Bierwisch, M. (1970) Semantics. In J. Lyons (Ed.), New horizons in linguistics (pp. 166-184). Harmondsworth: Pelican.
Boomer, D.S, & Laver, J.D.M. (1968). Slips of the tongue. British Journal of Disorders of Communication, 3, 2-12.
Cholin, J., Shiller, N. O., & Levelt, W. J. M. (2004). The preparation of syllables in speech production. Journal of Memory and Language, 50, 47–61.
Chomsky, N. & Halle, M. (1968). The sound pattern of English. New York: Harper & Row.
Clements, G. N. & Keyser, S. J. (1983) CV phonology (Linguistic Inquiries Monograph Series, No.9). Cambridge, MA: MIT Press.
Costa, A., & Sebastian-Gallés, N. (1998). Abstract phonological structure in language production: Evidence from Spanish. Journal of Experimental Psychology: Learning, Memory and Cognition, 24, 886-903.
Cutler, A. (1981). Making up materials is a confounded nuisance, or: Will we be able to run any psycholinguistic experiments at all in 1990? Cognition, 10, 65–70.
Dell, G. (1986). A spreading-activation theory of retrieval in speech production. Psychological Review, 93, 283-321.
Dell, G. S. & Reich, P. A. (1981). Stages in sentence production: An analysis of speech error data. Journal of Verbal Learning and Verbal Behavior, 20(6). 611-629. doi:10.1016/S0022-5371(81)90202-4.
Dell, G. S. (1984). The representation of serial order in speech: Evidence from the repeated phoneme effect in speech errors. Journal of Experimental Psychology: Learning, Memory and Cognition, 10, 222-233.
Den Ouden, D.B. (2002). Phonology in aphasia: syllables and segments in level-specific deficits. Unpublished doctoral dissertation. Groningen University.
Freud, S. (1975). The psychopathology of everyday life (Trans. A. Tyson). Harmondsworth, UK: Penguin. [Originally published 1901.]
Fromkin, V.A. (1971). The non-anomalous nature of anomalous utterances. Language, 47, 27-52.
Fromkin, V.A. (1973). Introduction. In V.A. Fromkin (Ed.), Speech errors in linguistic evidence (pp. 11-45). The Hague, The Neatherlands: Mouton.
García-Albea, J.E., del Viso, S., & Igoa, J.M. (1989). Movement errors and levels of processing in sentence production. Journal of Psycholinguistic Research, 18, 145-161.
Garrett, M.F. (1975). The analysis of sentence production. In G.H. Bower (Ed.), The psychology of language and motivation (Vol. 9, pp. 133-175). New York: Academy Press.
Garrett, M.F. (1980). Levels of processing in sentence production. In B. Butterworth (Ed.), Language production: Vol. 1. Speech and talk (pp. 177-210). New York: Academic Press.
Garrett, M.F. (1988). Processes in language production. In F. J. Newmeyer (Ed.), Linguistics: The Cambridge survey (pp. 6996). Cambridge, MA: Harvard University Press.
Garrett, M. F. (2001). The Psychology of Speech Errors. In N. J. Smelser & P. B. Baltes (Eds.), International encyclopedia of the social and behavioral sciences (pp. 14864-14870). New York: Elsevier.
Goldsmith, J. (1990). Autosegmental and metrical phonology. Cambridge, MA: Basil Blackwell.
Kempen, G., & Hoenkamp, E. (1987). An incremental procedural language for sentence formulation. Cognitive Science, 11, 201-258.
Kenny, C. (1994). Our legacy: Work and play. Keynote presentation. Proceedings of the Annual conference of the American Association for Music Therapy, “Connections: Integrating our Work and play.”
Levelt, W.J.M., Roelofs, A., & Meyer, A.S. (1999). A theory of lexical access in speech production. Behavioural and Brain Sciences, 22, 1-75.
Levelt, W.J.M. (1989). Speaking: From intention to articulation. Cambridge, MA: MIT Press.
Meringer, R., & Mayer, K. (1895). Versprechen und verlesen: Eine psychologisch-linguistische studie. Stuttgart: Gössen.
Meyer, A. S. (1990). The time course of phonological encoding in language production: The encoding of successive syllables of a word. Journal of Memory and Language, 29, 524-545.
Meyer, A. S. (1991). The time course of phonological encoding in language production: Phonological encoding inside a syllable. Journal of Memory and Language, 30, 69-69.
