty close to one. That means there are about the same number of nouns as there are verbs in the average person’s speech for these tasks. But for people with agrammatic aphasia, verbs are very difficult to produce. These people had more than twice as many nouns as verbs. And for people with anomic aphasia, nouns are quite difficult. This group of people had fewer nouns than verbs.
Aphasia researchers call this kind of pattern a dissociation. We say that nouns are verbs are dissociated from each other because it’s possible to have verb production impaired while noun production is ok, or vice versa. This dissociation is consistent with the idea that verbs and nouns are processed differently in the brain.
So what does all this mean? We’ve seen that, in typical brains, a simple task with verbs involves greater brain activity than the same task with nouns. And in people with brain injuries, some people have an impairment of verbs but not nouns, while others have an impairment of nouns but not verbs.
All this suggests that our brains treat words differently depending on what category they’re in. Or in other words, different syntactic categories exist not just in language, but also in the brain!
Exercise 1. In the following paragraph, identify all the nouns, verbs, and adjectives:
“The main door of the school is on the side away from the town. The drive leading to it is long, cutting straight across between the tennis courts after it leaves the big wooden gates, then curving round the extreme edge of the gardens until, after a long, straight stretch up the slope, it ends in the courtyard by the front door. It takes about five minutes’ fast walking to get from the gates to the grateful seclusion of the court during which you become thoroughly self-conscious as you notice the eyes watching you from the windows. Once you reach the corner of the house you are safe.”
Exercise 2. In the following sentences, give the category of all the words from closed-class categories:
“All the rooms on the ground floor open off the T-shaped front hall. When you come in from the courtyard the doors of Mlle Tourain’s study are directly opposite you; on your right are the kitchens and laundry-rooms and between them and the study, occupying the whole corner, is the dining-room. On your left, behind the big dark staircase which curves up to the first floor, is the girls’ living-room, and in front of it on the south-east corner, the main classroom.”
Exercise 3. In the following sentences, identify all the modal auxiliaries, non-modal auxiliaries, and the main verb uses of have and be:
“Some day they are going to get it mended but at present they are too busy, for Mlle Tourain is correcting proofs for the second volume of her work on the history of Swiss independence, which will appear next autumn, and she, Mary Ellerton, has no time for anything, since she dismissed the housekeeper and has her job as well as that of assistant principal.”
Exercise 4. Compound words in English are variable in their spelling: some are spelled with no space between the elements of the compound (redhead, greenhouse), some are spelled with a space (ice cream, ski boots), and some are spelled with a hyphen between the elements (gluten-free, long-term). Identify all the compounds in the following sentences:
“Amélie Tourain leaned forward a little and switched on her desk light.”
“The third occasion on which she said something funny the headmistress had glanced at her over Doris Anderson’s note-book, then at Mlle Devaux, and after that things went much easier with the grammar teacher.”
“Mlle Tourain was sitting back in her chair now, and had begun to tap the rubber end of her pencil against the brass ink-pot.”
“She had spoken with an undercurrent of passion running through her words, as she was speaking now.”
In this chapter, you’ve learned how to categorize words according to their behaviour, which categories are open to new members, and which categories are not. You’ve also learned that compounding is a very productive means of deriving new words in English by combining two words. While most compounds are endocentric and have a head that determines the meaning and category of the word, for exocentric compounds, the meaning of the compound drifts over time, leaving the compound without a head.
This long chapter looks at how our mind combines words to generate sentences. The model of the mental grammar that we propose is quite simple: Words and features are stored in the mental lexicon, and the operation MERGE combines these words and features into organized, but simple structures. In this chapter, we learn how to observe the behaviour of sentences to draw conclusions about how these structures are organized in our minds, and how to use the notation called tree diagrams to illustrate that organization.
When you’ve completed this chapter, you will be able to:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=146
In the following tree diagram:
1. What is the structural relationship between V loves and NP sushi?
2. What is the structural relationship between NP Colin and V loves?
3. Which node is the sister of NP Colin?
We’re about to start looking into how sentences are organized in our mental grammar. Before we do that, we need to be familiar with a particular kind of notation called a tree diagram. We’ll see that, within each sentence, words are grouped into phrases. Phrases can be grouped together to form other phrases, and to form sentences. We use tree diagrams to depict this organization. They’re called tree diagrams because they have lots of branches: each of these little lines that join things in the diagram is a branch.
Every place where branches come together is called a node. Nodes indicate a set of words that act together as a unit: each node corresponds to a group of words called a constituent, which you’ll learn about in another unit. If a node has no daughters, we call it a terminal node.
Within a tree diagram, we can also talk about the relationships between different parts of the tree. Every branch joins two nodes. The higher one is called the mother, and the lower one is called the daughter. A mother can have more than one daughter, but each daughter has only one mother. And, as you might expect, if two daughters have the same mother, then we say that they’re sisters to each other.
Having this vocabulary for tree diagrams will allow us to talk about the syntactic relationships between the parts of sentences in our mental grammar.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=150
1. In this tree diagram, what position does the DP my coffee occupy?
2. In this tree diagram, what position does the D my occupy?
3. In this tree diagram, what position does the NP Hamilton occupy?
We’re starting to look at how our minds organize sentences. We’ll see that within each sentence, our mental grammar groups words together into phrases and phrases into sentences. We saw in the last unit how we can use tree diagrams to show these relationships between words, phrases and sentences.
The theory of syntax that we’re working within this class is called X-bar theory. X-bar theory makes the claim that every single phrase in every single sentence in the mental grammar of every single human language, has the same core organization. Here’s a tree diagram that shows us that basic organization. Let’s look at it more closely. According to x-bar theory, every phrase has a head. The head is the terminal node of the phrase. It’s the node that has no daughters. Whatever category the head is determines the category of the phrase. So if the head is a Noun, then our phrase is a Noun Phrase, abbreviated NP. If the head is a verb (V) then the phrase is a verb phrase (VP). And likewise, if the head is a preposition (P), then the phrase is a preposition phrase (PP), and Adjective Phrases (AP) have Adjectives as their heads.
So the bottom-most level of this structure is called the head level, and the top level is called the phrase level. What about the middle level of the structure? Syntacticians love to give funny names to parts of the mental grammar, and this middle level of a phrase structure is called the bar level; that’s where the theory gets its name: X-bar theory.
So if every phrase in every sentence in every language has this structure, then it must be the case that every phrase has a head. But you’ll notice in this diagram that these other two pieces, the specifier and the complement, which we haven’t talked about yet, are in parentheses. That’s to show that they’re optional — they might not necessarily be in every phrase. If they’re optional, that means that it should be possible to have a phrase that consists of just a single head — and if we observe some grammaticality judgments, we can think of phrases and even whole sentences that seem to contain a head and nothing else. We could have a noun phrase that consists of a single noun — Coffee? or Spiderman! We could have verb phrase that has nothing in it but a verb, like Stop! or Run! Or an adjective phrase might consist of only a single adjective, like Nice… or Excellent!
But X-bar theory proposes that phrases can have more in them than just ahead. A phrase might optionally have another phrase inside it in a position that is sister to the head and daughter to the bar level. If there’s a phrase in that position, it’s called the complement. The most common kinds of head-complement relationship we see are a verb taking an object or a preposition taking an object. Let’s look at some examples. Here we’ve got a verb phrase, with the verb drank as its head. That head has the noun phrase coffee as its sister. The NP coffee is sister to the verb head and daughter of the V-bar node so it is a complement of the verb.
Here’s another example that has the same structure, but a different category. The head of this phrase is the preposition near, so the phrase is a preposition phrase. The complement of the preposition is the noun phrase campus and the whole phrase is near campus. Try to think of some other examples of verbs and prepositions that take noun phrases as their complements.
The other common place we see a head-complement relationship is between a determiner and a noun. In phrases like my sister, those shoes, and the weather, the determiner is a head that takes an NP complement.
X-bar theory also proposes that phrase can have a specifier. A specifier is a phrase that is sister to the bar-level and daughter to the phrase level. The most common job for specifiers is as the subjects of sentences, so we’ll look at those in another unit.
We’ve started to use tree diagrams to represent how phrases are organized in our mental grammar. And we’re using the tree diagram notation to represent every single phrase as having X-bar structure. But so far I’ve just asked you to believe me about X-bar structure: I’ve told you that this is what the theory claims, but we haven’t yet talked about any evidence that our mental grammar really is organized into phrases that have X-bar structure. This unit shows some of the linguistic evidence that phrases have some reality in the mental grammar.
When we draw a tree diagram, we’re making a claim about how a sentence or phrase is organized in our mind. Every time we draw two or more branches coming together at a node, we’re making the claim that the node corresponds to a unit. In other words, all the daughters of that node behave together as a unit. Some of these nodes are at the phrase level, and some of them are at the bar-level. The more generic term for a group of words that act together to form a unit is a constituent.
So what’s our evidence that constituents exist in our minds? Within a given sentence, how can we tell if a given string of words acts as a unit? Here again is where we rely on observing our grammaticality judgments, using a few simple tools.
Here’s a simple sentence:
The students saw their friends after class.
Let’s consider the string of words their friends. Because you’ve already started to practice drawing trees, you probably have an instinct that this is a noun phrase. But if you’re going to claim that it’s a constituent, it would be nice to have some evidence for that claim. One piece of evidence is that we can replace this set of words. Take the pronoun them and replace the string of words we’re investigating:
The students saw their friends after class.
The students saw them after class.
Then we ask ourselves whether the resulting sentence is grammatical. Replacing their friends with them does indeed leave us with a grammatical sentence, which is one piece of evidence that their friends is a constituent.
Let’s test another chunk of this sentence. Let’s try the string of words after class. If we replace that set of words with the word then:
The students saw their friends after class.
The students saw their friends then.
And when we observe our grammaticality judgment, it turns out that this replacement is also grammatical. That’s some evidence that words after class behave together as a constituent in this sentence.
We can do the same thing with the string the students. Replace that string with the pronoun they:
The students saw their friends after class.
They saw their friends after class.
And observe our grammaticality judgment, and we find evidence that the students is a constituent as well.
What happens if we try to replace a string of words that isn’t a constituent?
The students saw their friends after class.
*The they friends after class.
*The did friends after class.
*The then friends after class.
*The them friends after class.
We can try lots of replacements, but when we ask ourselves whether the result is grammatical, the answer is No. There doesn’t seem to be anything that can replace the string of words students saw their. The fact that nothing can replace that string of words suggests that students saw their is not a constituent in this sentence.
At this point, you’re probably wondering how you know what you can use as a replacement. Here are some handy tips:
Let’s see how this replacement tool works for a verb phrase. We’ll go back to our sentence and look for the verb, saw. Let’s test this set of words: saw their friends. Since saw is the past tense of see, we’ll try replacing it with did, the past tense of do, and observe our grammaticality judgment.
The students saw their friends after class.
The students did after class.
This replacement is grammatical, so that provides us with some evidence that the set of words saw their friends is indeed a constituent.
You can use this evidence as you’re drawing trees. If you can’t quite figure out which groups of words go together into certain phrases, you can try replacing different chunks of the sentence. The parts that allow themselves to be replaced, that is, the parts that can be replaced and still leave a grammatical sentence are constituents, and those parts will be joined under one node.
You can also use this evidence when you’re trying to figure out what category a certain phrase is: If you can replace it with a pronoun, then you’ve got a noun phrase and you can look for the noun as the head. If you can replace it with do or do so, then you’ve got a verb phrase which will have a verb as its head. Then and there are a little less reliable because they sometimes replace PPs or APs, but you’ll be able to tell the difference between prepositions and adjectives because prepositions usually have complements and adjectives don’t.
Replacement is not the only tool we have for checking if a set of words is a constituent. Some constituents can be moved to somewhere else in the sentence without changing its meaning or its grammaticality. Preposition Phrases are especially good at being moved. Look at this sentence:
Nimra bought a top from that strange little shop.
Let’s start by targeting the last string of words by moving it to the beginning. Move the string of words then ask yourself whether the resulting sentence is grammatical.
Nimra bought a top from that strange little shop.
From that strange little shop Nimra bought a top.
Yes, it is. Standing here in isolation, the sentence might sound a little unnatural, but we can imagine a context where it would be fine, such as, “At the department store, she bought socks, at the pharmacy she bought some toothpaste, and at that strange little shop, she bought a top.” On the other hand, if we target a smaller string of words:
Nimra bought a top from that strange little shop.
*From that strange, Nimra bought a top little shop.
If we try to move that string to the beginning of the sentence, the result is a total disaster. The fact that the resulting sentence is totally ungrammatical gives us evidence that the string of words from that strange is not a constituent in this sentence.
There’s a version of the movement tool that can be useful for other kinds of phrases. It’s called Clefting. A cleft is a kind of sentence that has the form:
It was ____ that …
To use the cleft test, we take the string of words that we’re investigating and put it after the words It was, then leave the remaining parts of the sentence to follow the word that. Let’s try it for the phrases we’ve already shown to be constituents.
Nimra bought a top from that strange little shop.
It was from that strange little shop that Nimra bought a top.
The students saw their friends after class.
It was their friends that the students saw after class.
It was after class that the students saw their friends.
And let’s try the cleft test on another new sentence.
Rhea’s sister baked these delicious cookies.
It was these delicious cookies that Rhea’s sister baked.
It was Rhea’s sister that baked these delicious cookies.
The cleft test shows us that the string of words these delicious cookies are a constituent, and that the words Rhea’s sister are a constituent. But look what happens if we apply the cleft test to another string of words:
Rhea’s sister baked these delicious cookies.
*It was sister baked that Rhea’s these delicious cookies.
Rhea’s sister baked these delicious cookies.
*It was these delicious that Rhea’s sister baked cookies.
Rhea’s sister baked these delicious cookies.
*It was cookies that Rhea’s sister baked these delicious.
All of these applications of the cleft test result in totally ungrammatical sentences, which gives us evidence that those underlined strings of words are not constituents in this sentence.
If a string of words is a constituent, it’s usually grammatical for it to stand alone as the answer to a question based on the sentence.
Rhea’s sister baked these delicious cookies.
What did Rhea’s sister bake? These delicious cookies.
Who baked these delicious cookies? Rhea’s sister.
The answer-to-questions test can also help us identify a verb phrase using do-replacement:
Who baked these delicious cookies? Rhea’s sister did.
Notice that in the answer, “Rhea’s sister did”, the word did automatically replaces the verb phrase baked these delicious cookies.
Again, if a string of words is not a constituent, then it is unlikely to be grammatical as the answer to a question. In fact, it’s difficult to even form the right kind of question:
What did Rhea’s sister bake cookies? *these delicious
Who of Rhea’s these delicious cookies? *sister baked
Remember that tree diagrams are a notation that linguists use to depict how phrases and sentences are organized in our mental grammar. We can’t observe mental grammar, so observing how words behave is how we make inferences about the mental grammar. These four tests are tools that we have for observing how words behave in sentences. If we discover a string of words that passes these tests, then we know that the phrase is a constituent, and therefore there should be one node that is the mother to that entire string of words in our tree diagram.
Not every constituent will pass every test, but if you’ve found that it passes two of the four tests, then you can be confident that the string is actually a constituent. When you’re drawing trees, use these tests as a check every time you draw a mother node.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=160
1. Which of the following is the correct representation for the sentence, Sara bought a car?
2. Which of the following is the correct representation for the sentence, Sang-Ho won a medal?
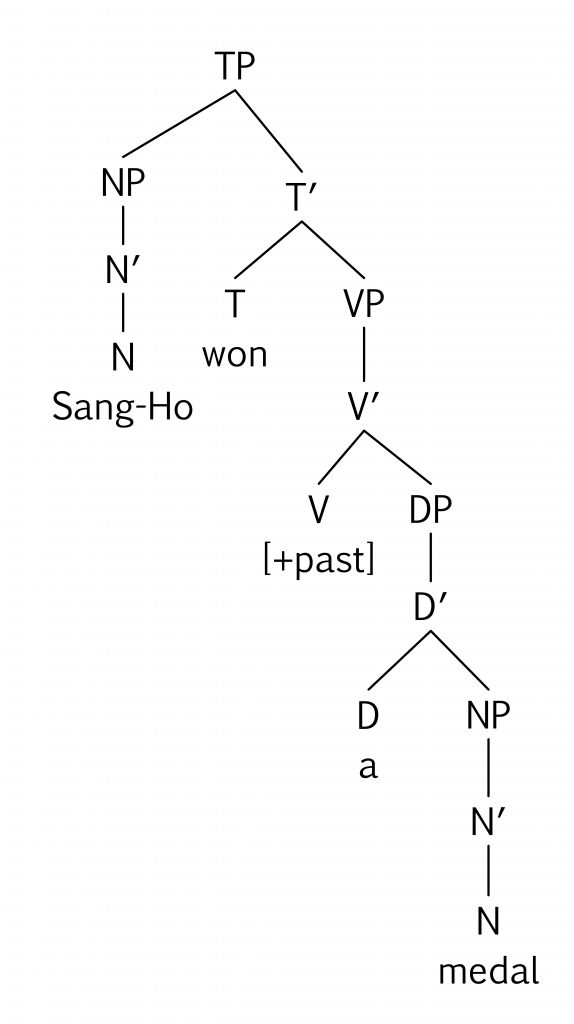
3. Which of the following is the correct representation for the sentence, Prabhjot should read this article?
We’ve been developing a model for how the mind generates sentences. Our idea is that we draw words, morphemes, and morphosyntactic features from the mental lexicon, and then the operation MERGE organizes all these things and into an x-bar structure. And the theory makes the quite powerful claim that every phrase in every sentence is organized in an x-bar structure, with a head, a bar-level and a phrase level.
So it’s fairly easy to understand that verb phrases have verb heads, and preposition phrases have preposition heads. But what kind of phrases are sentences? If we look carefully, we can observe that every sentence includes one and only one tense feature, which occupies a head position that we label as T, for Tense. And of course, where there is a head there are also the bar level and the phrase level. So a sentence is a T-phrase.
Let’s see how this works in a fairly simple sentence. “Alex should try yoga.” We already know how to depict verb phrases. The verb try is a transitive verb, and the NP yoga is its complement. The modal auxiliary should occupies the T head position. A T head always takes a VP as its complement. So every sentence that we see from here on will have a T head with a VP complement.
Whenever there’s a head, there’s also a bar-level and a phrase level. And the last phrase we have left in the sentence is the noun phrase Alex. It’s the subject of the sentence. We said that specifiers are kind of special, and the subject is the most special of all. The Specifier of TP is the position for the phrase, usually a noun phrase, that’s the subject of the sentence. Subjects go in SpecTP.
To sum that all up, every sentence is a T-phrase. The T-head of the T-phrase takes a VP as its complement. And the specifier of TP is a noun phrase, and the name for the noun phrase that occupies that position is the subject of the sentence.
What kinds of things can occupy the T-head position? The example that we just saw had a modal auxiliary in the T-head position. But not all sentences have modals in them. If the sentence does not have a modal auxiliary, then the T-head position will be occupied by a morphosyntactic tense feature. And when we’re looking at English, there are only two tense features, [-past] and [+past].
Let’s see how this works in another simple sentence, very similar to the last one: Alex loves yoga. Remember that the theory claims that when we draw a verb in its tensed form from the mental lexicon, we also bring along the tense feature as well. Loves is in the present tense, so it has the [-past] feature.
The structure of this sentence is the same as the previous one we looked at. The only difference is that, instead of a modal auxiliary in the T position, we have that morphosyntactic tense feature. We put this feature in brackets to indicate that it’s present in our mental grammar but it doesn’t actually get pronounced when we say the sentence out loud. You could think of it as present in the underlying form, but not in the surface form. The job of this feature in the T-head position is to make sure that its complement has the correct form. Since this feature is [-past], it wants to make sure that the verb in its VP complement is in the [-past] (that is, the present-tense) form. If there were some non-tensed form of the verb there, like Alex loving yoga or Alex love yoga, the sentence would be ungrammatical.
Every English verb has five different forms, but only two of the forms have a tense feature. The tensed forms are indicated with a morphosyntactic feature, either [+past] or [-past]. The form that a verb in the V-head position takes depends on what tense feature is in the T-head position, among other things.
| bare | (non-tensed) | eat | walk | sing | take |
| [-past] | (tensed) | eats | walks | sings | takes |
| [+past] | (tensed) | ate | walked | sang | took |
| past participle | (non-tensed) | eaten | walked | sung | taken |
| present participle | (non-tensed) | eating | walking | singing | taking |
But there are some quirks of English that can make things confusing:
For just about every verb, the [-past] form is recognizable in the 3rd-person-singular form (she eats/walks/sings/takes). The 1st & 2nd-person forms (I eat/walk/sing/take and You eat/walk/sing/take) look just like the bare form (eat/walk/sing/take).
If you’re looking at a verb and can’t tell if it’s in the bare form or the [-past] form, give it a 3rd-person subject and then look for the –s morpheme:
I want to visit Saskatoon. (bare or [-past]? Can’t tell: they’re ambiguous)
She wants to visit Saskatoon. (wants is [-past], visit is bare)
For many English verbs, the [+past] form (She bought a donut) and the past participle form (She has bought a donut) are the same.
If you’re looking at a verb and can’t tell if it’s in the [+past] form or the past participle form, try replacing it with the verb eat:
She bought a donut after she had walked the dog. ( [+past] or past participle? Can’t tell: they’re ambiguous)
She ate a donut after she had eaten the dog. (Silly, but grammatical)
The form ate is [+past], while eaten is past participle, so we can conclude that, in that sentence, bought is [+past] while walked is the past participle)
The modal auxiliaries never change their form: they occupy the T-head position in their own right.
The non-modal auxiliaries, like main verbs, change their form depending on what tense feature is in the T-head position, among other things.
| bare | (non-tensed) | be | have | do |
| [-past] | (tensed) | am/are/is | has | does |
| [+past] | (tensed) | was/were | had | did |
| past participle | (non-tensed) | been | had | done |
| present participle | (non-tensed) | being | having | doing |

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=164
1. What is the subcategory of the underlined verb in this sentence?
The soccer players kicked the ball.
2. What is the subcategory of the underlined verb in this sentence?
Many birds fly over Ontario each fall.
3. What is the subcategory of the underlined verb in this sentence?
This game teaches children the alphabet.
Let’s consider a simple sentence, Jamie might bake cupcakes.This is a perfectly grammatical English sentence, and we can account for it all using x-bar structure. If we change the verb bake to the verb eat, our sentence is still grammatical, Jamie might eat cupcakes. And that makes sense of what we know about how categories work — we group verbs together into the verb category because they behave the same way.
But what about these sentences?
Jamie might arrive cupcakes.
Jamie might hope cupcakes.
Are these grammatical? My mental grammar doesn’t generate these, and I bet yours doesn’t either. And their ungrammaticality isn’t just a matter of them not making semantic sense, either. Since the verb arrive often has something to do with a location, we could try changing cupcakes to Toronto, but the sentence is still ungrammatical: the grammar of English does not generate the sentence, Jamie might arrive Toronto. But why aren’t these sentences grammatical? There’s no doubt that arrive and hope are verbs, and they seem to fit into the same x-bar structure that was grammatical for lots of other sentences. Why doesn’t our mental grammar generate the sentence Jamie might hope cupcakes?
It’s something to do with the verbs themselves. Some heads are picky about the kinds of complements they’re willing to take. And this is especially true for verbs. Within the large category of verbs, we can group verbs further into subcategories according to the kinds of complements they take. For each head, the mental lexicon stores not just syntactic category information, but also subcategory information. The subcategory information tells us what kinds of complements each head will accept. So let’s look at a few verb subcategories.
Transitive Verbs have one complement, a noun phrase, so they have this basic structure. The verb baked is transitive when it has an NP complement like cupcakes. Here are some other transitive structures: drank coffee, likes Linguistics, needs money, speaks Mandarin.
When there is a noun phrase in the complement of a verb, we call it the direct object. And the direct object NP doesn’t have to be a single word. It could be a fairly complex phrase itself. As long as it’s a noun phrase and it’s the complement of a verb head, we call it the direct object, and the verb is a transitive verb.
Intransitive verbs have no complement at all. These are verbs that describe an action or state that involves just a single participant, like sneezed or arrived or dances or slept.
There’s a small set of verbs that are called ditransitives. They’re a little special because they have two complements, but for them to count as ditransitives, they have a special kind of behaviour, called the dative alternation. The best example of a ditransitive verb is the verb give. Take a look at this structure and notice that the V-head gave has two sisters — two complements — the NP cupcakes and the PP to Sarah. But this verb give has another possible grammatical structure that means exactly the same thing. In this alternate structure, the verb has two NP complements. The NP Sarah, which was the complement to the preposition in the other structure, is now the first complement, and cupcakes has become the second complement.
The fact that our mental grammar generates both these structures for this verb and its complements is called an alternation. There are other alternations in our mental lexicon, but this particular one is called the dative alternation, which comes from the Latin word for give. Most of the verbs that allow the dative alternation are verbs that have a meaning that’s related to giving. Send is another example:
She sent a letter to her grandmother. // She sent her grandmother a letter.
Or to hand someone something:
She handed a coffee to her friend. // She handed her friend a coffee.
The last subcategory of verbs to talk about is another small one, but it’s an interesting subcategory. Some verbs take complements that are entire sentences. Each of these verbs, hope, doubt, wonder, ask, has a complement that could stand alone as a sentence:
Ann hopes that the Leafs will win.
Bev doubts that the Leafs can win.
Carla wondered if she should cancel her season’s tickets.
Divya asked whether Eva liked hockey.
Each of these sentences, or clauses, is embedded inside the larger sentence. And each one is introduced by a word from the category of complementizers. The words that, if, and whether are called complementizers because they introduce complement clauses. Let’s look at the structure of one of these sentences.
First, the embedded clause, which could stand as a sentence in its own right — it has a tense feature in the T-head position. The complement to the T-head is, as always, a VP. In this clause, the verb is intransitive so it has no complements, and the entire phrase is made up of the word win. This clause has a subject, an NP in the SpecTP position, the Leafs.
So this whole TP could be a sentence in its own right, but we know that in this case, it’s embedded inside a larger sentence — it’s the complement to the verb hopes. And often when a clause is in complement position, it gets introduced by a complementizer, which is a head of its own that we label as C. Notice that because the complementizer that is a C-head, there is also a C-bar and CP level as well.
Now from here on it’s quite simple. This whole CP is simply the complement of the verb hopes, so it’s sister to the V-head and they’re both daughters of V-bar. And then this matrix clause has its own T-head, T-bar and TP levels, and the subject NP in SpecTP is Ann.
OK, let’s recap. We’ve seen now that in addition to category information, the mental lexicon includes subcategory information for some heads. Verbs belonging to different subcategories are choosy about the form their complement takes. This means that it would be possible for a given sentence to be ungrammatical even if it has an x-bar structure if the complement is the wrong kind for that subcategory of head. And we’ve looked at four different verb subcategories:
We use grammatical role labels to identify the syntactic position of Noun Phrases within each clause. It’s vital to remember that grammatical role labels are defined strictly according to syntactic positions, not according to the meaning of a noun phrase or its semantic relationship to the verb. We’ll come back to this idea in the next chapter.
The subject NP is the NP that appears in the Specifier of TP. The underlined phrases in the following sentences are all subjects of their respective clauses.
Zora kicked the soccer ball.
Yasmin guessed that Xavier would probably be late.
That tall woman nearly knocked me over.
The view from the top floor is quite impressive.
Understanding Calculus takes a lot of work.
The town where I was born recently elected a new mayor.
The direct object NP is the complement to a Verb head. Each of the following underlined phrases is a direct object.
Zora kicked the soccer ball.
Xavier’s lateness annoyed Yasmin.
William convinced Veronica that class was cancelled.
Ursula asked the fellow who works at Tim Horton’s what time the store closed.
Stefanie bought a gift certificate for $100 for her mother.
If we refer to an NP simply as the object, by default we mean the direct object, not the indirect object (see below).
If a Verb head takes a complement that is some category other than an NP, then that complement phrase does not count as a direct object. The phrases following the verbs in these sentences are NOT direct objects, even though they are complements to V-head, because they are not NPs.
Yasmin guessed Xavier would be late.
Rana seemed unhappy.
The parcel was on the porch.
We can identify two additional grammatical roles for NPs, according to the syntactic positions they occupy. An indirect object only appears with a ditransitive verb. It is the NP that alternates between being the complement of a P-head and the complement of a V-head, for a verb that allows the dative alternation. The underlined phrases below are all indirect objects:
Stefanie bought a gift certificate for her mother.
Stefanie bought her mother a gift certificate.
Quinn texted directions to the party to her friends.
Quinn texted her friends directions to the party.
Preeti sent a bouquet of flowers to her aunt.
Preeti sent her aunt a bouquet of flowers.
If a verb does not allow the dative alternation, then it does not have an indirect object.
If an NP appears as the complement to a preposition, but does not an alternate position to become the complement of a verb in the dative alternation, then it is not an indirect object, but an oblique. Oblique is the catch-all label for all other positions that NPs can occupy in a sentence. The underlined phrases below are all obliques:
Oscar bought a bicycle from that store on Locke Street.
Norma left her business card on the table.
Massimo watched a documentary about antibiotics.
These four labels: subject, direct object, indirect object, and oblique, describe Noun Phrases only in terms of what position they occupy in a clause. Look at the following two sentences:
A famous food critic reviewed this restaurant.
This restaurant was reviewed by a famous food critic.
Even though the person who does the reviewing is the same person (the famous food critic) in both sentences, the NP a famous food critic is not the subject of both sentences, only of the first. The subject of the second sentence is the NP this restaurant. Grammatical role labels describe the syntactic position of noun phrases.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=168
1. Is the underlined phrase an adjunct or a complement?
Sam ran the Around-the-Bay race.
2. Is the underlined phrase an adjunct or a complement?
Sam ran this morning.
3. Is the underlined phrase an adjunct or a complement?
The baby slept through the night.
We’ve been working at representing how phrases and sentences are organized in the mental grammar, and to do that we’ve been using x-bar theory, which claims that every phrase in every sentence in every language of the world is organized into an x-bar structure. An x-bar structure has a head, a bar-level and a phrase level. It might, optionally, have a complement phrase as the sister to the head and daughter to the bar-level. It might, optionally, have a specifier as sister to the bar level and daughter to the phrase level.
But as you’ve been drawing trees and thinking about how sentences are organized in your mental grammar, you might have encountered some kinds of sentences that don’t seem to fit into an x-bar structure. The X-bar structures that we’ve looked at so far have left out one element. The additional level of structure that we need is called an adjunct, and here’s what it looks like. What structural relationships do you notice? The adjunct is sister to the bar-level, but here’s something we haven’t seen before: it’s also daughter to a bar-level. This is an instance of recursion. A recursive structure is a structure that contains another structure inside it that has the same type as itself. Some linguists argue that recursion is a fundamental property of all human languages and that it’s one of the things that makes human languages different from all other species’ communication systems. Try to think of some other examples of recursive structures that we’ve already seen.
So if adjunction is recursive, you’ve probably already figured out that it can happen over and over again within a single phrase. Every time we add an adjunct as sister to the bar level, we add another bar-level as its mother, to which we could add another adjunct as its sister, which adds another bar level as its mother, and so on. So an x-bar phrase can have 0 or 1 complements, and it can have either 0 or 1 specifies, but because adjuncts are recursive, it could theoretically have an infinite number of adjuncts.
We’ve got a pretty clear idea of what complements do: they complete the meaning of a head. And the specifier position is a special position for subjects. So why do we need adjuncts? Well, like complements and specifiers, adjuncts are optional: a phrase might have one or more, or it might have no adjuncts. Adjuncts often add extra information that’s not totally necessary for the meaning of the sentence, the kind of information that’s often contained in APs or PPs, like where an event happened or how it happened. Because adjuncts are optional, they can often be moved or even removed altogether without changing the grammaticality of the sentence. And many adjuncts can appear on either side of their x-bar sister, whereas in English, complements pretty much always come after their sisters and specifiers come before. Let’s look at some examples of adjunct phrases.
In this sentence, Sam bought shoes yesterday, the phrase yesterday is giving us extra information about when the buying happened, so it’s adjoined within the verb phrase headed by bought.
In this next one, Sam bought new shoes yesterday, the adjective new is giving us extra information about the noun, shoes, so it’s adjoined within the noun phrase that has shoes as its head. Notice that this AP is still in adjunct position: it’s sister to N’ and daughter to N’, but it happens to come before its sister instead of after.
And look at all the adjuncts in this one: Ted snored loudly for several hours at night. We know that the verb snore is an intransitive verb: it doesn’t take anything as its complement, so the head has no sister. But then there are three separate adjunct phrases, each of which gives us extra information about the snoring: the AP loudly is sister to V’ and daughter to another V’ node.The PP for several hours is sister to V’ and daughter of another V’ node. And the PP at night is sister to V’ and daughter to another V’ node. I’ve drawn these phrases with triangles; that’s just a shorthand that indicates that we’re not depicting the full inner structure of these phrases.
One piece of evidence that these phrases are adjuncts and not specifiers is that we can rearrange them in the sentence without changing the meaning or the grammaticality of the sentence.
Ted snored loudly for several hours at night.
Ted loudly snored at night for several hours
Ted snored for several hours at night, loudly.
If any of these phrases were complements, we wouldn’t be able to move them around, because a complement is always sister to the head, so it has to be right beside the head. But because adjunction is recursive, an adjunct always introduces another bar-level that can accommodate another adjunct.
So from now on, when you’re drawing trees, you don’t just have to decide whether each phrase goes in a complement or specifier position, but you also have to consider whether it might be an adjunct.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=176