Meyer, A. S. (1992). Investigation of phonological encoding through speech error analyses: Achievements, limitations, and alternatives. Cognition, 42, 181-211.
Meyer, A.S. (2000). Form representations in word production. In L.R. Wheeldon (Ed.), Aspects of language production (pp. 49-70). East Sussex: Psychology Press.
Nooteboom, S. G. (1967). Some regularities in phonemic speech errors. IPO Annual Progress Report, 2, 65-70.
Nooteboom, S.G. (1969). The tongue slips into patterns. In A.G. Sciarone, A.J. van Essen, & A.A. Van Raad (Eds.) Nomen: Leyden studies in linguistics and phonetics (pp. 114-132). The Hague, The Neatherlands: Mouton.
Ramoo, D. & Olson, A. (accepted). Lexeme and speech syllables in English and Hindi: A case for syllable structure. In Lowe, J. & Ghanshyam, S. (Eds.) Trends in South Asian Linguistics, Berlin/New York: Mouton De Gruyter.
Roelofs, A. (1992). A spreading-activation theory of lemma retrieval in speaking. Cognition, 42, 107-142.
Roelofs, A. (1996). Computational models of lemma retrieval. In T. Dijkstra, & K. De Smedt (Eds.), Computational psycholinguistics: AI and connectionist models of human language processing (pp. 308-327). London: Taylor & Francis.
Roelofs, A. (1997a). Syllabification in speech production: Evaluation of WEAVER. Language and Cognitive Processes, 12, 657-693.
Roelofs, A. (1997b). The WEAVER model of word-form encoding in speech production. Cognition, 64, 249-284.
Roelofs, A. (1998). Rightward incrementality in encoding simple phrasal forms in speech production: Verb-particle combinations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 904-921.
Roelofs, A. (1999). Phonological segments and features as planning units in speech production. Language and Cognitive Processes, 14, 173-200.
Roelofs, A. (2000). WEAVER++ and other computational models of lemma retrieval and word-form encoding. In L.R. Wheeldon (Ed.), Aspects of language production (pp. 71-114). East Sussex: Psychology Press.
Romani, C., & Calabrese, A. (1996). On the representation of geminate consonants: Evidence from aphasia. Journal of Neurolinguistics, 9, 219–235.
Romani, C., Galluzzi, C., Bureca, I., & Olson, A. (2011). Effects of syllable structure in aphasic errors: Implications for a new model of speech production. Cognitive Psychology, 62. 151-192.
Selkirk, E. O. (1984). On the major class features and syllable theory. In M. Aronoff & R. Oehrle (Eds.) Language sound structure (pp. 107-136). Cambridge, Mass.: MIT Press.
Shattuck-Hufnagel, S. (1979). Speech errors as evidence for a serial ordering mechanism in sentence production. In W.E. Cooper & E.C.T. Walker (Eds.), Sentence processing (pp. 295-342). Hillsdale, N.J.: Lawrence Erlbaum.
Shattuck-Hufnagel, S. (1983). Sublexical units and suprasegmental structure in speech production planning. In P.F. MacNeilage (Ed.), The production of speech (pp. 109-136). New York: Springer
Shattuck-Hufnagel, S. (1987). The role of word onset conso-nants in speech production planning: New evidence fromspeech error patterns. In E. Keller & M. Gopnik (Eds.), Motor and sensory processing in language (pp. 17–51).Hillsdale, NJ: Erlbaum.
Shattuck-Hufnagel, S. (1992). The role of word structure insegmental serial ordering. Cognition, 42, 213–259.
Stemberger, J. P. (1983). Inflectional malapropisms: Form-based errors in English morphology. Linguistics, 21, 573–602.
Stemberger, J. P. (1984). Structural errors in normal and agrammatic speech. Cognitive Neuropsychology, 1, 281–313.
Stemberger, J. P. (1985). An interactive activation model of language production. In A. W. Ellis (Ed.). Progress in the psychology of language (Vol. 1). London: Erlbaum.
Stemberger, J. P. (1990). Word shape errors in language production. Cognition, 35, 123-157.
Wilshire, C. E. (2002). Where do aphasic phonological errors come from? Evidence from phoneme movement errors in picture naming. Aphasiology, 16, 169–197.