1. Which tree diagram correctly represents the question, “Could you hand me those scissors?”
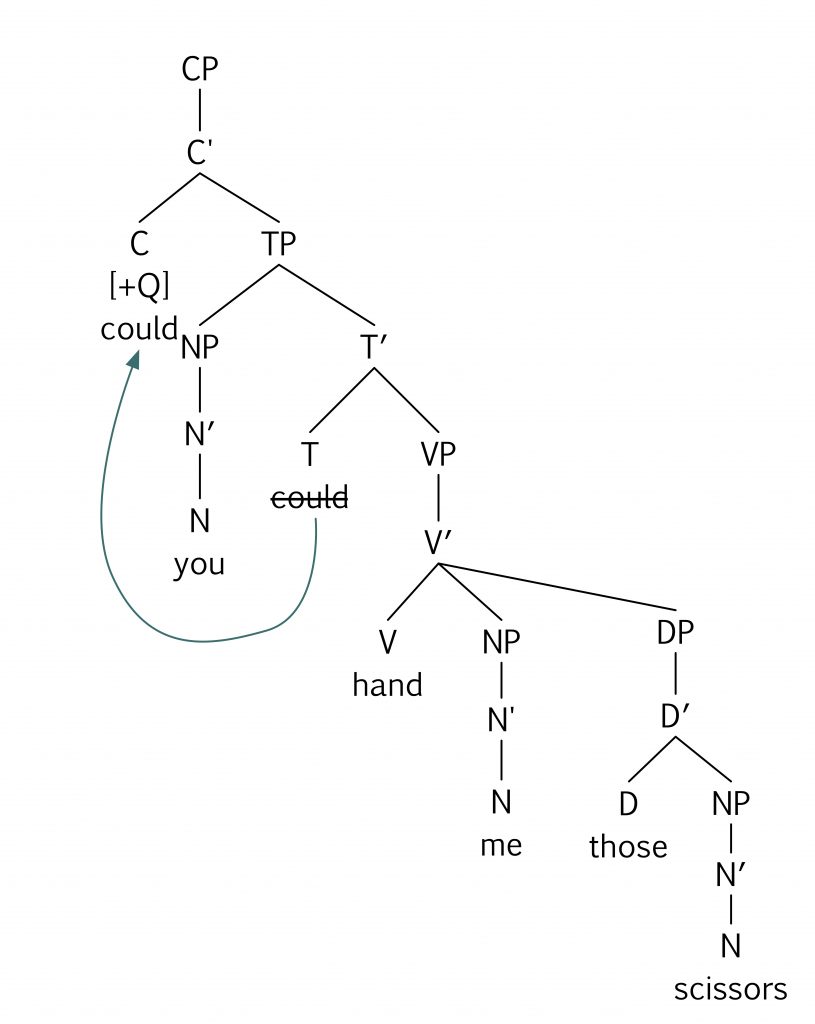
2. Which tree diagram correctly represents the question, “Does Suresh like Ethiopian food?”
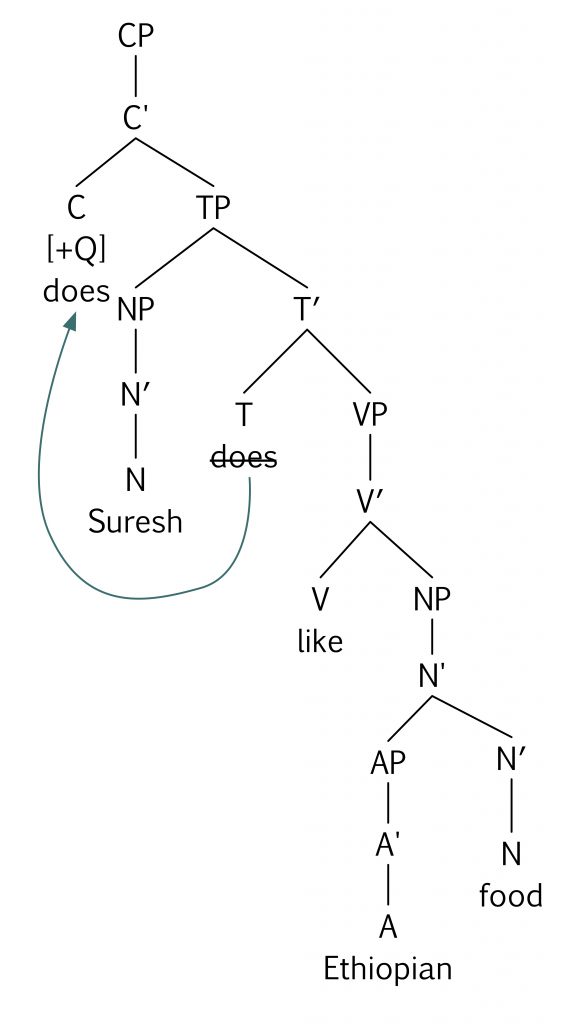
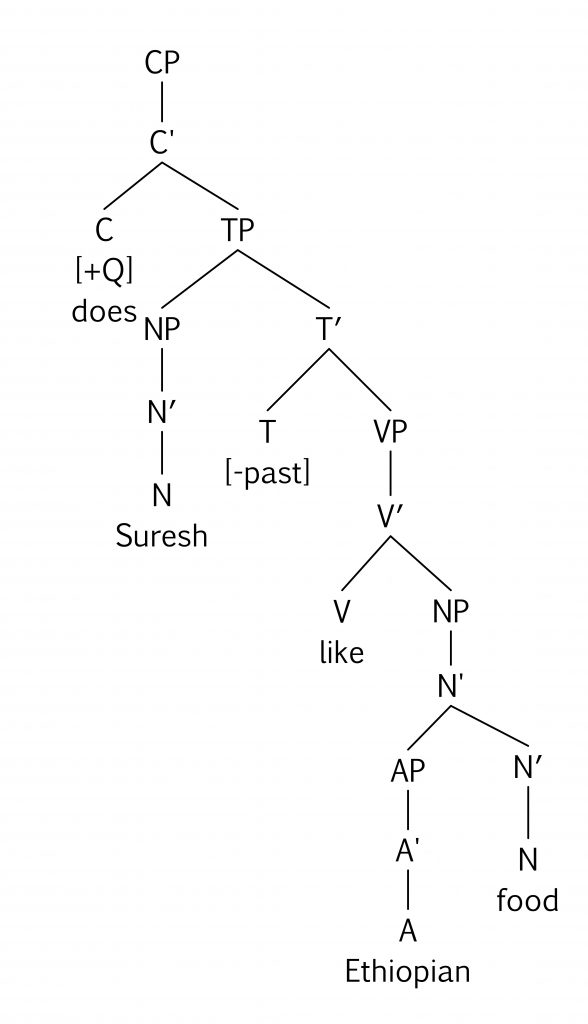
3. Which tree diagram correctly represents the question, “Will the Habs win the Stanley Cup?”
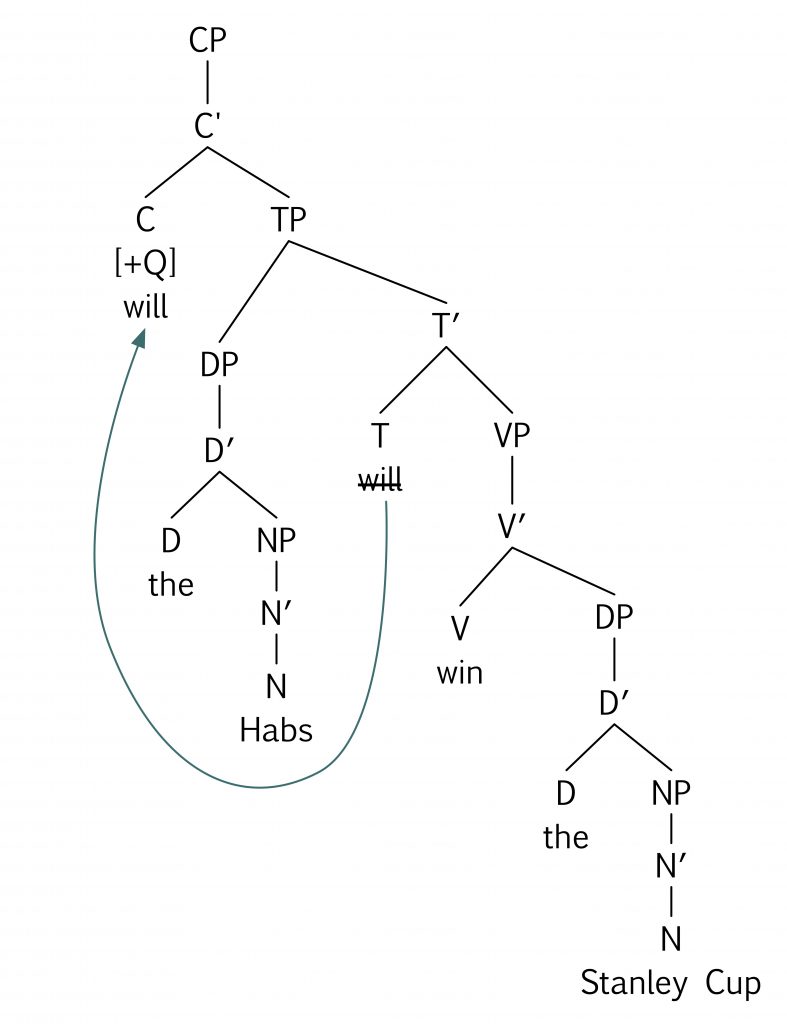
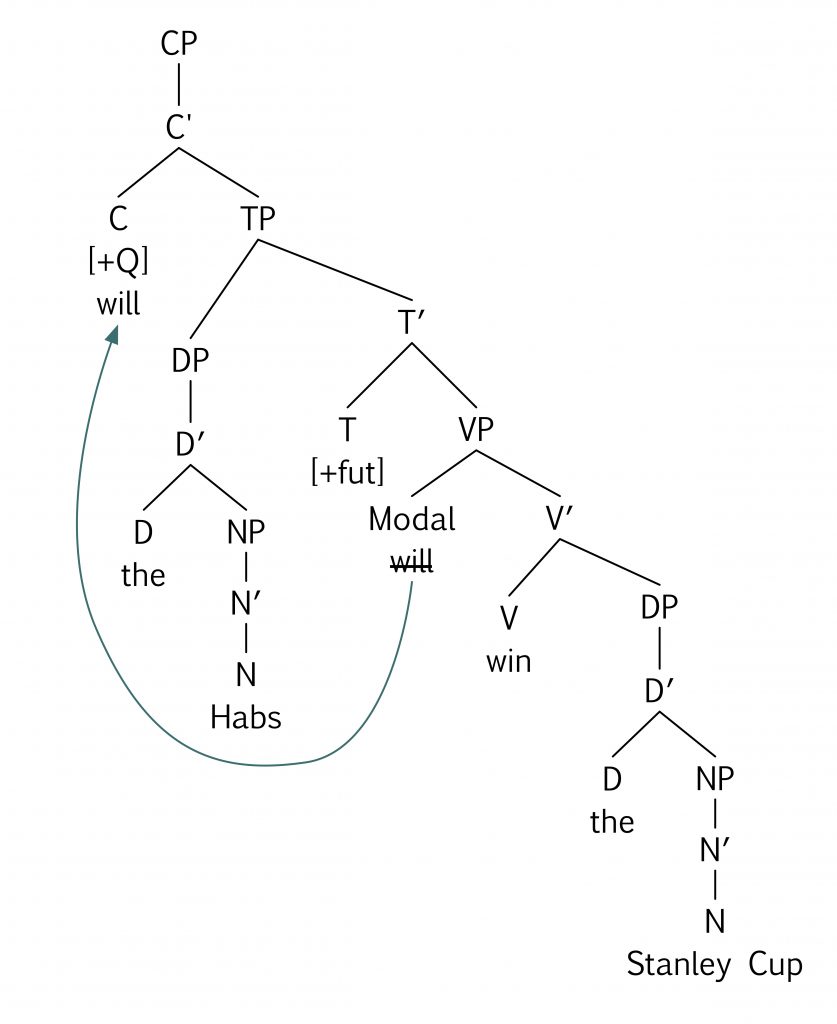
We’ve developed a model of the mental grammar that says that we draw words, morphemes, and morphosyntactic features from our mental lexicon, and then the operation MERGE combines all these items into a grammatical x-bar structure. In this unit, we’re going to look at another operation of the mental grammar, called MOVE, which takes a part of a sentence and moves it somewhere else in the sentence. But why would we want to do that? Let’s look at some examples to figure it out.
Let’s take our now-familiar sentence, Ann hopes that the Leafs will win. Hope is one of those verbs that takes a whole clause as its complement, and that clause is introduced by the complementizer that in C-head position. But what if Ann isn’t hoping, what if she’s asking whether there’s any possibility of her hopes being realized? If she’s asking instead of hoping, the complementizer that doesn’t work as well here. It’s grammatical if we use the complementizer if. I’m going to suggest that the reason the complementizer that doesn’t fit very well in this position is because the verb head ask doesn’t just subcategorize for a complement clause — it’s even pickier than that! The verb ask subcategorizes for a question clause. And the difference between a regular complement clause and a question clause is that a question clause has a [+Q] feature in the C-head position.
So we’re seeing another instance of a morphosyntactic feature occupying a head position. The strange thing about features is that they don’t get pronounced. We know that morphemes and words link up a form (either spoken or written) with a meaning. But features have meaning and don’t have any form of their own. The tense feature does its job by making sure that its complement has the right form. And one way that the [+Q] feature does its job is by making sure that the thing in the C-head has the right form. So if is ok when the C-head has a [+Q] feature in it, but that is not so good.
There’s another way that the [+Q] feature can make itself noticed, though. In English, if we want to ask a question, we don’t do it like this: If the Leafs will win? How do we form that question when it’s not embedded inside another clause? Of course, it’s Will the Leafs win? How did that modal will get from its position between the subject and the main verb up to the beginning of the sentence? Here’s where the operation MOVE comes in.
The theory claims that the operation MERGE generates this structure for the question. This looks just like the declarative sentence, The Leafs will win, except that it has a [+Q] feature in the C-head position. That [+Q] feature needs people to know that it’s there; it’s not like the null complementizer that doesn’t mind being silent: it changes the meaning of the sentence so it wants to be pronounced. For questions that are main clauses themselves, it’s not grammatical in English to just stick a question complementizer into the C-head position. So instead, the operation MOVE comes along, picks up the modal from the T-head position, and moves it up to the C-head position.
But when the modal moves from T up to C, the T position doesn’t disappear from the tree. Instead, the thing that moved leaves behind a little footprint or shadow of where it used to be. In the theoretical literature, it’s called a “deleted copy” or a “trace” — the idea is that it’s still there in the T-head position in our mind, even though we pronounce it up in the C-head position.
Notice that now we’ve got two levels of representation in our syntax. MERGE generates the underlying form of a sentence, what we’ll call the Deep Structure. And then MOVE comes along and, well, moves things, to give us the Surface Structure. A lot of the sentences that we’ve been looking at so far have the same deep structure and surface structure, but when we look at questions, we can see that a sentence can have some systematic differences in how it’s represented at the two levels.
One thing I want to point out is that when we observe sentences, and when we make grammaticality judgments to observe whether a sentence is grammatical or not, what we’re observing is always the surface structure. The Surface Structure is the form of the sentence that we speak: it’s the form that’s out there in the world. We can’t ever observe the Deep Structure; that’s the form of the sentence that exists in our minds. But some of the things that we observe about Surface Structures allow us to conclude that the Deep Structure does exist in our mind and that it’s related in a systematic and predictable way to the Surface Structure. We can represent the relationship between Deep and Surface Structure using a tree diagram.
Just to make this idea about levels of representation clearer, let’s look again at these sentences. The idea is that when these two sentences, one a question and one a declarative sentence, are generated by MERGE, they have almost the exam same Deep Structure. The only difference between their Deep Structures is that the question sentence has a [+Q] feature in C and the declarative doesn’t. The declarative sentence is pretty much ok, so it doesn’t need the MOVE operation to do anything, so its Surface Structure is the same as its Deep Structure. But the question sentence needs to get its [+Q] feature expressed, so MOVE comes along and forms a Surface Structure that’s different from its Deep Structure. So the two sentences that were almost the same in their Deep Structures have one crucial difference between them in their Surface Structures.
We saw that when a sentence has a modal in the T-head position, that modal can move up to the C-head position to support a [+Q] feature. What happens when we want to form a question from a sentence that doesn’t have a modal in the T-head position? What about a sentence like this one? Samira phoned.
We know that the T-head node has a tense feature in it. In a declarative sentence, that tense feature makes sure that the V-head in its complement has the right feature — in this case, the past tense form phoned. But we certainly don’t form a question from this sentence by asking, “Phoned Samira?” What happens in this kind of sentence is that we bring the auxiliary do into the T-head position. Because in this case the tense feature is [+past], do becomes its past-tense form did. Now that the past tense feature is on the auxiliary, it won’t be on the lexical verb, so the verb phoned in V-head just takes its bare form phone. And then to get the [+Q] feature supported, MOVE takes did from the T-head position and moves it up to the C-head position, leading to the Surface Structure, “Did Samira phone?”
Your challenge now is to think about how our mental grammar forms yes-no questions for sentences that have non-modal auxiliaries in them. What do the Deep Structure and Surface Structure look like for each one? Try to figure it out!

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=184
1. Which tree diagram correctly represents the Deep Structure for the question, “Who did Brenda see at the gym?”
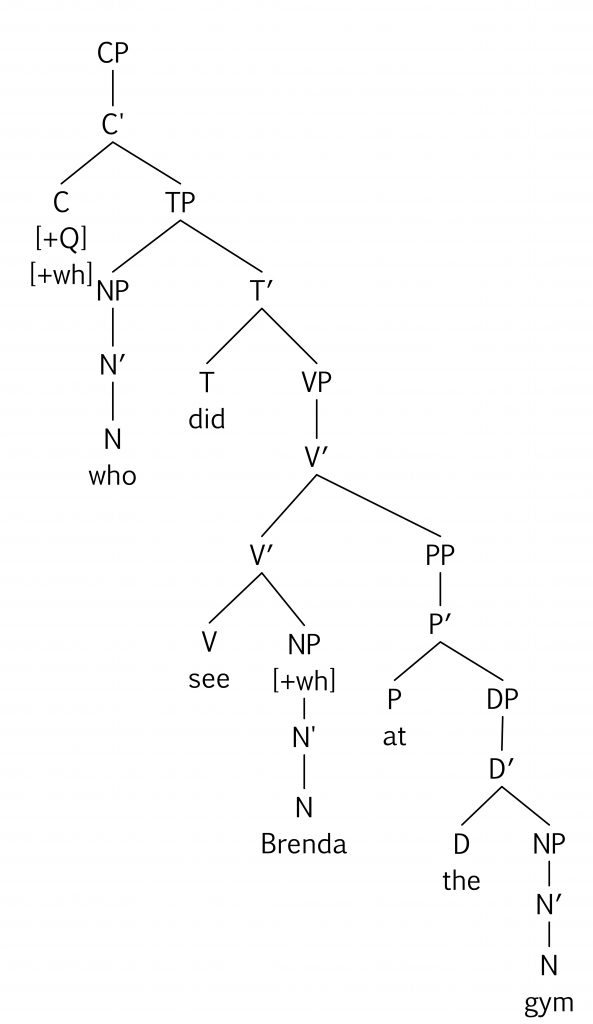
2. Which tree diagram correctly represents the Surface Structure for the question, “Where did you get that hat?”
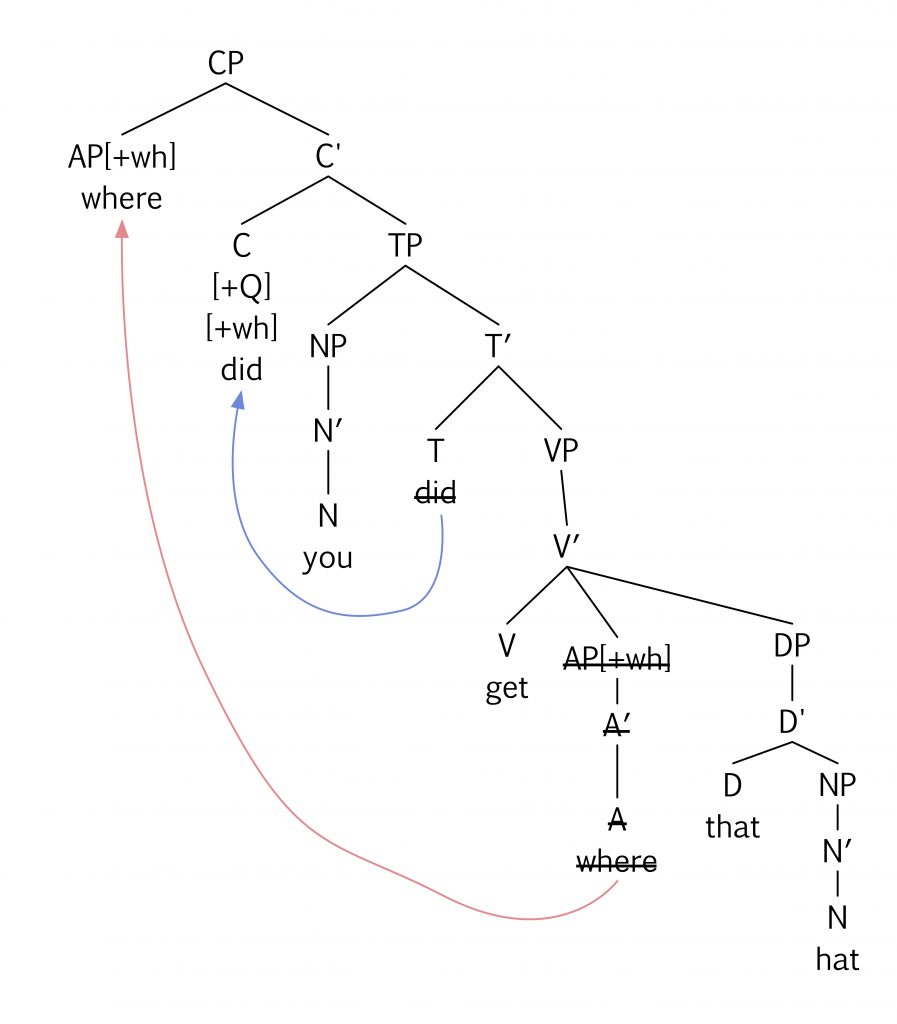
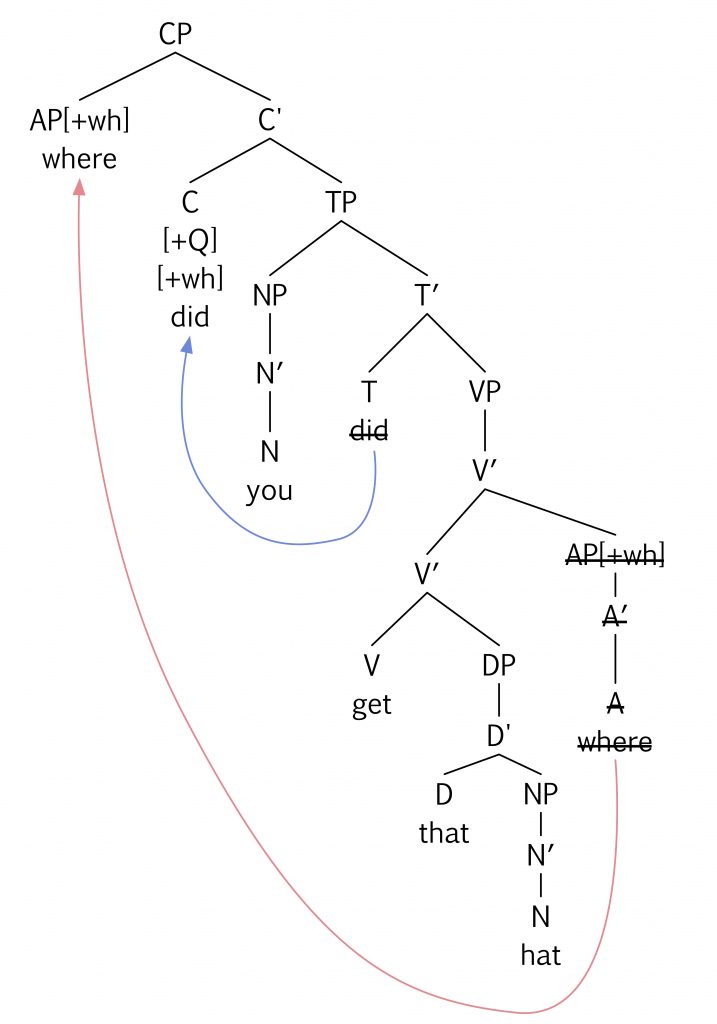
3. Which tree diagram correctly represents the Surface Structure for the question, “Why should I trust you?”
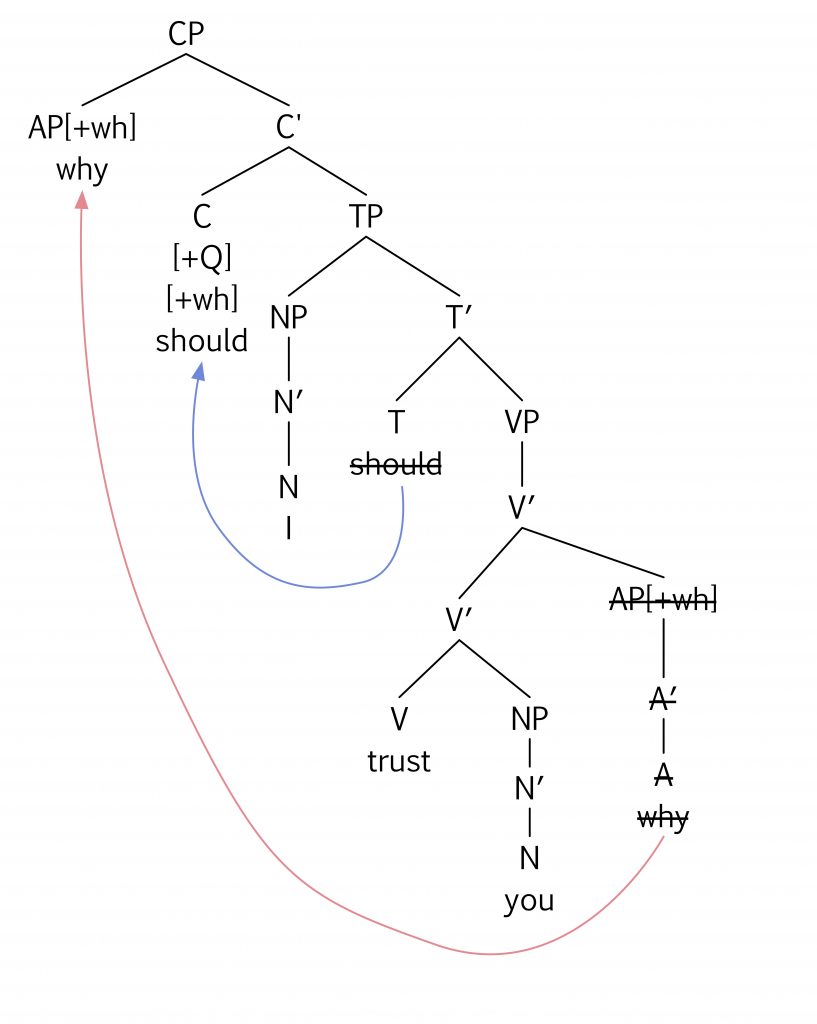
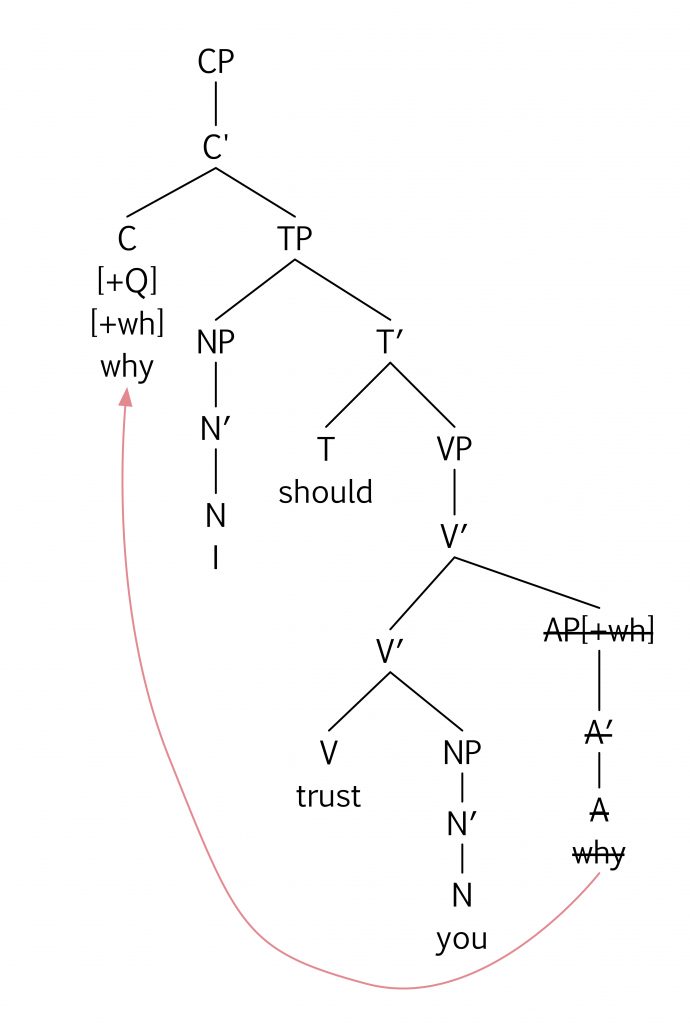
In the last unit, we extended our model of the syntax component of the mental grammar. The idea is that we draw words, morphemes and features from our mental lexicon, and the operation MERGE combines them using X-bar principles. The structure that MERGE generates is called a Deep Structure; it’s the underlying form of a sentence that we hold in our minds, but it’s not always exactly like the form that we speak out loud. For some sentences, a second operation, MOVE, takes some elements from the Deep Structure and moves them to another position in the Surface Structure.