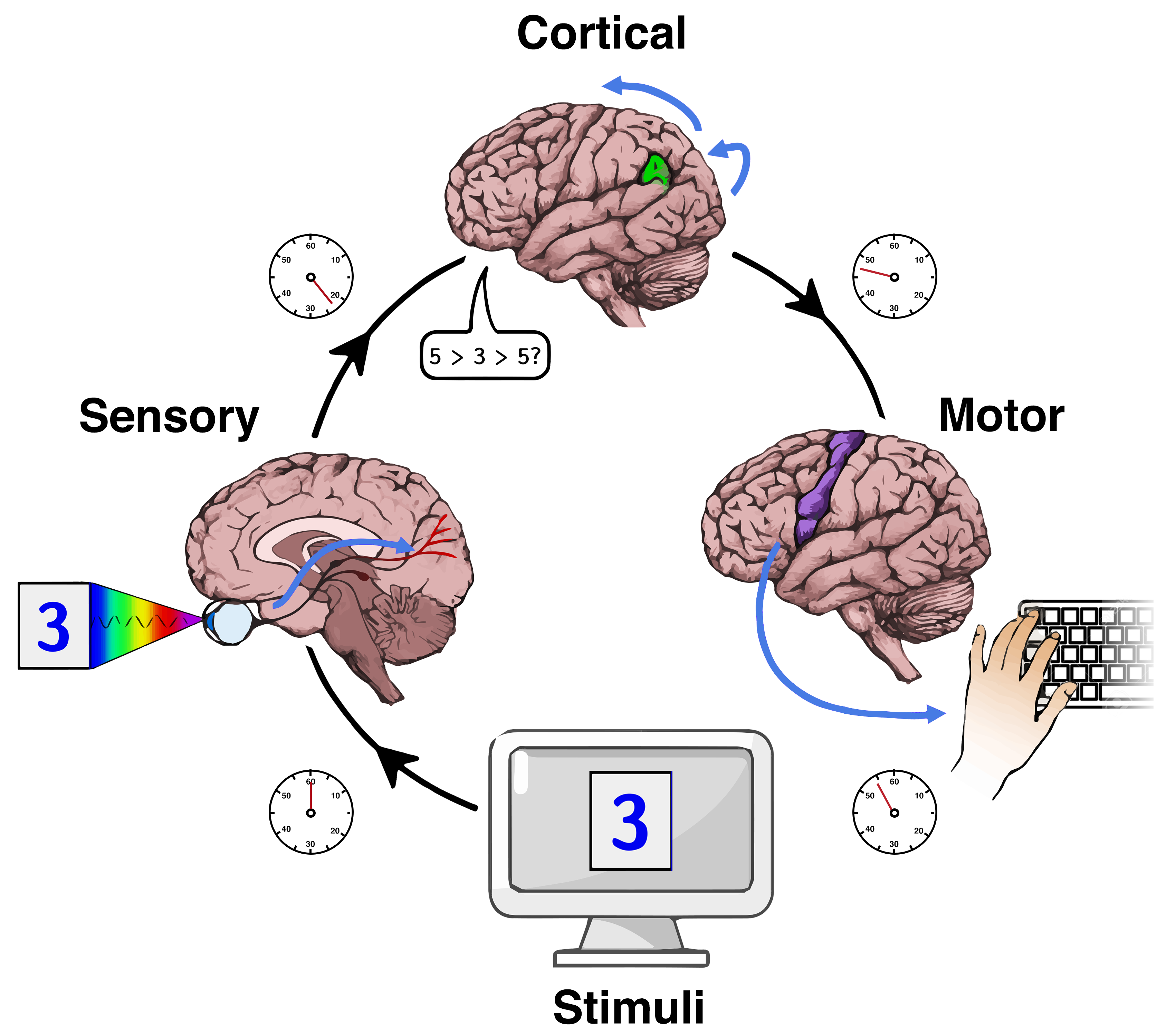