The MOVE operation that we’ve seen so far takes a head and moves it to another head position, leaving a trace behind. For obvious reasons, this kind of movement operation is called head movement, and the primary job that head movement does is to form yes-no questions. For this question, Has Faiza eaten lunch yet?, there’s only a small set of possible answers that are grammatical: yes, no, I don’t know, maybe.
But of course, yes-no questions aren’t the only kinds of questions we ask in English. Take a look at these questions:
What is Ramesh cooking?
Who is he cooking for?
When is Leela arriving?
Where did he buy the ingredients?
Why is he making samosas?
How do they taste?
These questions don’t take Yes or No as their answers, they take phrases.
What is Ramesh cooking? Samosas.
Who is he cooking for? Leela.
When is Leela arriving? In an hour.
Where did he buy the ingredients? At the store.
Why is he making samosas? Because Leela loves them.
How do they taste? Delicious!
We call these wh-questions because most of the English words that we use in these questions are spelled with “wh”. Notice that how counts as a wh-word even though it doesn’t have the letter “w” in it.
What we’re observing here is the Surface Structures of these wh-questions. What might their Deep Structures be? To figure that out, let’s think about what the corresponding declarative sentence would be: imagine the situation where we’re answering each question with a full sentence.
Ramesh is cooking samosas.
He is cooking for Leela.
He bought the ingredients at the store.
Our theory claims that in the Deep Structure of a wh-question, the wh-phrase is generated in the position that it would occupy if it were the answer to the question. In other words, the Deep Structure of the sentence, What is Ramesh cooking is really, Ramesh is cooking what. That wh-word what is a pronoun that stands in for the Noun Phrase that refers to what he really is cooking. In the situation where we’re asking this question, we don’t know that the answer to the question is samosas, so we need a question word that lets us refer to the samosas without knowing their identity. The wh-word what does that job and the idea is that the structural relationship between the verb cooking and the pronoun what is the same as the structural relationship between cooking and samosas.
Let’s see how it looks in a tree diagram. Here’s the declarative sentence, Ramesh is cooking samosas. The samosas are the direct object: they’re the NP in the complement of the verb cooking. And in this declarative sentence, the Surface Structure and the Deep Structure are the same. But if we didn’t know what Ramesh was cooking, and we wanted to ask the question, MERGE generates a slightly different Deep Structure, like this.
Notice that the C-head contains a [+Q] feature because we’re going to be asking a question, and a [+wh] feature because the question is going to be a wh-question. Also notice that this wh-phrase, what, has a wh-feature on it too.
So do we form the surface structure by moving what up into the C-head position? There are two reasons that’s not going to work. The first is obvious: we know, from observing our own grammaticality judgments, that, What Ramesh is cooking is not the surface form of our sentence! And the second reason is for the sake of the theory: C is a head position, so it would mess up the consistency of our theory if we allowed a phrase to move into a head position. Besides, we’re going to need that C head position for something else very soon.
The landing site for wh-movement is a position we haven’t yet used, it’s the specifier of CP, sister to C-bar and daughter to CP. The idea is that moving a wh-phrase into the specifier of CP supports the wh-feature in C.
Now, of course, this still isn’t the right Surface Structure for this sentence. What still needs to happen? We still have this [+Q] feature in C-head that needs to get supported as well, so in this wh-question, in addition to the wh-movement of the wh-phrase up to the Specifier of CP, we also have head-movement of the auxiliary from V to T to C. And that leads to the grammatical Surface Structure, what is Ramesh cooking?
So we’ve now seen two different ways that the MOVE operation works. For head movement, it’s a head that moves, and it moves to another head position. For wh-movement, it’s a whole phrase that moves, and it ends up in the Specifier of CP. So when you’re depicting movement, always check that you’ve got the right kind of node moving to the right position.
Now it’s time for you to practice. Look back at these other wh-questions we generated. These are the Surface Structures of these questions. Try drawing trees to represent the Deep Structures of these sentences, and then draw the movement operations that generate the Surface Structure.
When we form a question that includes a modal auxiliary, the modal moves from the T-head position to the C-head position:
Could you could read this for me?
When a sentence contains no auxiliary, only a lexical verb, it appears that the lexical verb cannot move out of its V-head position. So we’ve proposed that the auxiliary do enters at the T-head position and then moves up to the C-head position:
Did you did see her tattoo?
*Saw you saw her tattoo?
One piece of evidence that do enters the sentence at the T-head position and moves to C-head, rather than just entering at the C-head position, is that it bears the tense feature of the sentence: if the tense is [+past], then we observe the form did, but if the tense feature is [-past], we observe the form do or does. Another piece of evidence is that whatever verb follows the inserted do is in its bare form, not its [-past] or [+past] forms:
Did she talk to Darren?
*Did she talks to Darren?
*Did she talked to Darren?
Does she speak Italian?
*Does she speaks Italian?
*Does she spoke Italian?
Both of these observations suggest that the inserted do gets its tense morphology from the tense feature (either [+past] or [-past]) in the T-head.
English also uses do-support to form negated sentences, which follow the same pattern: sentences with modals don’t need do, but sentences with lexical verbs and no auxiliaries do need do:
I could not believe that rumour.
*I did not could believe that rumour.
*She speaks not Italian.
She does not speak Italian.
If we accept that not is in a fixed position between T-head and its VP-complement, then the distribution of do makes sense. Just like in questions, the evidence suggests that lexical verbs cannot move out of their V-head position up to the T-head position.
This pattern of how do behaves in questions and negative sentences gives us a clue about how the other non-modal auxiliaries, have and be, behave.
Notice that the verb be can always move up to C-head in questions, both when it’s a genuine auxiliary:
Are you are going to the concert?
Was she was joking about that?
And when it’s the only verb in the sentence:
Are you are serious?
Is this is the place?
Likewise, be appears before not both when it’s an auxiliary and when it’s the only verb:
You are not are going to the concert.
She was not was joking about that.
You are not are serious.
This is not is the place.
But have seems to have two different patterns of behaviour. When it is a genuine auxiliary, it behaves like be. It can move up to C-head in questions:
Have they have moved to Texas already?
Had she had already heard the news?
And appears before not in negated sentences:
They have not have moved to Texas already.
She had not had already heard the news.
But when have is the only verb in the sentence, it behaves like a lexical verb. It can’t move up to C-head and can’t appear before not.
*Has she has five sisters?
*Have you have a headache?
*She has not has five sisters.
*You have not have a headache.
Instead, when have is behaving like a lexical verb, it needs do-support.
Does she have five sisters?
Do you have a headache?
She does not have five sisters.
You do not have a headache.
From all of this evidence, we can conclude that MERGE treats these three kinds of heads differently:
Modals are generated in T-head, from where they can move to C-head if necessary to support a [+Q] feature.
Be is generated in V-head, but moves up to T-head (to the left of not) and from there up to C-head if necessary
Have is generated in V-head, and can move up to T-head and from there up to C- head only if it is an auxiliary (that is, only if it has a VP complement). But if it is the only verb in the sentence (and has no VP complement), then it behaves like a lexical verb.
Lexical verbs in English are generated in V-head and cannot move to T-head or C-head.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=188
1. Which of the following illustrates the position of the trace in the wh-question What did Christina order at Chipotle?
2. Which of the following ungrammatical sentences gives evidence that unpronounced traces exist in our mental representations of sentences?
3. Predict which sentence would lead to more eye movements to a picture of a rabbit after the verb chase:
We’ve been working with a theory that says that the operation MERGE generates a Deep Structure. For this wh-question, Who did Lucy invite to wedding, the Deep Structure looks like this. This wh-pronoun who refers to whoever it is that Lucy invited, and it is generated in this position in the complement of the Verb head, which is exactly where the noun phrase complement would be if we know who it was that Lucy invited. The preposition phrase gives us more information about the event of inviting, and it’s adjoined at the V-bar level. Because this is a wh-question, there’s both a [+Q] feature and a wh-feature in the C-head position.
Then the operation MOVE does its work.The wh-phrase moves up to the Specifier of CP, where it can support the wh-feature in C. Then do comes into the T-head in its past-tense form, did, then moves up to the C-head position.
One element of this theory that we’ve been taking for granted so far has to do with the trace that’s left behind when something moves. When we speak a sentence, we pronounce words in their Surface Structure positions, but we don’t pronounce anything in the Deep Structure position. But when we draw the tree, we show the deleted copy in that Deep Structure position, to suggest that, in the underlying representation, in our mental grammar, there’s something unspoken occupying that position.
There is some linguistic evidence for the existence of traces in our mental grammar. We’re claiming that there’s a trace in this position in the complement of invite. Notice that it’s not possible for any other phrase to occupy that position: if we try to put another noun phrase in the complement position, we can observe that each attempt is ungrammatical.
There’s also some psycholinguistic evidence for the existence of traces. The evidence comes from what’s called a visual world experiment. In this kind of experiment, a person’s eye-movements are measured using a device called an eye-tracker. The eye-tracker records where their eyes move while they listen to a spoken paragraph and look at a visual scene. The spoken paragraph goes like this:
This story is about a boy and a girl. One day they were at school. The girl was pretty, so the boy kissed the girl. They were both embarrassed after the kiss.
The idea behind a visual world experiment is that you look at what’s being mentioned. So when you hear the boy, your eyes move to the picture of the boy, and when you hear the girl, your eyes move to the picture of a girl.
At the end of this paragraph, one group of listeners heard a wh-question, Who did the boy kiss that day at school? A different group of listeners heard the same paragraph, but followed by a yes-no question, Did the boy kiss the girl that day at school?
These two sentences are similar in their structure, but they have a crucial difference. In the complement of the verb position, the yes-no question has an overt noun phrase, the girl. In that same position of the wh-question, there’s a trace, a deleted, unpronounced copy of the moved wh-word.
The researchers focused on this exact position in the spoken question: they observed where the participants’ eyes moved after the verb kiss. They compared how often the participants looked at the girl vs. how often they looked at the boy. In the yes-no question, when they heard the verb kiss, people looked at the boy 11% more often than to the girl, maybe because the boy is the one doing the kissing. But in the wh-question, when they heard the verb kiss, people looked to the girl 21% more than to the boy.
In both scenarios, the boy kissed the girl. But people’s eye movements differed in the two conditions. We know from previous studies that eye movements are quite closely synchronized to what’s being mentioned in the discourse. In this study, people’s eyes move to the girl not just when the sentence refers to her overtly, but also when the deep structure contains a trace that refers to her. The evidence from this eye-tracking experiment suggests that traces don’t just exist in tree diagrams, but also in our minds.
Exercise 1. The following sentences are taken from Swiss Sonata by Gwethalyn Graham, which is in the Public Domain in Canada. For each sentence, use as many constituency tests as are appropriate to determine whether the underlined portion is a constituent of that sentence.
Exercise 2. For each of the following sentences, identify the subcategory of each verb and identify the grammatical role of each NP.
Exercise 3. Draw tree diagrams consistent with x-bar principles to illustrate the structure of each of the sentences in Exercise 2.
Exercise 4. Draw tree diagrams consistent with x-bar principles to illustrate the Deep and Surface Structures of the following questions:
Chapter 8 introduced a theory that the syntax component of our mental grammar is quite simple: It consists of only two operations, MERGE and MOVE. The operation MERGE does exactly one thing, namely, it combines words and features to create x-bar structures. X-bar theory claims that every phrase in every sentence in every language of the world is an x-bar phrase. There are only two kinds of things in x-bar phrases, heads and other phrases. Inside a given phrase, another phrase can occupy the position of complement, specifier, or adjunct. The structure that MERGE generates is the Deep Structure of a sentence, which exists in our mind. The operation MOVE takes the Deep Structure and moves some words or phrases to a new position in the Surface Structure of the sentence, which is the form of the sentence that we speak and observe. When MOVE operates, it always moves heads to other head positions, and phrases to other phrase positions. When wh-phrases move, their Surface Structure position is always SpecCP. And the very useful notation of tree diagrams allows us to illustrate how Deep Structures and Surface Structures are represented in our minds.
This chapter considers the connections between syntax and semantics, in other words, between how a sentence’s structure is organized in the mind, and what it means. The notion of compositionality is introduced, that is, the idea that a sentence’s meaning arises not just from the meanings of the words, but also from the way those words are combined. We also see that, even though syntax and semantics are intimately connected, there are some components of semantics that are independent of the syntax, and that this independence is reflected both in how sentences behave and in our brain responses.
When you’ve completed this chapter, you will be able to:
In Chapter 8, as we learned to draw tree diagrams to illustrate how sentences are represented in the human mind, we thought about Deep Structure as the place where meaning is assigned and calculated. For example, in a question sentence like, “What are the kids eating for lunch?”, we claim that the word what is related to the verb eating in the same way that eggs and eating are related in the declarative sentence, “The kids are eating eggs for lunch.” The relationship between eating/eggs and between eating/what arises at Deep Structure, where eggs and what are both in the complement of the verb. In our theory, a sentence’s meaning is correlated directly with the sentence’s syntax.
This idea is a core one in linguistics: the meaning of some combination or words (that is, of a compound, a phrase or a sentence) arises not just from the meanings of the words themselves, but also from the way those words are combined. This idea is known as compositionality: meaning is composed from word meanings plus morphosyntactic structures.
If structure gives rise to meaning, then it follows that different ways of combining words will lead to different meanings. When a word, phrase, or sentence has more than one meaning, it is ambiguous. The word ambiguous is another of those words that has a specific meaning in linguistics: it doesn’t just mean that a sentence’s meaning is vague or unclear. Ambiguous means that there are two or more distinct meanings available.
In some sentences, ambiguity arises from the possibility of more than one grammatical syntactic representation for the sentence. Think about this example:
Hilary saw the pirate with the telescope.
There are at least two potential locations that the PP with the telescope could be adjoined. If the PP is adjoined to the N-bar headed by pirate, then it’s part of the NP. (Notice that the whole NP the pirate with the telescope could be replaced by the pronoun her.) In this scenario, the pirate is holding a telescope, and Hilary sees that pirate.

But if the PP is adjoined to the V-bar headed by saw, then the NP the pirate is its own constituent, and with the telescope gives information about how the pirate-seeing event happened. In this scenario, Hilary is using the telescope to see the pirate.

This single string of words has two distinct meanings, which arise from two different grammatical ways of combining the words in the sentence. This is known as structural ambiguity or syntactic ambiguity.
Structural ambiguity can sometimes lead to some funny interpretations. This often happens in news headlines, where function words get omitted. For example, in December 2017, several news outlets reported, “Lindsay Lohan bitten by snake on holiday in Thailand”, which led a few commentators to express surprise that snakes take holidays.
Another source of ambiguity in English comes not from the syntactic possibilities for combining words, but from the words themselves. If a word has more than one distinct meaning, then using that word in a sentence can lead to lexical ambiguity. In this sentence:
Heike recognized it by its unusual bark.
It’s not clear whether Heike recognizes a tree by the look of the bark on its trunk, or if she recognizes a dog by the sound of its barking. In many cases, the word bark would be disambiguated by the surrounding context, but in the absence of contextual information, the sentence is ambiguous.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=199
1. What label best describes the thematic role of the underlined NP?
The guard chased the intruder.
2. What label best describes the thematic role of the underlined NP?
The wind slammed the door shut.
3. What label best describes the thematic role of the underlined NP?
The guard followed the intruder.
We’ve spent a lot of time thinking about the structure of sentences. We’re now turning our attention to what sentences mean. Sentences usually describe events or states in the world. And events usually have participants: the people or things that play a role in the event. Usually, noun phrases are used to refer to the participants in an event. It turns out that, even across events that are quite different from each other, some participants share some elements of meaning.
Take a look at the underlined phrases in each of these sentences.
Mina tore the wrapping paper.
Sam ran a marathon.
The students studied for their exam.
Neeraja waited for the bus.
Carlos ate the rice.
We can see that the grammatical role of each of these is a subject: They’re all in the specifier of TP. Semantically, the events that each sentence describes are quite different: tearing is different from running which is different from studying or waiting or eating. But even across these different events, the participants described by the underlined noun phrases all share some semantic similarities: all of them choose to take part in the event, all of them are causing the event to happen. Let’s look at another few sentences.
Mina tore the wrapping paper.
A nail tore her skirt.
The fabric tore.
All of these sentences have the same verb and they all describe a tearing event. And all the underlined phrases have the grammatical role of subject, but they don’t share the same semantic properties. In the first sentence, Mina is the one who causes the tearing event to happen: you can imagine her gleefully tearing the paper open to see what’s inside. In the second sentence, the nail is sort of responsible for the tearing, but it certainly doesn’t choose to make it happen. And in the third sentence, the fabric is the thing that the tearing happens to, not the participant that makes the tearing happen. So even though all three of these NPs are subjects, they don’t all share semantic properties.
Remember that we use grammatical roles to label the syntactic position of a noun phrase in a sentence. We’re now going to introduce a new kind of label, called thematic roles. We can use thematic roles to identify common semantic properties of the participants in events. An important thing to notice about thematic roles is that they are independent of grammatical roles. In this pair of sentences,
Kavitha cooked this lovely meal.
This lovely meal was cooked by Kavitha.
the grammatical role for Kavitha is different: Kavitha is the subject of one sentence but an oblique in the other. But semantically, Kavitha’s role in the cooking event is the same in both sentences. We say that Kavitha’s thematic role is the agent.
The kinds of participants that we label as agents tend to have three properties: usually, they are volitional, meaning they choose to participate in the event. They’re sentient, that is, they’re aware of the event, and often they’re the ones that bring the event about or cause it to take place. Let’s look back at that tearing event.
Mina tore the paper.
The paper tore.
Again in these sentences, the paper has two different grammatical roles: it’s the direct object in the first sentence but the subject of the second, but semantically its role as a participant in the tearing event is the same in both: it’s the thing that the tearing happens to. Its thematic role is called a theme, or in some books, you’ll see it called a patient. Theme participants typically undergo events, that is, events happen to them. They’re affected by events, and often they change state or position as a result of an event.
Take a minute and try to think of some sentences that describe events that have agent and theme participants. They’re probably the two most common thematic role labels, and in fact, one theory of semantics says that every participant is either an Agents or Themes, just to a greater or lesser degree. But it can also be useful to have labels for some other kinds of participants, and the grammars of many languages encode other semantic properties besides those two.
Some languages make a morphological distinction between an animate agent and an inanimate cause. In a sentence like, The hurricane destroyed the houses., the hurricane is clearly responsible for the destroying event, but it’s not sentient or volitional — the hurricane isn’t choosing to bring about the destroying. Likewise, in The movie frightened the children, the movie isn’t really a typical agent. We label these inanimate participants with the label cause A cause participant shares the agentive property of causing an event to happen, but it’s not aware of the event and doesn’t choose to cause it, because the cause is inanimate.
In this sentence, The knife cut the bread, would you say that the knife is a cause participant? Certainly, the knife is inanimate, and it’s not aware of the cutting event, but it’s also not really causing the cutting to happen, is it? There’s some unnamed agent who must be using the knife to cut the bread. We could label the knife as an instrument. An instrument is the participant that an agent uses to make an event happen.
Many languages have special morphology to indicate the location of an event, like in these sentences:
The Habs won the game at the Forum.
The kids ran through the sprinkler on the lawn.
The parade travelled around the neighbourhood.
The noun phrases the forum, the lawn and the neighbourhood all have the thematic role of location.
So we’ve got labels like cause, instrument, and location to describe some of the roles that inanimate participants typically have in events. I want to return to animate participants to look at one more important role. Let’s look at the human participants in these sentences:
Phoebe tripped on the curb.
Sun-Jin won the lottery.
The movie frightened Farah.
If Phoebe tripped on the curb, it doesn’t seem quite right to label Phoebe as an agent — presumably, she didn’t choose to trip on the curb, even if she is aware of it, and she isn’t really the cause of the tripping event; the curb is. And no matter how badly you might want to win the lottery, you can’t really cause it to happen, so Sun-Jin isn’t a great example of an agent either. Likewise, if we say that the movie frightened Farah, Farah isn’t exactly a theme; yes, the frightening is happening to her, but she’s not necessarily changed by it, and she is aware of the event.
Let’s label these participants with the thematic role of the experiencer. Experiencers are like the middle ground between agents and themes. They are animate and sentient, so they’re aware of events happening, but they don’t necessarily choose or cause events to happen; events happen to them. Because experiencers have this in-between status, they can show up either as subjects or as objects, like in these examples:
The children were scared of the clowns.
The clowns frightened the children.
And we could say that Phoebe and Sun-Jin are experiencers of their tripping and winning events: they don’t cause the events to happen, but they are aware of the events happening.
To sum up, thematic role labels capture the semantic properties of participants in events, independent of the syntactic position of the noun phrase. Just because something has the grammatical role of a subject doesn’t mean it will necessarily have the thematic role of agent and vice versa. There’s a fair amount of argument in the literature about exactly how many thematic role labels are necessary to capture the relevant patterns of behaviour in the languages of the world, with proposals ranging from two to about fifteen thematic roles. We’ll settle on the middle ground and use six thematic role labels:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=201
1. Is the following sentence in the active or passive voice?
The patient was diagnosed with alopecia.
2. Is the following sentence in the active or passive voice?
Eileen was convinced that her appointment had been cancelled.
3. Is the following sentence in the active or passive voice?
The children had been invited to a tea party.