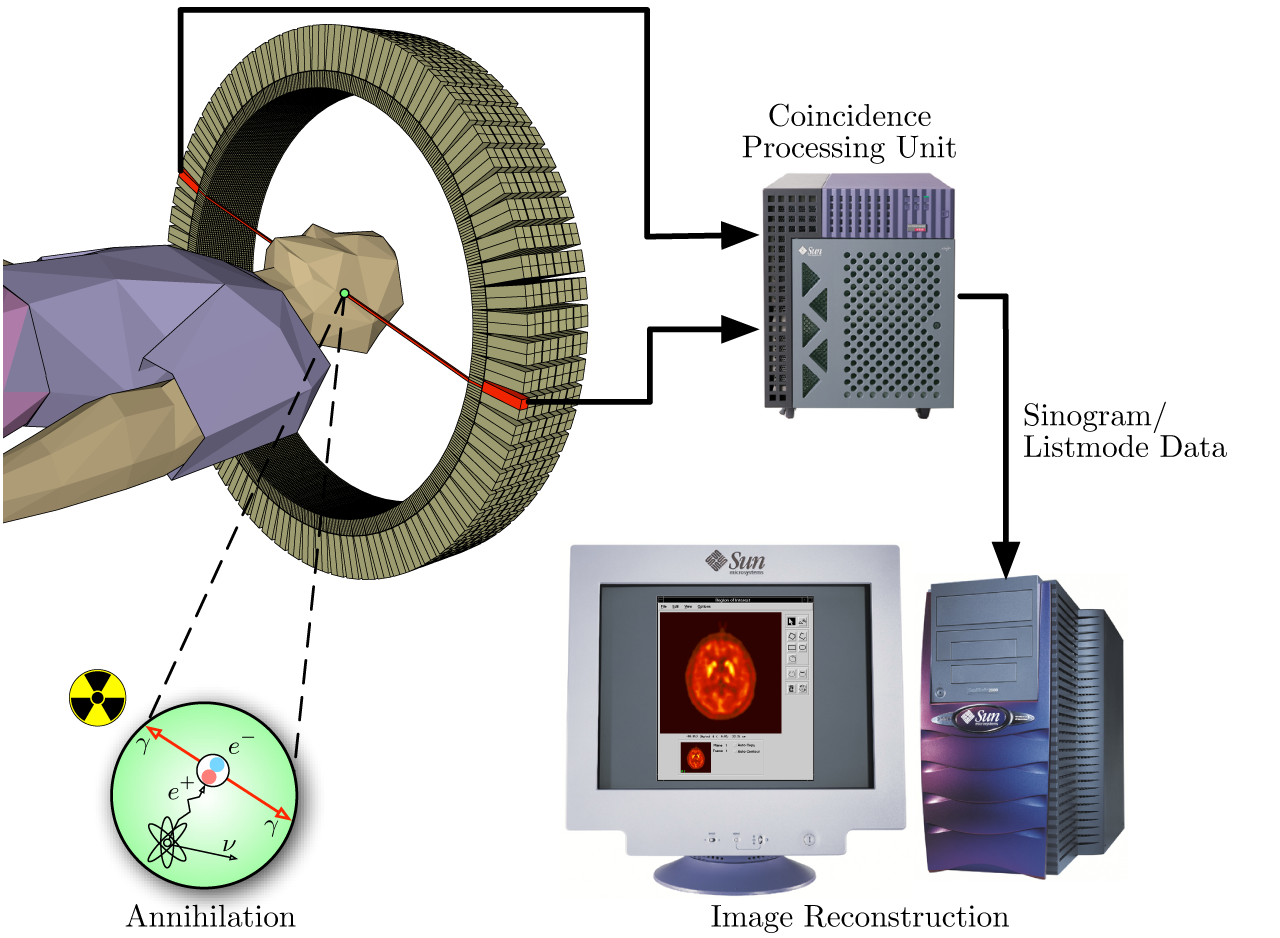
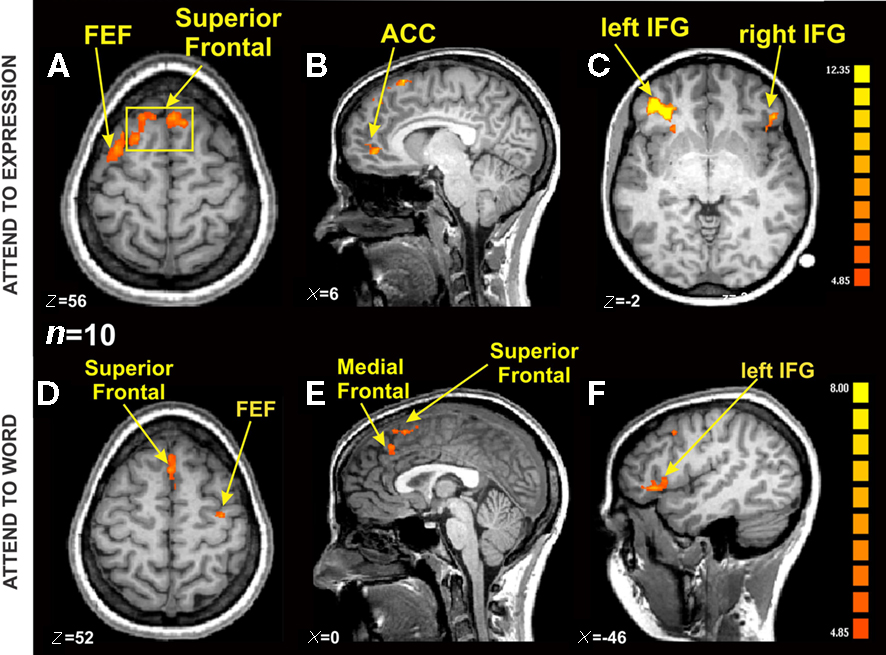