Many sentences describe events that involve two participants: an agent and a theme. And it often happens that the agent role shows up in subject position and the theme role in object position. These sentences illustrate that common pattern: the subjects are all agents and the objects are all themes.
Ilona broke an icicle.
Zainab introduced the guest speaker.
The manager fired the receptionist.
It’s a common tendency across languages for the agent to occupy the subject position, but of course not all agents are subjects, and not all subjects are agents. These next sentences describe pretty much the same events as the last three, but the noun phrases in subject position are not agents.
The icicle broke.
The guest speaker was introduced by Zainab.
The receptionist got fired.
So while the usual pattern is for agents to be mapped onto subject position and themes onto object position, most languages also have a way of reversing that usual mapping. In English, the strategy we have involves both morphology and syntax and is called a passive structure. A passive sentence reverses the usual mapping between thematic roles and grammatical roles.
In this first sentence, The police arrested the burglar, the police are the agent and they’re in subject position, and the burglar is the theme in direct object position.
In the second sentence, The burglar was arrested by the police, the semantic relationship of the police and the burglar to the arresting event is the same: the police are still the agent and the burglar is still the theme. But their grammatical roles are different. We can use this passive structure to reverse the usual pattern and focus our attention more on the theme than on the agent.
The reversal that happens in a passive sentence works the same even if the thematic roles aren’t the classic agent and patient. Take a look at this pair of sentences,
The exhibit impressed the audience.
The audience was impressed by the exhibit.
In the first sentence, which is an active sentence, the usual mapping plays out not with an agent and theme, but with a cause participant in subject position and an experiencer in the object position. When we use a passive structure in the second sentence, the thematic roles of the participants don’t change, but their grammatical roles do.
So how can you tell if a sentence is in the passive voice? It’s easy: a passive sentence will always have some form of the verb be, followed by a past participle. All of these examples are passives.
The burglar was arrested.
The children were invited to the party.
This flight is expected to arrive on time.
The candidate is being prepared for the debate.
I am appalled by your behaviour.
But if you have the verb be plus a present participle, or if you have the verb have plus a past participle, then those aren’t passives. All of these sentences are in the active voice:
The report is calling for changes.
The burglar was planning a heist.
The children were behaving poorly.
The hosts have invited several guests.
The dog had eaten all the Halloween candy.
A passive structure is a morphosyntactic strategy that English uses to reverse the usual mapping of thematic roles onto grammatical roles. Some languages accomplish this reversal with morphology on the verb or with morphology on the noun, but it’s pretty common for a language to have a strategy in the morphology or syntax that has this effect in the semantics of a sentence.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=203
1. What kind of ERP is likely to be observed in response to this sentence?
The children’s feet have grown so I bought them some new spoons.
2. What kind of ERP is likely to be observed in response to this sentence?
Elias told the coach that he wanted to learn to swam.
3. What kind of ERP is likely to be observed in response to this sentence?
Before the dinner party, Isla spent a long time in the cooked.
When we started talking about semantics, we observed that a sentence’s syntax influences its semantics, because of the principle of compositionality. For example, we saw that a given string of words can have two different meanings if it has two different grammatical syntactic structures. And yet, we also observed that syntax is independent of syntax. A noun phrase that has the semantic thematic role of Agent often occupies the syntactic position of Subject, but not all Agents are Subjects, and not all Subjects are Agents!
The division of labour between thematic roles and grammatical roles is some evidence that syntax and semantics are represented differently in our minds. There’s also evidence from neural imaging to show that our brains process semantic information differently from syntactic information. This evidence comes from electroencephalography or EEG. Electroencephalography uses electrodes to measure electrical activity on a person’s scalp from which scientists can draw conclusions about the person’s neural activity. The particular EEG technique that gets used in neurolinguistics is ERPs or event-related potentials, which measure the timing of the neural response to a particular event, like a sound or a word.
When we’re observing ERPs, we always do so by comparing responses to different kinds of events, and the usual comparison is between events that are expected and events that are unexpected. For example, a sentence like, “She takes her coffee with cream and …” sets up a very strong expectation in your mind of what the next word will be. If the next word that arrives in the sentence matches your mind’s expectation, then the electrical response at your scalp will look something like this: the baseline condition. But if the next word that shows up violates your mind’s expectation, then compare your brain’s response: We observe a spike in negative voltage about 400 milliseconds after that unexpected word appears.
This response is called an N400. The N in N400 stands for a negative voltage, and the 400 indicates that this spike in negative voltage shows up, on average, about 400 milliseconds after the event. The N400 was first observed in 1980 by Kutas & Hillyard and has been replicated hundreds of times since then. It’s clear from all these studies that the particular kind of event that leads to an N400 response is a word that is unexpected in the semantic context.
The N400 is the brain’s response to an unexpected or surprising event, but not every kind of surprise will produce an N400. In other words, we have expectations about things besides the meanings of sentences. Think about a simple sentence like, “The bread was…” If that sentence finishes with “eaten”, that fits our mind’s expectation, and this is the baseline brain response. Now, what expectation do you have for this sentence, “The ice cream was in the..”? You probably expect a noun to come next, to follow the preposition and determiner. But if what comes next is not a noun but a verb participle, this violates your mind’s expectation. Notice that the word eaten is semantically consistent with ice cream, but is not consistent with the syntax of the sentence: determiners are followed by nouns, not verbs. So the brain’s response is a positive voltage about 600 milliseconds after that unexpected word: a P600.
When we’re using language in real time — either reading or listening — our mind sets up expectations about what’s going to happen next. If what happens next violates our semantic expectations, the brain’s response is an N400. And if what happens next violates our syntactic expectations, the brain’s response is a P600.
These two different brain responses give us further evidence that syntax is independent of semantics in our brains!

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=205
1. French uses morphology indicate whether nouns, adjectives and determiners are masculine or feminine. If an L1 speaker of English is learning French, what kind of transfer are they likely to experience in learning this property of French grammar?
2. Russian does not have definite or indefinite determiners like English a and the. If an L1 speaker of Russian is learning English, what kind of transfer are they likely to experience in learning this property of English grammar?
3. Russian groups nouns by their grammatical gender, either masculine, feminine or neuter. Look again at the facts about French presented in Question 1. If an L1 speaker of Russian is learning French, what kind of transfer are they likely to experience in learning this property of French grammar?
As we’ve been talking about mental grammar, we’ve concentrated almost entirely on the mental grammar of your native language — the language you learned to speak in childhood, in your home. Linguists refer to your native language, your first language, as your L1. But many people in the world speak more than one language, and many of those people learned a second or third language in a different way from their L1. Any language that you learned after childhood, whether you learned it in school, using software, by travelling or immigrating somewhere, is called an L2 (even if it’s really your third or fourth language).
Learning an L2 is different from learning an L1 for a couple of different reasons. One is that, obviously, the language learner is not a child, so their cognitive processes might be different from those of a child. L1 learning happens by being immersed in a language environment, and most of the learning is unconscious, without overt teaching. L2 learning often happens with a lot of conscious effort: studying and memorizing and practicing.
But of course, the biggest difference between L1 learning and L2 learning is that when you start learning an L2, you already know at least one other language. The mental grammar of your L1 can influence the mental grammar that you’re developing for your L2: this is called transfer. Transfer can be helpful in L2 learning or it can pose a challenge. If your L1 includes a structure that’s similar to a structure in the L2, then you might experience positive transfer, which facilitates learning the L2: you can transfer what you know from L1 and apply it to the L2. But if the structures that you’re learning in L2 are different from those in your L1, then you might experience negative transfer: the knowledge from your L1 could make it more difficult to learn the new structures in the L2. And of course, you might experience both positive and negative transfer from your L1 to different parts of the grammar of your L2.
One theory of second language acquisition predicts that we would observe differences between native speakers and beginner L2 learners, but as the L2 learners become more proficient, their mental processes should become more and more native-like — that is the mental grammar of a fluent L2 speaker should look very similar to the mental grammar of an L1 speaker of that language. We can use the tools of psycholinguistics and neuroscience to learn about the mental grammars of L2 learners. Let’s take a look at some of the evidence.
Several studies have compared N400 effects in L1 and L2 speakers of a language. Remember that the N400 is an electrophysiological response that our brains show when a word is semantically unexpected in a given context. The brains of native speakers of English show a negative voltage about 400 milliseconds after a semantically unexpected word (socks), compared to an expected word. But what do the brains of non-native speakers show? What do we see in L2 learners?
A 2001 paper by Anja Hahne compared L1 speakers of German with L1 speakers of Russian who had moved to Germany in their 20s and had been living there and studying German for an average of six years. The experiment used fairly simple German sentences like these ones:
Die Tür wurde geschlossen / The door was being closed.
Der Ozean wurde geschlossen / The ocean was being closed.
Obviously, the word closed is a reasonable way for the first sentence to end but is a pretty unexpected way for the second sentence to end. So it’s not surprising that the native speakers of German showed an N400 in response to sentence 2 compared to sentence 1. The L2 speakers, the ones who had started learning German in their 20s, also showed an N400 to sentence 2. Hahne concluded that words that are semantically unexpected cause “essentially similar semantic integration problems in native participants and second-language learners” (Hahne, 2001: 263). In other words, the evidence from the N400 suggests that the lexical semantic component of an L2 learner’s mental grammar is not too different from that of an L1 grammar.
Now, we know that there’s a whole lot more to mental grammar than just the meanings of words. What can ERPs tells us about morphology and syntax? Remember that native speakers’ brains often show a P600 response to sentences that are syntactically unexpected. For many years, studies that looked at the P600 in L2 learners seemed to suggest that adult language learners never really approached native-like proficiency in their L2 morphosyntax: the P600 response to syntactic violations was significantly delayed or not there at all in these late learners. But some more recent research has suggested that maybe those earlier studies just didn’t give the learners enough time to learn their L2 — of course, their mental grammar wasn’t native-like if they hadn’t been learning the language for very long.
A 2013 study by Harriet Bowden and her colleagues looked at L1 English speakers who started learning L2 Spanish in university. They compared learners who had completed first-year Spanish to learners who had completed more than three years of university Spanish and had spent a year abroad. And they included a control group of L1 speakers of Spanish. The researchers presented Spanish sentences that violated syntactic expectations about word order like these ones. Sentence 1, “I have to run many miles this week” has the expected word order, while sentence 2, “I have to miles many run this week” is unexpected in its word order: the quantifier many comes after the noun miles, and that whole complement phrase comes before the verb run. Sentence 2 is ungrammatical in Spanish.
As you’d expect, the native speakers of Spanish showed a P600 in response to the ungrammatical sentence. But so did the advanced L2 learners: their ERP response was the same as that of the L1 Spanish speakers. It was only the beginning learners, the ones who had had only a year of Spanish, who showed an atypical P600: it was a smaller response and more diffuse. The researchers concluded that “University foreign-language learners who take L2 classes through much of college and also study abroad for one or two semesters …show evidence of native-like brain processing of syntax” (Bowden et al., 2013: 2508).
So this study suggests that one year of studying a language maybe isn’t enough to achieve native-like fluency, and three years of study including a year of immersion allows a learner to approach native proficiency, but the researchers also wondered whether the kind of language-learning makes a difference to learners. If you’re learning a language in university, you probably spend three or four hours a week in the classroom, and maybe two or three more hours each week studying. But that’s not the only way to learn a language.
A study in Montreal looked at university students who were L1 speakers of Korean and Chinese who were enrolled in a nine-week intensive English L2 course. These learners were studying, practising, using English at least 8-10 hours a day, five days a week, for nine weeks. The researchers tested the learners on sentences with morphosyntactic violations in the tense features on the verb, like these ones:
1a. The teacher did not start the lesson / 1b. The teacher did not started the lesson.
2a. The teacher had not started the lesson / 2b. The teacher had not start the lesson.
Notice that in 1b and 2b, the verb has unexpected morphology on it. A native speaker of English would show a P600 response to 1b and 2b in comparison to 1a and 2a. In this study, the researchers measured learners’ ERP responses at the beginning of the course and after the nine weeks, and they also asked the learners to judge whether the sentences were grammatical. At the beginning of the course, none of the learners showed P600s in response to the syntactically unexpected sentences, and they also weren’t very successful at deciding whether sentences were grammatical or ungrammatical. After the nine-week course, all of the learners showed P600 responses to the syntactically unexpected sentences, and the learners who scored highest on the grammatical judgments showed the largest P600s. This study suggests that even short-term, intensive L2 learning can help a learner develop a mental grammar that approaches that of a native L1 speaker.
And the results of all of these studies tell us that L2 language learners can achieve fluency that compares to that of a native speaker; it just takes lots of training to get there!
Exercise 1. Groucho Marx has famously joked, “One morning I shot an elephant in my pyjamas. How he got in my pyjamas I don’t know.” Draw the two tree diagrams that correspond to the two separate meanings of the sentence, “I shot an elephant in my pyjamas.”
Exercise 2. The following sentences are taken from The Venturesome Voyages of Captain Voss, by John Claus Voss, which is in the Public Domain in Canada. For each sentence, identify the thematic role of each NP.
Because I had found, from the day I first met Dempster on Cocos Island till he died, that he was a straightforward and reliable man, I have decided to place confidence in you. I now ask, can you and will you procure for me a vessel and fit her out properly, sail with me to Cocos Island and assist me to put the treasure on board and take it to Victoria?
The wind freshened considerably and hauled round to the west, at the same time throwing up a lively choppy sea, which made the little vessel jump about worse than a bucking horse.
All three ships under full sail passed Cape Flattery towards evening, shaping their courses toward the south-west with a fresh easterly breeze.
Exercise 3. The following paragraph is taken from Swiss Sonata by Gwethalyn Graham, which is in the Public Domain in Canada. The verb component of several clauses has been underlined. For each underlined set of verbs, say whether it is passive or active.
Her eyes reached Miss Ellerton, the games mistress, who, after a few impatient glances in Mlle Tourain’s direction, had got up from her chair and wandered over to the french windows where she was standing now, holding the curtain back with one hand and looking over the lovely grey town where dusk already lurked here and there. Some of the light which yet remained in the outer world was caught in her hair and outlined her small features so that the others, sitting patiently in their chairs, were aged by their contrasting dullness. Amélie Tourain leaned forward a little and switched on her desk light, then remained motionless looking at the girl by the window. An unaccountable conviction that Miss Ellerton was in some way connected with the turmoil in her mind had complete possession of her.
Exercise 3. Think about your experience of learning an L2. What parts of your L1 grammar led to a positive transfer to your L2? What parts of your L1 created a negative transfer to your L2? Consider phonetics and phonology as well as morphology and syntax.
The crucial idea in this chapter is the idea of compositionality: the syntactic structures that our mind uses to combine words play a vital role in the meaning of sentences. If a sentence has more than one grammatical tree structure, then it will be ambiguous. We also learned in this chapter that there are components of semantics that are not dependent on syntax. Linguists use thematic role labels to capture the semantic properties of participants in events, independent of the grammatical roles of the NPs. And while most languages have a typical mapping between the grammatical role of subject and the thematic role of agent, this is not the only possible mapping, and languages all have ways of overriding that mapping. Evidence from neurolinguistics suggests that syntax and semantics are processed differently in the brain, both in native speakers and in L2 learners.
This chapter looks at the ways that the meanings of words are represented in our minds. One way that our mind represents word meanings is by collecting up memories of all the thing in the world that a word can refer to, that is the denotations or extensions of a word. But beyond just a set of exemplars, our minds also have mental definitions that allow us to decide whether a given thing the world could be referred to by a certain word. These mental definitions are called intensions, and this chapter explores how they might be represented in our minds, and how psycholinguistic experiments can give us evidence for how intensions are represented.
By the end of this chapter, you’ll be able to:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=212
1. Sidney Crosby, Wayne Gretzy, and Maurice Richard, are all ______________ of the phrase hockey player.
2. Has pages, binding, and contains writing are all __________________ of the word book.
3. Head of state, lives in the White House, and American are all ______________ of the phrase President of the United States.
We’re now starting to consider how our minds represent the meanings of words. If someone asked you, “What’s the meaning of the word pencil?” you’d probably be able to describe it — it’s something you write with, it has graphite in it, it makes a mark on paper that can be erased, it’s long and thin and doesn’t weigh much. Or you might just hold up a pencil and say, “This is a pencil”. Pointing to an example of something or describing the properties of something, are two pretty different ways of representing a word meaning, but both of them are useful.
One part of how our minds represent word meanings is by using words to refer to things in the world. The denotation of a word or a phrase is the set of things in the world that the word refers to. So one denotation for the word pencil is this pencil right here. All of these things are denotations for the word pencil. Another word for denotation is extension.
If we look at the phrase, the Prime Minister of Canada, the denotation or extension of that phrase right now in 2017 is Justin Trudeau. So does it make sense to say that Trudeau is the meaning of that phrase the Prime Minister of Canada? Well, only partly: in a couple of years, that phrase might refer to someone else, but that doesn’t mean that its entire meaning would have changed. And in fact, several other phrases, like, the eldest son of former Prime Minister Pierre Trudeau, and the husband of Sophie Grégoire Trudeau, and the curly-haired leader of the Liberal Party all have Justin Trudeau as their current extension, but that doesn’t mean that all those phrases mean the same thing, does it? Along the same lines, the phrase the President of Canada doesn’t refer to anything at all in the world, because Canada doesn’t have a president, so the phrase has no denotation, but it still has meaning. Clearly, denotation or extension is an important element of word meaning, but it’s not the entire meaning.
We could say that each of these images is one extension for the word bird, but in addition to these particular examples from the bird category, we also have in our minds some list of attributes that a thing needs to have for us to label it as a bird. That mental definition is called our intension. So think for a moment: what is your intension for the word bird? Probably something like a creature with feathers, wings, claws, a beak, it lays eggs, it can fly. If you see something in the world that you want to label, your mental grammar uses the intension to decide whether that thing in the word is an extension of the label, to decide if it’s a member of the category. The next unit will look more closely at how our intensions might be organized in our minds.
One other important element to the meaning of a word is its connotation: the mental associations we have with the word, some of which arise from the kinds of other words it tends to co-occur with. A word’s connotations will vary from person to person and across cultures, but when we share a mental grammar, we often share many connotations for words. Look at these example sentences:
Dennis is cheap and stingy.
Dennis is frugal and thrifty.
Both sentences are talking about someone who doesn’t like to spend much money, but they have quite different connotations. Calling Dennis cheap and stingy suggests that you think it’s kind of rude or unfriendly that he doesn’t spend much money. But calling him frugal and thrifty suggests that it’s honourable or virtuous not to spend very much. Try to think of some other pairs of words that have similar meanings but different connotations.
To sum up, our mental definition of a word is an intension, and the particular things in the world that a word can refer to are the extension or denotation of a word. Most words also have connotations as part of their meaning; these are the feelings or associations that arise from how and where we use the word.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=214
1. Thinking about the category animals for most speakers of Canadian English, giraffe is probably:
2. Thinking about the category pets for most speakers of Canadian English, tarantula is probably:
3. Choose the set of features that best defines chair.
In the last unit, we saw that one important piece of a word’s meaning is the intension: the attributes or properties in your mind that you use to decide whether a thing in the world can be labelled with that word. In this unit, we’ll think about how those intensions might be organized in the mind.
One theory suggests that intensions might be organized in our minds as sets of binary features. So the intension for the word bird might be made up of features like [+living], [-mammal], [+wings], [+eggs], [+flying]. The intension for the word fish would have some features that are the same as the intension for bird, like [+living], [-mammal], [+eggs]. But the intension for fish would have [+wings] and [-flying]; instead, it would have [+swimming]. Some of these features could be shared across intensions for words that refer to quite different things in the world, so the intension for the word airplane, for example, probably includes [+wings] and [+flying], but [-alive].
The nice thing about using feature composition (also known as componential analysis) to represent intensions is that it can capture some of these similarities and differences across categories of things in the world using the simple, efficient mechanism of binary features. It may well be that our intensions for words describing the natural world are made up of some binary features. But can you think of any problems with this way of organizing meanings? Think about a penguin. A penguin is a member of the category of things that can be labelled with the word bird, and it shares some of the features of the intension for the word bird: it’s a living thing, it has wings, it lays eggs. But a penguin can’t fly. In fact, a penguin has the feature that’s associated with our intension for fish: it can swim. So it’s definitely a bird, but it definitely doesn’t have all the features associated with the intension for bird. If our intensions were organized in our minds just as binary features, then we wouldn’t be able to represent the meaning of the word penguin in our mind, but clearly, we do have an intension for the word penguin. So how might penguins be represented in our minds?
Another theory of intensions suggests that we have fuzzy categories in our minds. These categories contain exemplars, which are basically our memories of every time we’ve encountered an extension of the word. Some members of the category are prototypical exemplars: they have all the typical attributes of members of that category, so they’re near the center of the category. For most North Americans, a robin is about as prototypical as it gets as an exemplar of the category bird. Some exemplars are more peripheral: they have fewer of the defining attributes and they might have some attributes that aren’t typical. So a penguin, for example, is more peripheral because it doesn’t fly, and an ostrich is peripheral because it’s so darn big. Because the category has fuzzy boundaries, we might even have some exemplars in our mind that aren’t really members of the category at all, but share some attributes with category members, like bats: they’re small and they fly, but they’re not actually birds. In the next unit, we’ll talk about some of the evidence we have that our intensions might be organized in fuzzy categories with prototypes.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=216
1. Which of the following words would we expect to prime a target word carrot?
2. Which of the following words would we expect to prime a target word happy?
3. Which of the following words would we expect to prime a target word week?
In the last unit, we suggested that intensions for word meanings might be organized in our minds in fuzzy categories. Our minds construct categories of things based on our experience in the world: each time we encounter an extension of a word, we count it as an exemplar in that fuzzy category. There is some evidence from psychology and psycholinguistics that our mind really does represent a difference between prototypical category members and peripheral members. For lots of categories, we have some instincts about what kinds of exemplars are prototypical and what kinds are peripheral. When we give somebody the name of a category and ask them to name an exemplar, people from a given language community are remarkably alike in the first things they name as exemplars. If your mental grammar for English is like mine, then perhaps your prototypical bird is a robin, your prototypical fruit is an apple, and your prototypical tool is a hammer.
In a behavioural study of word recognition, participants saw a word appear on a screen and had to say the word out loud. This is called a rapid naming task. Some of the words referred to prototypical exemplars of their particular category and some of them referred to peripheral exemplars. The prototypical and peripheral exemplars were all mixed up in the experiment, but when the researchers measured how fast people had been able to name the word that they saw, the found that people were faster to name the prototypes than the peripheral exemplars.
The same researchers used these words in a lexical decision task. In this kind of task, a word appears briefly on a screen, and the person’s job is just to decide whether it’s a word or not, and say Yes or No. So if the word pants appears on the screen, you would say “Yes”, because it’s a real word in English. But if pfonc appears, you say “no”, because that’s not a word of English. What the researchers found in the lexical decision experiment was, again, that people are fast to make a decision about a word if it refers to a prototypical category member, and slower to make the decision if the word refers to a peripheral member.
These findings indicate that the process of recognizing a word is easier and faster if that word refers to a prototype. We can interpret these findings to mean that our intensions for categories are made up of exemplars and that prototypical exemplars have a privileged position in our intensions.
So that’s a couple of examples of psycholinguistic tasks we can use to observe how words are processed in our minds: a simple naming task, and a lexical decision task. There’s an additional task that we can combine with each of these, to allow us to investigate relationships between different words. That task is called priming. A primed lexical decision task works like this: First, a word appears on the screen for a very short length of time: that word is called the prime. The prime disappears, and then a second word appears on the screen. This word is the target, and the participant makes a lexical decision about the target. The prime word can have an influence on how quickly people make their lexical decision about the target word.
For example, in one condition, the prime might be doctor and the target nurse. In another condition, the prime could be apple and the target nurse. As you might expect, people are faster to make their lexical decision to nurse when it’s primed by doctor than when it’s primed by apple. When we observe this faster lexical decision, we interpret that to mean that these two words are connected to each other in our minds.
Over the years, psychologists and psycholinguists have conducted thousands of experiments on priming, and the results of these experiments show us how words are related to each other in our minds. The scientific literature has shown priming between words that are members of the same category, for words that are synonyms, antonyms, and even for words that describe things that share attributes. For example, an orange and a baseball aren’t members of the same category, but they’re both spheres, so they can prime each other.
Looking at all these and many other priming effects, we can conclude that those semantic relationships play an important role in how the meanings of a word are organized in our minds.
Exercise 1. For each of the following words or phrases, describe an intension and an extension:
Exercise 2. Consider the category vehicle. Generate a list of at least twelve words that refer to members of the vehicle category, and rank them in order of most prototypical to most peripheral category members. Discuss, briefly, what features make something a prototypical vehicle. What features do the peripheral members have (or not have) that make them less prototypical?
In this chapter, we examined the different ways that the meanings of words might be represented in the mind. Evidence from psycholinguistics tells us that prototypes play a role in the organization of our intensions, since words that refer to prototypical things are accessed more quickly than words that refer to peripheral things. Through our experience of encountering various extensions in the world (that is, various exemplars that belong to categories), our minds build up intensions for word meanings. These intensions allow us to categorize new exemplars that we encounter.
As unit 11.1 shows, Canada’s settler government has, for decades, engaged in deliberate strategies to eliminate the languages spoken by Indigenous peoples. Indigenous people have been working for years to try to preserve their languages by increasing the number of people who can speak them, and since the 2015 report of the Truth and Reconciliation Commission, the federal government has more openly acknowledged the importance of these efforts. People with Linguistics training can play a valuable role in language preservation and revitalization efforts, by helping to document the language and by contributing to the development of teaching materials for the languages.
By the end of this chapter, you’ll be able to:

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=223
A lot of our attention so far has focused on English, which is convenient because it’s a language that we all know, but we can learn a lot about mental grammar by looking at other languages. Canada has an incredibly rich and diverse history of languages that were spoken by Aboriginal peoples long before European settlers arrived. Linguists estimate that there were more than two hundred different Indigenous languages spoken in this region, and these languages were quite different from each other — they formed about 15 different language families.
At the time of the 2016 census in Canada, there were still about two hundred and thirteen thousand people speaking about 64 different Indigenous languages from 12 different language families. Some of these languages, like Cree, Inuktitut and Ojibwe, are quite healthy, with thousands of speakers. But many more Indigenous languages are critically endangered — they have only a few hundred or a few dozen speakers who are quite elderly. When those speakers die, the language could die with them.
Why have so many of the Aboriginal languages been lost? It’s tempting to attribute it to economic and cultural pressures — TV shows and books and music are all in English, and everyone wants to speak English to get a job — but it’s not as simple as that. From the time that European settlers first arrived in this region, they engaged in deliberate strategies to try to eliminate First Nations people and their culture and language. The settlers engaged in war with the Indigenous people and brought new germs that caused devastating epidemics. The Europeans took over fertile land to grow their own crops and forced Indigenous people to live in small, confined reserves that could not sustain the crops to feed their people.
And these strategies aren’t just from hundreds of years ago: between the 1960s and the late 1980s, the Canadian government seized thousands of Aboriginal children from their homes and placed them forcibly in foster homes and adoptive homes largely with white families, which meant that the children did not learn their parents’ language. This forced adoption is sometimes called the “sixties scoop”, and it continued the tradition of the residential schools.
The residential school system existed in Canada for more than 100 years, and the last residential school closed in 1996, not very long ago. Aboriginal children were taken from their families and forced to live in quite appalling conditions in schools that were run by the government and by the churches. The person who initiated the system was Sir John A Macdonald, Canada’s first prime minister. He was quite clear that the whole purpose of taking children from their families was to make sure that they grew up without knowledge of their history, language, and culture. Here’s his attitude about children who grow up in their families and communities:
“When the school is on the reserve the child lives with its parents, who are savages; he is surrounded by savages, and though he may learn to read and write, his habits, and training and mode of thought are Indian. He is simply a savage who can read and write.”
And here’s what his plan was:
“Indian children should be withdrawn as much as possible from the parental influence, and the only way to do that would be to put them in central training industrial schools where they will acquire the habits and modes of thought of white men.”
He was completely open about his goals: he wanted Aboriginal children to stop thinking and speaking in the ways they learned in their families and communities, and to start thinking and speaking like white men.
In 2015, Canada’s Truth and Reconciliation Commission issued its report, after years of consulting with survivors of residential schools. The executive summary begins this way:
“These residential schools were created for the purpose of separating Aboriginal children from their families, in order to minimize and weaken family ties and cultural linkages, and to indoctrinate children into a new culture—the culture of the legally dominant Euro-Christian Canadian society.”
The TRC’s Calls to Action acknowledge the crucial role that Indigenous languages will play in achieving reconciliation between Aboriginal people and the larger Canadian population. Here are just some of the Calls to Action.
So there is a need for language preservation, revitalization and teaching. What can linguists do to help with these efforts? Of course the most important thing is to work with Aboriginal communities, to listen to the community members and find out from them what they think would be most valuable.
Some linguists have helped to document Indigenous languages, recording and transcribing speech and stories from native speakers. This is especially crucial when the speakers are elderly and the language is critically endangered. Documenting a language also involves doing phonological, morphological and syntactic analysis to be able to write grammar books and dictionaries for the language. Some linguists have also helped to develop writing systems for languages that didn’t have any written form. If a language has been documented, then linguists can help to create educational resources and curriculum material that language teachers can use, and can help to train language teachers.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=225
I’ve been a language teacher for years, you know, and trying to teach and there’s always been this segment of people out there who “really support what you’re doing” and stuff like that and I’ve gotten into the habit of just ignoring them because their support is verbal; they’re not in my classes; they’re not learning the language. Real support for an Aboriginal language is getting out there and learning that language and learning to speak it, you know, so, to help bring that language back into its own. I don’t expect any community to work towards, you know, sole monolingualism — that’s that’s just not doesn’t make sense — however, bilingualism is a fairly normal way to be with a large percentage of the world’s population. And, and, for, you know, my grandparents, my grandfather was bilingual, you know, and my great-grandparents were bilingual and they could use English when they needed to and they used Mohawk when they needed to and, or by choice or whatever.
I speak Mohawk and English so the thing is I can also, you know, use both languages. I … the difference I guess is that I also read and write Mohawk as well. So I’m a speaker and I’m literate which is the sort of thing that we would want to teach students especially at the university level because there’s a lot of stuff written in Aboriginal languages that are presently not available in English or, you know or probably doesn’t necessarily have to be available in English if they’re speakers of the language.
People have always said you know, “Oh yeah, we know that the language should be in the home.” No! The language should be in the street! If the language is surviving — if the language is truly an important part of being — it’s in the street; it’s in the stores; it’s outside of the home. When you keep the language in the home it dies, because the speakers of the language eventually leave that home and then they go into the street where they’re speaking English all the time and they meet somebody else who is also speaking English and eventually … the next generation is being raised by two English-speaking people and of course then the language is, is gone.
[CA: Would you say that that attitude that says “oh the language is for at home,” is that, is that another legacy of colonialism where it was shameful to speak an Aboriginal language?]
Yeah well let’s keep it.
[CA: Yeah, it’s private, but not outside the house.]
Yeah and the real problem is that when when the language is only spoken in the home especially in contemporary society where people are, spending more and more time at home in front of some sort of technical device — in times past they were out going from home to home and all people were speaking the language and visiting and the language is very much alive — but once it becomes ensconced within the home and people get to the point where, sure they can talk to their parents, but they can’t really understand their neighbours.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=227
One of the things about language is — I understand Mohawk and I speak Mohawk because I’ve heard hundreds of people speaking it.
[CA: Right. So that’s how you learned it, was growing up in the community where it was spoken?]
Yeah I basically grew up with Mohawk and English and as I got to be a teenager I spent a lot more time with the older folks because they were more inclined to be speakers. Also, I find old people a lot more entertaining than younger adults, you know, they no longer have the sort of worries that, and the stress, that younger people have. And the stories, I mean, the really funny thing is that I find with older people, with the old folks, they’re not very trusting, you know you basically have to visit them a lot before you kind of crack that shell and you get access to, to what they what they know. And I suppose to a certain degree that’s self-serving but at the same time these people have got, they’ve got tradition to pass on; their responsibility is to be passing on this stuff and if they’ve decided that well nobody wants to hear that you know and so they stop telling it then it, it dies with them. So I found that spending a lot of time with the older folks you hear a lot of stories.
And the funny thing too about, one of the things that I found with the language is they were a lot more fun in Mohawk than they were in English. They get cranky and grumpy and unhappy when they speak English and I don’t know why because, it just, I had an uncle used to visit and, well, boy I mean this he had a complaint about everything he had a gripe about everything and stuff and it always seemed to be so grating in English but when he was speaking Mohawk we spent a lot more time laughing. Because that was the language of his childhood and that was how he grew up and he’s, you know, he would tell stories from that time where it’s often you know were, were a lot more amusing or a lot more interesting than what he was having to deal with presently in English.
I’ve had students that have come in that have taken a number of years in the immersion program at Six Nations. They seem to have a sense of the language but they’re not speakers. The course that I teach right now is a fairly heavy grammar-based course because I find that if I mean you can you can learn all the vocabulary you want, but if you have no sense of the grammar of the language, how are you going to utilize that vocabulary? What are you gonna do with it? And the thing is that the students that have come in that have some language, they know a lot of vocabulary… can’t do a thing with it! They know how to say expressions; they know dialogues; they know a whole lot of things that I find is, okay, great, so you at least know the pronunciation, which is a good place to start. Anglophones can’t get past what they see written. “Well, but that’s a ‘t’ it’s written as a ‘t’.” I says yeah, it’s pronounced [d].
[CA: And here’s where, actually, thinking of my students the having a bit of Introduction to Linguistics would help to say, well, look, this is a, this is an allophone and it’s voiced in these circumstances and voiceless here, someone who has Intro Linguistics might get that.]
Yup. I had students who will comment on the fact that they’ve taken a linguistics course and it has helped their pronunciation it does make them more aware of it. […]

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=229
What I also do too is that I include culture with the language. I’ll be teaching them a particular word or phrase or expression but then I’ll tell them where it comes from — why it is this way — why we say it that way — why we don’t say this word. I mean, the word nyaweh in Mohawk gets interpreted as ‘thank you’ in English but that’s kind of the beginning and the end of it. We don’t, the reality is, if you follow older tradition, which is the way I was raised, you don’t say nyaweh for every little thing; you don’t use it the way it’s used in English. In English it’s just thank you thank you thank you — it becomes meaningless; it becomes a grunt, quite literally, in the English language, because people just use it so freely that it starts to lose its meaning. In Mohawk, nyaweh is used, or should only be used, between yourself and the Creator even when you say nyaweh, you know you see something beautiful, you see a sunset, a beautiful flower, nice majestic scenery or whatever, stuff like that, then you say nyaweh because now that nyaweh is directed towards the Creator and it’s showing appreciation for what you’re dealing with. When we sit at the table and we eat, the first one that gets up says nyaweh, not for the food, you know, but for, for the opportunity to sit with other people and share food. We’re getting into the habit of using it much the same way it’s used in English — you’ll hear young, young speakers, more contemporary ones that are using or learning the language, they’ll use nyaweh the same way they do and I said, No! (laughter).
[CA: Well I wonder, is there, is there a tension there that, so, on the one hand, you want to honour the traditions and the things you’ve learned from the Elders and from the older people and, on the other hand for a language to stay alive it has to change, right? Is that, so, if people are changing the language some, it’s because it’s still a living language…]
I don’t know — there are certain things that we don’t, we don’t want to change, that we don’t particularly want to update because then it starts to erode our uniqueness. If you’re going to speak Mohawk the way you speak English, why don’t you just speak English? You can update certain things but other things you can’t. Like negating a future situation — in English, you can say, “Oh, it will not snow today!” How presumptive you are! (laughter) Because, just because the sky is blue, but there’s a cloud and you know the clouds — if there’s one cloud there’s another cloud and another cloud and another cloud and by the end of the day we could see snow, which is all within the realm of the “will” because the “will” is in the in future. We cannot negate the future.
[CA: So that’s, so that’s a cultural attitude that shows up in the grammar of Mohawk? That you don’t use negation with the future?]
You can construct a negative future. Nobody does. Fluent speakers don’t. I mean, why would you? You know, because it interferes… We have other ways of kind of getting around it right but … most people just wouldn’t. You just would not say, “it will not snow.” We can create what amounts to it, a negative sort of thing and we use it with the non-definite, which is like saying “it would not” or “there’s a possibility that it won’t” It would not… but the thing is that you cannot directly say, “it *will* not” so we go to a very fuzzy sort of a non-definite situation and we negate that. Cheating in a way but at the same time, it is an important cultural part of the language. I mean, the fact that you have a culture that that doesn’t negate the future — they deal with the future in a different sort of way — so those sorts of things, I think they have to be kept in language because they are the sort of things that add to the uniqueness of a particular language.
Word order in Mohawk. English has a set word order: subject-verb-object. Mohawk… Mohawk’s word order is, is quite literally whatever comes out of your mouth. What joins it all together are pronominal prefixes and that works. But because the pronunciation of Mohawk, the pronunciation of a word in Mohawk is set; however, due to the situation in which that word may occur within, within a statement or sentence, the accent on that word may shift. So okay fine, so if I say kahiatónhsera for “book” then the accent is on tón. Kahiatónhsera, okay fine, but if I say kahiatonhseráke, “on the book” that accent shifted to the penultimate syllable. So accent shifts on a word depending upon where that word occurs. English is a language blessed with one or two syllable words which actually puts English speakers in an odd situation since most of them seem to have a hard time pronouncing a word that has more than one, more than two syllables, (laughter) which makes my name really hard for them, “Oh, Kanatawakhon, oh, I can’t say that!” It’s worse if they see it written.
But the thing is, in Mohawk, word organization, word position is dependent on emphasis, so if I want to say, “The boy is walking on the road,” what am I saying?
“The BOY is walking on the road?” “raksá:’a ire ohaháke“.
or am I saying,
“The boy is WALKING on the road”? “ire raksá:’a ohaháke“.
Or am I saying,
“The boy is walking on the ROAD”? “ohaháke ire raksá:’a“.
So I shift my words around, there’s actually six arrangements of that, the three words and it’s all depending on, on emphasis. Also dependent upon if you’re answering a question. Because, “What did you buy?” “A COAT I bought.” Because the question what is asking, is asking for information which is then placed first which puts it in an emphasized position. That’s a very important part of the uniqueness of a language. So there are three very unique things with the language that we don’t want to, we can’t lose by modernizing it or contemporizing it. The language is set.
The culture that goes with the language … if you stop using a stone axe then eventually the word for stone axe is going to disappear unless for some reason … And then some vocabulary we’ve created in the past that we’ve carried through into the future like oháhsera, “a light” now is used primarily in reference to artificial lighting but originally it referred to something that looked very much like this bone oháhsa with the –ra suffix so then oháhsera just kind of gives the impression or gives the appearance of this particular bone and if you look at that bone and you look like a candle — yeah — so the thing is so we called the candles oháhsera, then lamps showed up. Well, more or less the same shape, oháhsera. Then lights, lamps, you know, living room lamps and stuff showed up, okay, oháhsera. Nowadays oháhsera refers to anything that throws artificial light, you know, ceiling lights, wall lights, the whole bit. So that is a word that has followed through time because even though we had your basic application but the shape kept changing.
[CA: That’s a natural semantic drift that happens in most languages…]
Yeah.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=231
Over the years I’ve been teaching Mohawk since ’91 … ’90-91 and I wanted to, I initially taught the course here, got the opportunity to teach the course because I wanted to see if the text material that I had developed for a language course would actually work. So I had developed a textbook and we used it the first year in that language course — mmmyeah, it did — as I modified it and I did things to it. That one sitting there that’s the most recent within the last five years. There is an audio that goes with that on a USB stick. That’s just the teaching text; there’s another one that’s called Supplements and it’s divided into ten, ten supplement areas, where you’ve got everything about numbers, everything about locations, everything about… And it’s equally as thick as that…
And then the band council back home, they finally got the opportunity to offer the Mohawk language in the public school there, so they wanted me to come home and teach it because I was quite literally the youngest speaker there and we didn’t have a lot of old folks in the community to draw on. So I said okay fine, I’ll, well I went back home and of course they said, “Okay there’s, here’s the Eastern school, here’s the Central School, here’s the Western school and then here’s the main school one, Grades 1, Grade 2, Grade 3 and then 4 to 8 and I drove to each one every day for a half an hour, about a half an hour of language in each one, sometimes 40 minutes. So my first year of teaching was Kindergarten to Grade One — Kindergarten to Grade 8, you know of course having to deal with an attitude all the way through, worst at the 7/8 level because they started to be a lot more like their parents, and a lot more annoying. And then your little guys you know, just soaked it all up and were a lot of fun.
But then, the band council says well here’s, here’s your job, here’s where you’re teaching, and here’s a hundred dollars a week. (laughter) No materials whatsoever, so I bought, I had to buy any materials that I needed for flashcards, for doing things within the class to help the kids learn and that sort of thing but one thing that there wasn’t was a textbook. There was, there was no available materials that they were using and that was pretty much everywhere, so you pretty much had to develop your own material so I started doing more and I got thinking well the language is a lot more than just words. And there are a lot of words that seem to be very much the same.
I taught for five years and about the fourth year came across this book published by Günther Michelson called A Thousand Words of Mohawk and it was all about the roots. And I bought a copy of this thing and I started looking at it, “Oh, wow, this makes so much sense.” So then I started, well maybe that is the better way to teach the language course.
[CA: So he had done the linguistics research to assemble the roots?]
Yeah, he was a linguist himself and of course, a lot of the linguistic work done on Iroquoian languages at the time was for the most part unreadable. (laughter) I didn’t have the education to deal with all that sort of weird and wonderful vocabulary. If I got a book, I had some linguistic stuff on the language, but as long as it provided enough examples that I could, then I could figure out what they were talking about … but … I really needed to have the examples. So I started doing his stuff and then gradually working this into, to doing the class, classroom stuff.
[CA: So it sounds like there could be a valuable role here for people who may not have, who may not know languages, Indigenous languages but know some linguistics to work with speakers of the language to create materials?]
Oh yeah, I think, if they, and if they’re going to be working with speakers they really do have to be somebody who has a sense of the grammar of the language. One of the things I learned how to do by trial and error was, learned how to ask the right question. Because speakers will tell you what comes to their mind. So we say, well what’s the word for “tree”? “Oh, kerhitáke“. Okay, eventually I learned that means “on the tree”. Kerhitákon, eventually I learned that was “in the tree”, and then, you know, they would give me all of these, tkerhitoke, “There’s a tree standing there,” and eventually I figured out that, kérhite was the word for “tree”. Oh, yeah, yeah, you’re telling us kérhite, yeah, that’s “tree”. (laughter)
But the thing is that, and when you’re asking them something, you know, a question like, you know, “I trust him.” You trust him for money? You trust him for what he says? You trust him for what he’s doing? You trust them to get the job done? What? Because those are all different, you know?
And, and the business of using pronominals — we have a subjective, objective and transitive, and they would mix them. Now this is a problem that was happening in the, in the language programs in the schools, is because the fluent speakers were suddenly, oh Aunt Maisie there, she’s a fluent speaker. Yeah, she’s 85 but she can teach these kids — what a horrible thing to do to an old woman (laughter) — but anyway, she could use the money, so. But the thing is that she had, as a fluent speaker she had no sense of the grammar of the language.
[CA: Right, didn’t have the metalinguistic awareness.]
Constantly mixing categories, constantly mixing, you know, mixing things up. “How come you said, wahahní:no yesterday and today you said rohahní:no for ‘he bought’?” They both kind of mean that, wahahní:no, “he just bought it”, rohahní:no, he bought it, but quite a while ago”.
[CA: Yeah, that’s something that my students in, in first-year linguistics struggle with making this, this unconscious implicit knowledge about how their language works and making that explicit. It’s a real challenge. Whatever, I mean, we mostly do it in English but whatever your native language is, it’s hard to become conscious…]
Yeah, so learning – learning to ask the right question, you know and, even when, when doing a sentence, you really have to pay attention to, to how they’re organizing the sentence, how they’re putting it together, and even though when they would say things, I would, “yeah, yeah, I know”. I have a sense of what they were saying, but (laughter), it just, sometimes it was so confusing, sometimes very frustrating, sometimes you would ask three or four different speakers the same thing and they would all tell you something different. Is it because there are four ways to say the same thing or is it not really the same thing but simply refers to similar situations?
Now, I mean, that, that textbook there is all about the grammar of the language — what you use where, how you organize it, what you say when, and stuff.
[CA: And it’s over your years of experience that you’ve assembled…]
Yeah. Over the years I’ve written five different language learning textbooks complete with, with exercises, drills and all the sort of stuff. That also has a book of exercises and drills to go with it. The difference is that is on, on audio, so it’s … you can, you’ll find the exact same textbook on screen which you can highlight the audio and get a pronunciation.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=233
[CA: I mean I was thinking about your students, like, are, are they going to speak Mohawk to their kids when they have kids, do you think?]
I think it’s really up to, up to the student, I mean, they may have thought you know learning the language is difficult. Finding a compatible partner who also speaks the language is going to be the real test. And some of them have, have found partners who, and they have raised kids, they’re raising kids together.
[CA: So are there kids who are growing up who are learning to speak it as they’re growing up?]
Yeah.
[CA: That’s starting to happen more?]
Yeah.
People don’t realize that learning language is a lifelong… I, every now and then I’ll run across vocabulary — oh yeah, wow this word — and then just … learning new vocabulary, words I hadn’t heard before or words that I’d heard but I didn’t have time to figure out the context and so, always in a state of language learning you know even after you’re a speaker.
We need language. I don’t know how we function without language. And nowadays with Native people you know, so much of this, this reconciliation thing going on and that sort of thing. Years ago in my home community, a lot of farmers that lived around the territory also spoke Mohawk. Very minimal in a way and stuff like that because they hired a lot of people from the territory to work on their farms. So they learned Mohawk. They learned it to a degree — you could go into stores in Deseronto and shopkeepers would, you know, would deal with, with the people in Mohawk. Now, it was Mohawk that would be related to the whole buying and selling and this sort of thing that but they did that. Now, to me, that’s an aspect of reconciliation. That’s where two groups have reconciled with each other — okay you’re there, you speak your language but I will learn to speak with you mostly because I want your money — and … we, you know, we’ll speak your language because we need your goods. I mean there’s always a give and take on any, any two groups that have reconciled with each other but I think at the same time, too, when people take time to learn your language, they do have a certain respect.
[CA: That’s what I was thinking — it certainly shows respect, that I value interacting with you enough to do it in your language.]
Yeah, and the ones that want to interact more, learn more of the language.

A YouTube element has been excluded from this version of the text. You can view it online here: https://ecampusontario.pressbooks.pub/essentialsoflinguistics/?p=235
Canada is a bilingual country … and I think if Canada learns to extend itself, we’ll start including more and more Aboriginal languages. I think Canada is, would be better to tout itself as a multilingual country. Because I think when doing that, even if they, if their definition of multilingualism is, is the two founding languages and then the Indigenous languages, you’re still looking at you know like fifty-five languages. And then because the difference, I think too, Native people have to be included in all that because we were here when English and French showed up. Okay, English and French showed up and they created the present-day institutions and stuff like that, okay fine. Everybody else who has come to this country basically has read the brochure and understood that English or French are the languages, therefore come to this country understanding that, okay I’m going to have to learn English or French because that’s how the company is organized, country is organized. Or if maybe I’ll go learn an Indigenous language as well. But the Indigenous languages have to be at the table.
[CA: The English and French arrived and didn’t say oh well we’re gonna have to learn the language that people speak — they said we’re here, now you’re gonna speak our language.]
Yeah, but you know initially they did learn our languages to deal with us because they didn’t have much choice. We had what they didn’t have and when we got to a point where we no longer had what they wanted, and of course, they wanted the land which meant pushing us off anyway, so the respect for the languages and stuff, kind of went out the door. Then it became well everybody here speaks English only. … I find that we need we need to have the languages. I think that gives us a greater sense of who we are — the language!
And, and the thing is that for, for Native people in this country we have spent so many years under the colonial thumb and so many years being convinced that our own languages and our traditions and everything that’s about us is inferior or not as good as … And the thing that I’ve found is that if you’re a Native person you can work your butt off to become as much like you know the non-native Canadian; at the end of the day your skin is still brown and that’s not going to change. If I focus on speaking Mohawk then in the process of learning my language I’m also learning Mohawk culture and what it is to be a Mohawk person and that’s, I think is something that is very important. We’ve gotten into the habit of being Indians or Natives or Aboriginals or Indigenous. Nowadays the word’s ‘Indigenous’. I think I keep telling my students, I said you know, I said, when I was born I was born an Indian but then I became a Native and then I became Aboriginal and then I became First Nations and now I’m Indigenous, yay! You know, Indigenous is the word of the 21st century and I’m sure they’ll find another one, but the word I would really like them to find and stick to is Mohawk, Oneida, Ojibwe, Chippewa. Know us by our nationalities, know us by our distinct cultures, know us by what makes us unique in the world.
Exercise 1. Listen again to the interview with David Kanatawakhon-Maracle in Unit 11.4. At 6:38 of the interview, he describes the trouble that English speakers often have pronouncing his name, Kanatawakhon. Try to transcribe this name in IPA, giving as detailed a narrow transcription as you can.
Exercise 2. Imagine you are working as a linguistic consultant with a community who is working to document their language. What kind of questions would you ask the fluent speakers, to elicit language data?
Exercise 2. Imagine you are working as a linguistic consultant on some audio-recordings of speech from fluent speakers of an Indigenous language. What information would you try to obtain from these audio-recordings? What linguistics skills would you use? Where would you start?
This Chapter included several excerpts of an interview with a fluent Mohawk speaker, David Kanatawakhon-Maracle. In the interview, Dr. Kanatawakhon-Maracle talked about how important language is to the identity of an Indigenous person. Although most of the Indigenous languages spoken in what is currently Canada are quite endangered, it will be possible to preserve some of them. Teaching the languages to young people is a vital part of the preservation effort, and having useful, accurate teaching materials is important for effective teaching. People with training in Linguistics can make valuable contributions to supporting communities in documenting languages and creating teaching materials.
1. What does it mean to say that Linguistics is a science? The field uses empirical observations to develop theories of language behaviour.
2. Each of the following sentences represents something someone might say about language. Which of them illustrates a descriptive view of language? The use of quotative like in sentences such as, “She was like, I can’t believe you did that!” began to enter Canadian English with the generation of speakers born in 1971.
3. Which of the following kinds of data would a linguist be likely to observe? Whether Korean includes tones that change the meaning of words.
1. Newspaper headlines occasionally have unexpectedly funny interpretations. One example is: Two cars were reported stolen by the police yesterday. Which part of your mental grammar leads to the possibility that the police could have done the stealing or the reporting in this headline? Syntax, Semantics.
2. Newfoundland English has some characteristic differences to standard Canadian English. The following sentences are grammatical in Newfoundland English: I eats toast for breakfast every day. You knows the answer to that question. What part of the mental grammar of Newfoundland English is different to Canadian English in these examples? Morphology.
3. When speakers of Hawaiian pronounce the English phrase, “Merry Christmas”, it sounds like: mele kalikimaka. What part of the mental grammar of Hawaiian is responsible for how the English phrase gets pronounced? Phonology.
1. What does it mean to say that mental grammar is generative? The principles of mental grammar allow us to form completely novel sentences, and to understand them when we hear them.
2. The systematic principles of English phonology generate some word forms but not others. Which of the following words could be a possible word in English? Klaff.
3. The systematic principles of English syntax generate some sentences but not others. Which of the following sentences is not possible in English? Herself have wrote these excellent book.
1. It’s important to study Latin because Latin is more logical than other languages. False.
2. Spending too much time texting will ruin your ability to write proper English. False.
3. The dictionary gives the only correct meaning and pronunciation for words. False.
1. What is the voicing of the last sound in the word ‘soup’? Voiceless.
2. What is the voicing of the last sound in the word ‘life’? Voiceless.
3. What is the voicing of the last sound in the word ‘seem’? Voiced.
1. What is the place of articulation of the FIRST sound in the word ‘minor’? Bilabial.
2. What is the place of articulation of the FINAL sound in the word ‘wit’? Alveolar.
3. What is the place of articulation of the FIRST sound in the word ‘photography’? Labiodental.
1. The vowel sounds in the words neat and spread are both spelled “ea”. Do the vowels in the two words sound the same as each other or different? Different.
2. Are the final sounds in the words face and mess the same as each other or different? Same.
3. Are the first sounds in the two words gym and gum the same as each other or different? Different.
1. What kind of sound is the first sound in the word early? Vowel.
2. What kind of sound is the first sound in the word junior? Voiced consonant.
3. What kind of sound is the first sound in the word winter? Glide.
1. What is the articulatory description for the consonant sound represented by the IPA symbol [p]? Voiceless bilabial stop.
2. What is the correct articulatory description for the consonant sound represented by the IPA symbol [ð]? Voiced dental fricative.
3. What is the correct articulatory description for the consonant sound represented by the IPA symbol [ʃ]? Voiceless post-alveolar fricative.
1. What is the articulatory description for the vowel [i]? High front unrounded tense vowel.
2. What is the articulatory description for the vowel [ɛ]? Mid front unrounded lax vowel.
3. What is the articulatory description for the vowel [ɑ]? Low back unrounded tense vowel.
1. What is the diphthong sound in the word in the word proud? [aʊ].
2. What is the diphthong sound in the word in the word rain? [eɪ].
3. What is the diphthong sound in the word in the word sigh? [aɪ].
1. The video indicated that the word funnel can be transcribed to indicate that the second syllable consists of a syllabic [l̩]. The word elbow is also spelled with the letters ‘el’. Say the two words to yourself several times. Which is the correct transcription for elbow? [ɛlboʊ].
2. The words human and manager both contain a syllable that is spelled with the letters ‘man’. In which word does that syllable contain a syllabic [n̩]? Human.
3. In the word umbrella, is the [m] syllabic? No.
1. The following city names all contain the letter ‘t’ within the word. In which of them is the letter ‘t’ pronounced as [tʰ]? Victoria.
2. The following words all contain the segment /k/. In which of them is it pronounced as the allophone [kʰ]? Accomplish.
3. The following words all contain the segment /p/. In which of them is it pronounced as the allophone [pʰ]? Appearance.
1. What articulatory process is at work when the word bank is pronounced as [bæŋk]? Assimilation (Anticipatory / Regressive).
2. What articulatory process is at work when a child pronounces the word yellow as [lɛloʊ]? Assimilation (Anticipatory / Regressive).
3. What articulatory process is at work when the word cream is pronounced as [kɹ̥ijm]? Assimilation (Perseveratory / Progressive).
1. What articulatory process is at work when the word idea is pronounced as [ajdijɚ]? Epenthesis.
2. What articulatory process is at work when the word gorilla is pronounced as [ɡɹɪlʌ]? Deletion.
3. What articulatory process is at work when the word you is pronounced as [jə]? Reduction.
1. Young children’s voices are usually recognizably different from adult’s voices. Which factor is likeliest to be different between children’s speech and adults’ speech? Pitch.
2. In English, yes-no questions often conclude with rising pitch, whereas wh-questions often have a falling pitch on the final words. Is this pitch difference a difference in tone or in intonation? Intonation.
3. English uses pitch as one factor in syllable stress. There are many English pairs of words like record (noun) and record (verb), which are spelled the same but differ in their stress patterns. Which of the following is true for this pair of words? The first syllable has a higher pitch than the second in the noun record.
1. Are the phonetically different segments [m] and [n] phonemically contrastive in English? Yes.
2. Are the phonetically different segments [p] and [pʰ] phonemically contrastive in English? No.
3. Do the words sight and site form a minimal pair in English? No.
1. Remember that in English, voiceless stops are aspirated at the beginning of a word and the beginning of a stressed syllable, but never in the middle of a word nor at the end of a word. Which term best describes this pattern? Complementary distribution.
2. The symbol [l̴] represents a velarized [l]. Looking at the following set of transcribed English words, what can you conclude about [l] and [l̴] in English? [l] and [l̴] are in complementary distribution in English.
leaf [lif] fall [fɑl̴]
luck [lʌk] spill [spɪl̴]
lemon [lɛmən] wolf [wʊl̴f]
3. Remembering that the alveolar flap [ɾ] appears in a predictable environment in English (see Section 3.9), which statement is true for English? The segments [t] and [ɾ] are allophones of the same phoneme in English.
1. These two segments — [w] [o] — have many features in common. Which feature distinguishes them? [syllabic].
2. These two segments — [p] [f] — have many features in common. Which feature distinguishes them? [continuant].
3. These two segments — [p] [b] — have many features in common. Which feature distinguishes them? [voice].
1. In the following set of segments, which segment must be excluded to make the remaining segments constitute a natural class? [æ].
2. In the following set of segments, which segment must be excluded to make the remaining segments constitute a natural class? [f].
3. This set of segments constitutes a natural class: [i ɛ æ]. Which segment could you add to the set while still preserving the natural class? [ɪ].
1. Which phonological rule accurately represents the process, “vowels become nasalized before a nasal consonant”?
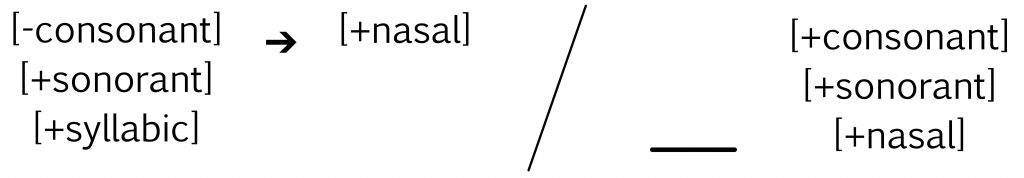
2. Which sentence accurately describes the process depicted in this phonological rule? Voiceless fricatives become voiced between voiced sonorants
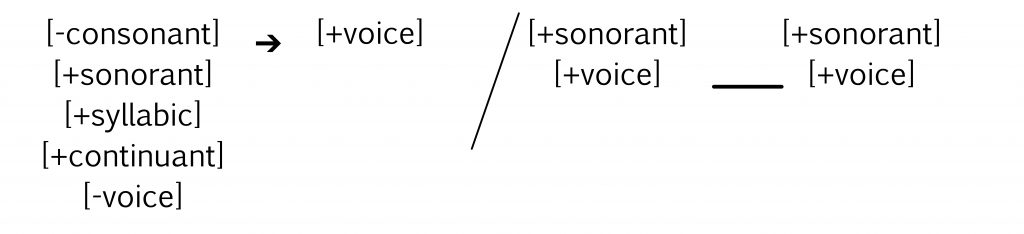
3. Which sentence accurately describes the process depicted in this phonological rule? The segment [ə] is epenthesized following a strident consonant.
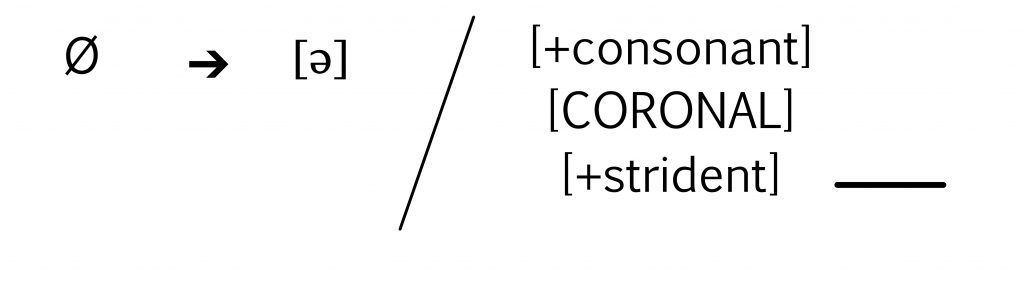
1. The phonology of Thai contains a three-way contrast between voiced /b/, voiceless /p/, and aspirated /pʰ/. How likely is it that a six-month-old baby growing up in an English-speaking household would be able to hear the difference between Thai [p] and [pʰ]? Very likely.
2. Arabic phonology includes a contrast between uvular and pharyngeal fricatives. How likely is it that a two-year-old growing up in an English-speaking household would be able to hear the difference between these two places of articulation? Very unlikely.
3. In the various dialects of Chinese, there is no phonemic contrast between tense and lax vowels. How likely is it that a four-month-old baby growing up in a Mandarin Chinese-speaking household would be able to hear the contrast between English [e] and [ɛ]? Very likely.
1. In Canadian French, the front tense vowels [y] and [i] become the lax vowels [ʏ] and [ɪ] in certain environments. Is it likely to be easy or difficult for a native speaker of Canadian French to learn the English contrast between /i/ and /ɪ/ (as in sleep and slip)? Difficult.
2. Arabic includes a contrast between a voiceless velar fricative [x] and a voiced velar fricative [ɣ]. Is this contrast likely to be easy or difficult for native speakers of English to learn? Easy.
3. In Cree, voiceless stops become voiced between vowels. Given that Cree has both voiced and voiceless stops in its phonetic inventory, is it likely to be easy or difficult for a native speaker of Cree to learn the phonemic contrast between /b/ and /p/ in English? Difficult.
1. What type of grammatical information does the inflectional affix in the word speeches communicate? Number.
2. What type of grammatical information does the inflectional affix in the word climbed communicate? Tense.
3. What type of grammatical information does the inflectional difference between he and him indicate? Case.
1. Which of the following best describes the derivation of the word assignment? Verb + -ment ➔ Noun.
2. Which of the following best describes the derivation of the word skillful? Noun + -ful ➔ Adjective.
3. Which of the following best describes the derivation of the word simplify? Adjective + -ify ➔ Verb.
1. In the sentence, “The room contained a bearskin rug,” what kind of compound is bearskin? Endocentric.
2. In the sentence, “Randy worked as a cowhand on the ranch,” what kind of compound is cowhand? Exocentric.
3. In the sentence, “Hyunji manages a bookshop,”, what kind of compound is bookshop? Endocentric.
1. Comparing the following sets of words, which would you predict would lead to greater blood flow in more areas of the brain? Humming, singing, whistling.
2. When shown a picture of a pair of tongs, a patient describes the picture, “You pick up things with it”. Which type of aphasia is this response more typical of? Anomic aphasia.
3. When describing an injury to his knees, a patient says, “no good uh ache and uh uh uh knees and ankles uh home doctor and legs”. Which type of aphasia is this response more typical of? Agrammatic aphasia.
In the following tree diagram:
1. What is the structural relationship between V loves and NP sushi? V and NP are sisters.
2. What is the structural relationship between NP Colin and V loves? NP and V are not related in any of these three ways.
3. Which node is the sister of NP Colin? T’
1. In this tree diagram, what position does the DP my coffee occupy? Complement.
2. In this tree diagram, what position does the D my occupy? Head.
3. In this tree diagram, what position does the NP Hamilton occupy? Complement.
1. Which of the following is the correct representation for the sentence Sara bought a car?
2. Which of the following is the correct representation for the sentence Sang-Ho won a medal?
3. Which of the following is the correct representation for the sentence Prabhjot should read this article?
1. What is the subcategory of the underlined verb in this sentence? The soccer players kicked the ball. Transitive.
2. What is the subcategory of the underlined verb in this sentence? Many birds fly over Ontario each fall. Intransitive.
3. What is the subcategory of the underlined verb in this sentence? This game teaches children the alphabet. Ditransitive.
1. Is the underlined phrase an adjunct or a complement? Sam ran the Around-the-Bay race. Complement.
2. Is the underlined phrase an adjunct or a complement? Sam ran this morning. Adjunct.
3. Is the underlined phrase an adjunct or a complement? The baby slept through the night. Adjunct.
1. Which tree diagram correctly represents the question, “Could you hand me those scissors?”
2. Which tree diagram correctly represents the question, “Does Suresh like Ethiopian food?”
3. Which tree diagram correctly represents the question, “Will the Habs win the Stanley Cup?”
1. Which tree diagram correctly represents the Deep Structure for the question, “Who did Brenda see at the gym?”
2.Which tree diagram correctly represents the Surface Structure for the question, “Where did you get that hat?”
3. Which tree diagram correctly represents the Surface Structure for the question, “Why should I trust you?”
1. Which of the following illustrates the position of the trace in the wh-question What did Christina order at Chipotle? What did Christina order what at Chipotle.
2. Which of the following ungrammatical sentences gives evidence that unpronounced traces exist in our mental representations of sentences? *What did you eat sandwiches for lunch?
3. Predict which sentence would lead to more eye movements to a picture of a rabbit after the verb chase. What did the fox chase ^ into the hedge?
1. What label best describes the thematic role of the underlined NP? The guard chased the intruder. Agent.
2. What label best describes the thematic role of the underlined NP? The wind slammed the door shut. Cause.
3. What label best describes the thematic role of the underlined NP? The guard followed the intruder. Theme.
1. Is the following sentence in the active or passive voice? The patient was diagnosed with alopecia. Passive.
2. Is the following sentence in the active or passive voice? Eileen was convinced that her appointment had been cancelled. Passive.
3. Is the following sentence in the active or passive voice? The children had been invited to a tea party. Passive.
1. What kind of ERP is likely to be observed in response to this sentence? The children’s feet have grown so I bought them some new spoons. N400.
2. What kind of ERP is likely to be observed in response to this sentence? Elias told the coach that he wanted to learn to swam. P600.
3. What kind of ERP is likely to be observed in response to this sentence? Before the dinner party, Isla spent a long time in the cooked. P600.
1. French uses morphology indicate whether nouns, adjectives and determiners are masculine or feminine. If an L1 speaker of English is learning French, what kind of transfer are they likely to experience in learning this property of French grammar? Negative transfer.
2. Russian does not have definite or indefinite determiners like English a and the. If an L1 speaker of Russian is learning English, what kind of transfer are they likely to experience in learning this property of English grammar? Negative transfer.
3. Russian groups nouns by their grammatical gender, either masculine, feminine or neuter. Look again at the facts about French presented in Question 1. If an L1 speaker of Russian is learning French, what kind of transfer are they likely to experience in learning this property of French grammar? Positive transfer.
1. Sidney Crosby, Wayne Gretzy, and Maurice Richard, and ______________ of hockey player. Extensions.
2. Has pages, binding, and contains writing are all __________________ of book. Intensions.
3. Head of state, lives in the White House, and American are all ______________ of President of the United States. Intensions.
1. For most speakers of Canadian English in the category animals, giraffe is probably: Less typical than dog.
2. For most speakers of Canadian English, in the category pets, tarantula is probably: Peripheral.
3. Choose the set of features that best defines chair. [+furniture, +legs, +back, +seat, -blankets].
1. Which of the following words would we expect to prime a target word carrot? Broccoli.
2. Which of the following words would we expect to prime a target word happy? Sad.
3. Which of the following words would we expect to prime a target word week? Month.
Balota, D. A., & Chumbley, J. I. (1984). Are lexical decisions a good measure of lexical access? The role of word frequency in the neglected decision stage. Journal of Experimental Psychology, Human Perception and Performance, 10(3), 340–57.
Bowden, H. W., Steinhauer, K., Sanz, C., & Ullman, M. T. (2013). Native-like brain processing of syntax can be attained by university foreign language learners. Neuropsychologia, 51(13), 2492–2511.
Dickey, M. W., Choy, J. J., & Thompson, C. K. (2007). Real-time comprehension of wh- movement in aphasia: evidence from eyetracking while listening. Brain and Language, 100(1), 1–22.
Gasser, M. (2012). How language works: The cognitive science of linguistics. Retrieved from http://www.oercommons.org/courses/how-language-works-the-cognitive-science-of-linguistics/view.
Graham, G. (1938). Swiss Sonata. New York: Charles Scribner’s Sons. Retrieved from http://gutenberg.ca/ebooks/grahamg-swisssonata/grahamg-swisssonata-00-h.html
Hahne, A. (2001). What’s different in second-language processing? Evidence from event-related brain potentials. Journal of Psycholinguistic Research, 30(3), 251–266.
Hahne, A., & Friederici, A. D. (2002). Differential task effects on semantic and syntactic processes as revealed by ERPs. Cognitive Brain Research, 13(3), 339–356.
Kutas, M., & Hillyard, S. A. (1980). Reading senseless sentences: Brain potentials reflect semantic incongruity. Science, 207(4427), 203–205.
Liberman, M. (2016). Linguistics 001: Introduction to Linguistics. Retrieved from http://www.ling.upenn.edu/courses/ling001/.
Meyer, D. E., & Schvaneveldt, R. W. (1971). Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. Journal of Experimental Psychology, 90(2), 227–234.
Pirurvik Centre. (2018). Inuktitut Tusaalanga. Retrieved from http://www.tusaalanga.ca.
Ratt, Solomon. (2016). Mâci-nêhiyawêwin: Beginning Cree. Regina: University of Regina Press.
Rosch, E. H. (1973). Natural categories. Cognitive Psychology, 4(3), 328–350.
Shawanda, G. (2001). Anishnaabemowin: Miinwa anishnaabe zheyaawin — Our language, our culture. Hamilton Regional Indian Center.
Statistics Canada. (2017). Aboriginal identity population who can speak an Aboriginal language, by language family, main languages within these families, and main provincial and territorial concentrations, Canada, 2016. (table). “The Aboriginal languages of First Nations people, Métis and Inuit.” “Census in Brief.” “Analytical Products, 2016 Census.” Retrieved from http://www12.statcan.gc.ca/census-recensement/2016/as-sa/98-200-x/2016022/98-200-x2016022-eng.cfm
Turcotte, K. (2014, January 24). Australian vs. Canadian accents [Video file]. Retrieved from https://www.youtube.com/watch?v=DWbYEJC4j4U&feature=youtu.be
Tyler, L. K., Bright, P., Fletcher, P., & Stamatakis, E. A. (2004). Neural processing of nouns and verbs: The role of inflectional morphology. Neuropsychologia, 42(4), 512-523.
Voss, J. C., (1930).The Venturesome Voyages of Captain Voss. London: Martin Hopkinson. Retrieved from http://gutenberg.ca/ebooks/voss-venturesomevoyages/voss-venturesomevoyages-00-h-dir/voss-venturesomevoyages-00-h.html.
White, E. J., Genesee, F., & Steinhauer, K. (2012). Brain responses before and after intensive second language learning: Proficiency based changes and first language background effects in adult learners. PLoS ONE, 7(12).
Zingeser, L. B., & Berndt, R. S. (1990). Retrieval of nouns and verbs in agrammatism and anomia. Brain and Language, 39(1), 14–32.
1. What does it mean to say that Linguistics is a science? The field uses empirical observations to develop theories of language behaviour.
2. Each of the following sentences represents something someone might say about language. Which of them illustrates a descriptive view of language? The use of quotative like in sentences such as, “She was like, I can’t believe you did that!” began to enter Canadian English with the generation of speakers born in 1971.
3. Which of the following kinds of data would a linguist be likely to observe? Whether Korean includes tones that change the meaning of words.
1. Newspaper headlines occasionally have unexpectedly funny interpretations. One example is: Two cars were reported stolen by the police yesterday. Which part of your mental grammar leads to the possibility that the police could have done the stealing or the reporting in this headline? Syntax, Semantics.
2. Newfoundland English has some characteristic differences to standard Canadian English. The following sentences are grammatical in Newfoundland English: I eats toast for breakfast every day. You knows the answer to that question. What part of the mental grammar of Newfoundland English is different to Canadian English in these examples? Morphology.
3. When speakers of Hawaiian pronounce the English phrase, “Merry Christmas”, it sounds like: mele kalikimaka. What part of the mental grammar of Hawaiian is responsible for how the English phrase gets pronounced? Phonology.
1. What does it mean to say that mental grammar is generative? The principles of mental grammar allow us to form completely novel sentences, and to understand them when we hear them.
2. The systematic principles of English phonology generate some word forms but not others. Which of the following words could be a possible word in English? Klaff.
3. The systematic principles of English syntax generate some sentences but not others. Which of the following sentences is not possible in English? Herself have wrote these excellent book.
1. It’s important to study Latin because Latin is more logical than other languages. False.
2. Spending too much time texting will ruin your ability to write proper English. False.
3. The dictionary gives the only correct meaning and pronunciation for words. False.
1. What is the voicing of the last sound in the word ‘soup’? Voiceless.
2. What is the voicing of the last sound in the word ‘life’? Voiceless.
3. What is the voicing of the last sound in the word ‘seem’? Voiced.
1. What is the place of articulation of the FIRST sound in the word ‘minor’? Bilabial.
2. What is the place of articulation of the FINAL sound in the word ‘wit’? Alveolar.
3. What is the place of articulation of the FIRST sound in the word ‘photography’? Labiodental.
1. The vowel sounds in the words neat and spread are both spelled “ea”. Do the vowels in the two words sound the same as each other or different? Different.
2. Are the final sounds in the words face and mess the same as each other or different? Same.
3. Are the first sounds in the two words gym and gum the same as each other or different? Different.
1. What kind of sound is the first sound in the word early? Vowel.
2. What kind of sound is the first sound in the word junior? Voiced consonant.
3. What kind of sound is the first sound in the word winter? Glide.
1. What is the articulatory description for the consonant sound represented by the IPA symbol [p]? Voiceless bilabial stop.
2. What is the correct articulatory description for the consonant sound represented by the IPA symbol [ð]? Voiced dental fricative.
3. What is the correct articulatory description for the consonant sound represented by the IPA symbol [ʃ]? Voiceless post-alveolar fricative.
1. What is the articulatory description for the vowel [i]? High front unrounded tense vowel.
2. What is the articulatory description for the vowel [ɛ]? Mid front unrounded lax vowel.
3. What is the articulatory description for the vowel [ɑ]? Low back unrounded tense vowel.
1. What is the diphthong sound in the word in the word proud? [aʊ].
2. What is the diphthong sound in the word in the word rain? [eɪ].
3. What is the diphthong sound in the word in the word sigh? [aɪ].
1. The video indicated that the word funnel can be transcribed to indicate that the second syllable consists of a syllabic [l̩]. The word elbow is also spelled with the letters ‘el’. Say the two words to yourself several times. Which is the correct transcription for elbow? [ɛlboʊ].
2. The words human and manager both contain a syllable that is spelled with the letters ‘man’. In which word does that syllable contain a syllabic [n̩]? Human.
3. In the word umbrella, is the [m] syllabic? No.
1. The following city names all contain the letter ‘t’ within the word. In which of them is the letter ‘t’ pronounced as [tʰ]? Victoria.
2. The following words all contain the segment /k/. In which of them is it pronounced as the allophone [kʰ]? Accomplish.
3. The following words all contain the segment /p/. In which of them is it pronounced as the allophone [pʰ]? Appearance.
1. What articulatory process is at work when the word bank is pronounced as [bæŋk]? Assimilation (Anticipatory / Regressive).
2. What articulatory process is at work when a child pronounces the word yellow as [lɛloʊ]? Assimilation (Anticipatory / Regressive).
3. What articulatory process is at work when the word cream is pronounced as [kɹ̥ijm]? Assimilation (Perseveratory / Progressive).
1. What articulatory process is at work when the word idea is pronounced as [ajdijɚ]? Epenthesis.
2. What articulatory process is at work when the word gorilla is pronounced as [ɡɹɪlʌ]? Deletion.
3. What articulatory process is at work when the word you is pronounced as [jə]? Reduction.
1. Young children’s voices are usually recognizably different from adult’s voices. Which factor is likeliest to be different between children’s speech and adults’ speech? Pitch.
2. In English, yes-no questions often conclude with rising pitch, whereas wh-questions often have a falling pitch on the final words. Is this pitch difference a difference in tone or in intonation? Intonation.
3. English uses pitch as one factor in syllable stress. There are many English pairs of words like record (noun) and record (verb), which are spelled the same but differ in their stress patterns. Which of the following is true for this pair of words? The first syllable has a higher pitch than the second in the noun record.
1. Are the phonetically different segments [m] and [n] phonemically contrastive in English? Yes.
2. Are the phonetically different segments [p] and [pʰ] phonemically contrastive in English? No.
3. Do the words sight and site form a minimal pair in English? No.
1. Remember that in English, voiceless stops are aspirated at the beginning of a word and the beginning of a stressed syllable, but never in the middle of a word nor at the end of a word. Which term best describes this pattern? Complementary distribution.
2. The symbol [l̴] represents a velarized [l]. Looking at the following set of transcribed English words, what can you conclude about [l] and [l̴] in English? [l] and [l̴] are in complementary distribution in English.
leaf [lif] fall [fɑl̴]
luck [lʌk] spill [spɪl̴]
lemon [lɛmən] wolf [wʊl̴f]
3. Remembering that the alveolar flap [ɾ] appears in a predictable environment in English (see Section 3.9), which statement is true for English? The segments [t] and [ɾ] are allophones of the same phoneme in English.
1. These two segments — [w] [o] — have many features in common. Which feature distinguishes them? [syllabic].
2. These two segments — [p] [f] — have many features in common. Which feature distinguishes them? [continuant].
3. These two segments — [p] [b] — have many features in common. Which feature distinguishes them? [voice].
1. In the following set of segments, which segment must be excluded to make the remaining segments constitute a natural class? [æ].
2. In the following set of segments, which segment must be excluded to make the remaining segments constitute a natural class? [f].
3. This set of segments constitutes a natural class: [i ɛ æ]. Which segment could you add to the set while still preserving the natural class? [ɪ].
1. Which phonological rule accurately represents the process, “vowels become nasalized before a nasal consonant”?
2. Which sentence accurately describes the process depicted in this phonological rule? Voiceless fricatives become voiced between voiced sonorants
3. Which sentence accurately describes the process depicted in this phonological rule? The segment [ə] is epenthesized following a strident consonant.
1. The phonology of Thai contains a three-way contrast between voiced /b/, voiceless /p/, and aspirated /pʰ/. How likely is it that a six-month-old baby growing up in an English-speaking household would be able to hear the difference between Thai [p] and [pʰ]? Very likely.
2. Arabic phonology includes a contrast between uvular and pharyngeal fricatives. How likely is it that a two-year-old growing up in an English-speaking household would be able to hear the difference between these two places of articulation? Very unlikely.
3. In the various dialects of Chinese, there is no phonemic contrast between tense and lax vowels. How likely is it that a four-month-old baby growing up in a Mandarin Chinese-speaking household would be able to hear the contrast between English [e] and [ɛ]? Very likely.
1. In Canadian French, the front tense vowels [y] and [i] become the lax vowels [ʏ] and [ɪ] in certain environments. Is it likely to be easy or difficult for a native speaker of Canadian French to learn the English contrast between /i/ and /ɪ/ (as in sleep and slip)? Difficult.
2. Arabic includes a contrast between a voiceless velar fricative [x] and a voiced velar fricative [ɣ]. Is this contrast likely to be easy or difficult for native speakers of English to learn? Easy.
3. In Cree, voiceless stops become voiced between vowels. Given that Cree has both voiced and voiceless stops in its phonetic inventory, is it likely to be easy or difficult for a native speaker of Cree to learn the phonemic contrast between /b/ and /p/ in English? Difficult.
1. What type of grammatical information does the inflectional affix in the word speeches communicate? Number.
2. What type of grammatical information does the inflectional affix in the word climbed communicate? Tense.
3. What type of grammatical information does the inflectional difference between he and him indicate? Case.
1. Which of the following best describes the derivation of the word assignment? Verb + -ment ➔ Noun.
2. Which of the following best describes the derivation of the word skillful? Noun + -ful ➔ Adjective.
3. Which of the following best describes the derivation of the word simplify? Adjective + -ify ➔ Verb.
1. In the sentence, “The room contained a bearskin rug,” what kind of compound is bearskin? Endocentric.
2. In the sentence, “Randy worked as a cowhand on the ranch,” what kind of compound is cowhand? Exocentric.
3. In the sentence, “Hyunji manages a bookshop,”, what kind of compound is bookshop? Endocentric.
1. Comparing the following sets of words, which would you predict would lead to greater blood flow in more areas of the brain? Humming, singing, whistling.
2. When shown a picture of a pair of tongs, a patient describes the picture, “You pick up things with it”. Which type of aphasia is this response more typical of? Anomic aphasia.
3. When describing an injury to his knees, a patient says, “no good uh ache and uh uh uh knees and ankles uh home doctor and legs”. Which type of aphasia is this response more typical of? Agrammatic aphasia.
In the following tree diagram:
1. What is the structural relationship between V loves and NP sushi? V and NP are sisters.
2. What is the structural relationship between NP Colin and V loves? NP and V are not related in any of these three ways.
3. Which node is the sister of NP Colin? T’
1. In this tree diagram, what position does the DP my coffee occupy? Complement.
2. In this tree diagram, what position does the D my occupy? Head.
3. In this tree diagram, what position does the NP Hamilton occupy? Complement.
1. Which of the following is the correct representation for the sentence Sara bought a car?
2. Which of the following is the correct representation for the sentence Sang-Ho won a medal?
3. Which of the following is the correct representation for the sentence Prabhjot should read this article?
1. What is the subcategory of the underlined verb in this sentence? The soccer players kicked the ball. Transitive.
2. What is the subcategory of the underlined verb in this sentence? Many birds fly over Ontario each fall. Intransitive.
3. What is the subcategory of the underlined verb in this sentence? This game teaches children the alphabet. Ditransitive.
1. Is the underlined phrase an adjunct or a complement? Sam ran the Around-the-Bay race. Complement.
2. Is the underlined phrase an adjunct or a complement? Sam ran this morning. Adjunct.
3. Is the underlined phrase an adjunct or a complement? The baby slept through the night. Adjunct.
1. Which tree diagram correctly represents the question, “Could you hand me those scissors?”
2. Which tree diagram correctly represents the question, “Does Suresh like Ethiopian food?”
3. Which tree diagram correctly represents the question, “Will the Habs win the Stanley Cup?”
1. Which tree diagram correctly represents the Deep Structure for the question, “Who did Brenda see at the gym?”
2.Which tree diagram correctly represents the Surface Structure for the question, “Where did you get that hat?”
3. Which tree diagram correctly represents the Surface Structure for the question, “Why should I trust you?”
1. Which of the following illustrates the position of the trace in the wh-question What did Christina order at Chipotle? What did Christina order what at Chipotle.
2. Which of the following ungrammatical sentences gives evidence that unpronounced traces exist in our mental representations of sentences? *What did you eat sandwiches for lunch?
3. Predict which sentence would lead to more eye movements to a picture of a rabbit after the verb chase. What did the fox chase ^ into the hedge?
1. What label best describes the thematic role of the underlined NP? The guard chased the intruder. Agent.
2. What label best describes the thematic role of the underlined NP? The wind slammed the door shut. Cause.
3. What label best describes the thematic role of the underlined NP? The guard followed the intruder. Theme.
1. Is the following sentence in the active or passive voice? The patient was diagnosed with alopecia. Passive.
2. Is the following sentence in the active or passive voice? Eileen was convinced that her appointment had been cancelled. Passive.
3. Is the following sentence in the active or passive voice? The children had been invited to a tea party. Passive.
1. What kind of ERP is likely to be observed in response to this sentence? The children’s feet have grown so I bought them some new spoons. N400.
2. What kind of ERP is likely to be observed in response to this sentence? Elias told the coach that he wanted to learn to swam. P600.
3. What kind of ERP is likely to be observed in response to this sentence? Before the dinner party, Isla spent a long time in the cooked. P600.
1. French uses morphology indicate whether nouns, adjectives and determiners are masculine or feminine. If an L1 speaker of English is learning French, what kind of transfer are they likely to experience in learning this property of French grammar? Negative transfer.
2. Russian does not have definite or indefinite determiners like English a and the. If an L1 speaker of Russian is learning English, what kind of transfer are they likely to experience in learning this property of English grammar? Negative transfer.
3. Russian groups nouns by their grammatical gender, either masculine, feminine or neuter. Look again at the facts about French presented in Question 1. If an L1 speaker of Russian is learning French, what kind of transfer are they likely to experience in learning this property of French grammar? Positive transfer.
1. Sidney Crosby, Wayne Gretzy, and Maurice Richard, and ______________ of hockey player. Extensions.
2. Has pages, binding, and contains writing are all __________________ of book. Intensions.
3. Head of state, lives in the White House, and American are all ______________ of President of the United States. Intensions.
1. For most speakers of Canadian English in the category animals, giraffe is probably: Less typical than dog.
2. For most speakers of Canadian English, in the category pets, tarantula is probably: Peripheral.
3. Choose the set of features that best defines chair. [+furniture, +legs, +back, +seat, -blankets].
1. Which of the following words would we expect to prime a target word carrot? Broccoli.
2. Which of the following words would we expect to prime a target word happy? Sad.
3. Which of the following words would we expect to prime a target word week? Month.