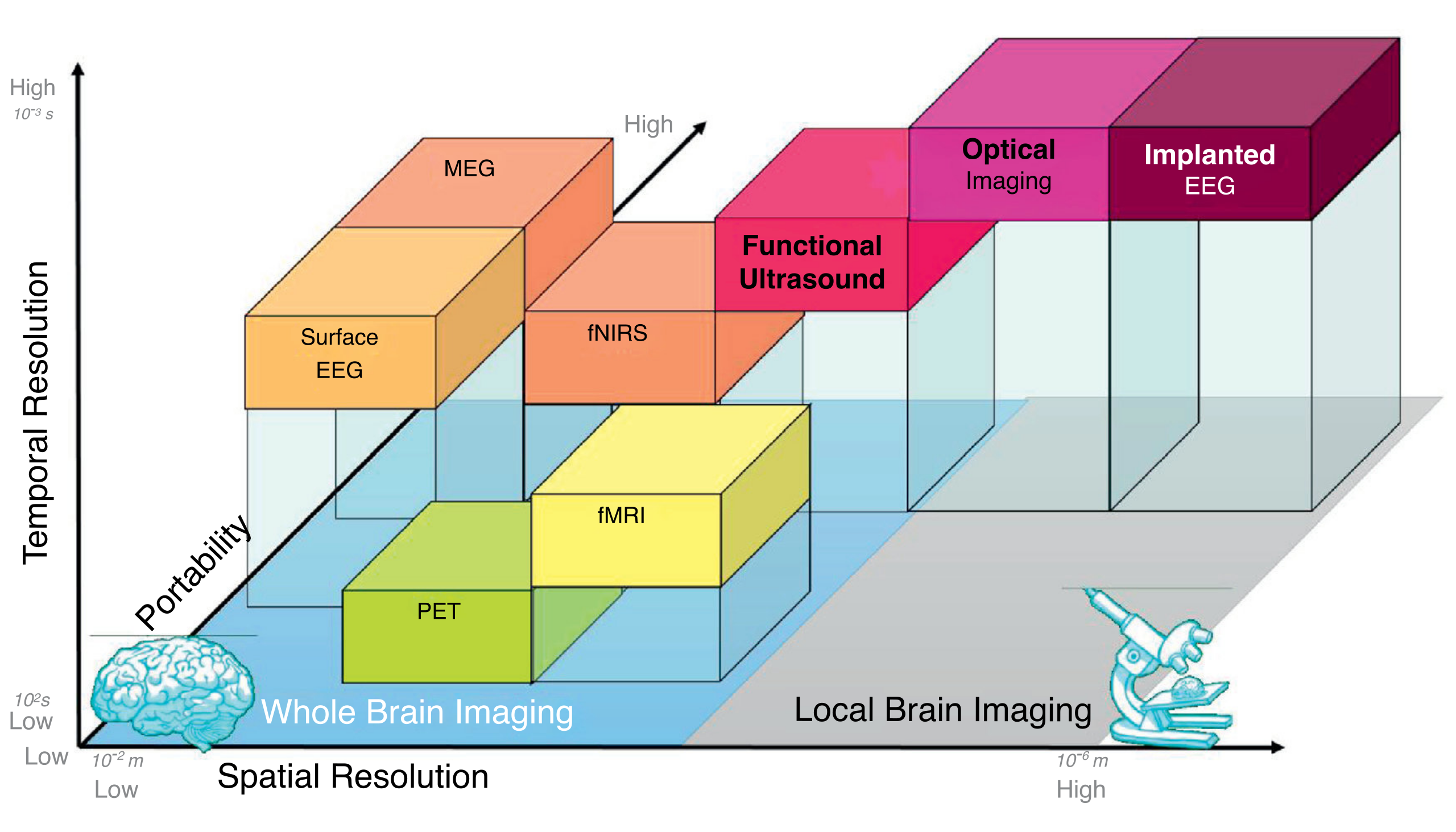

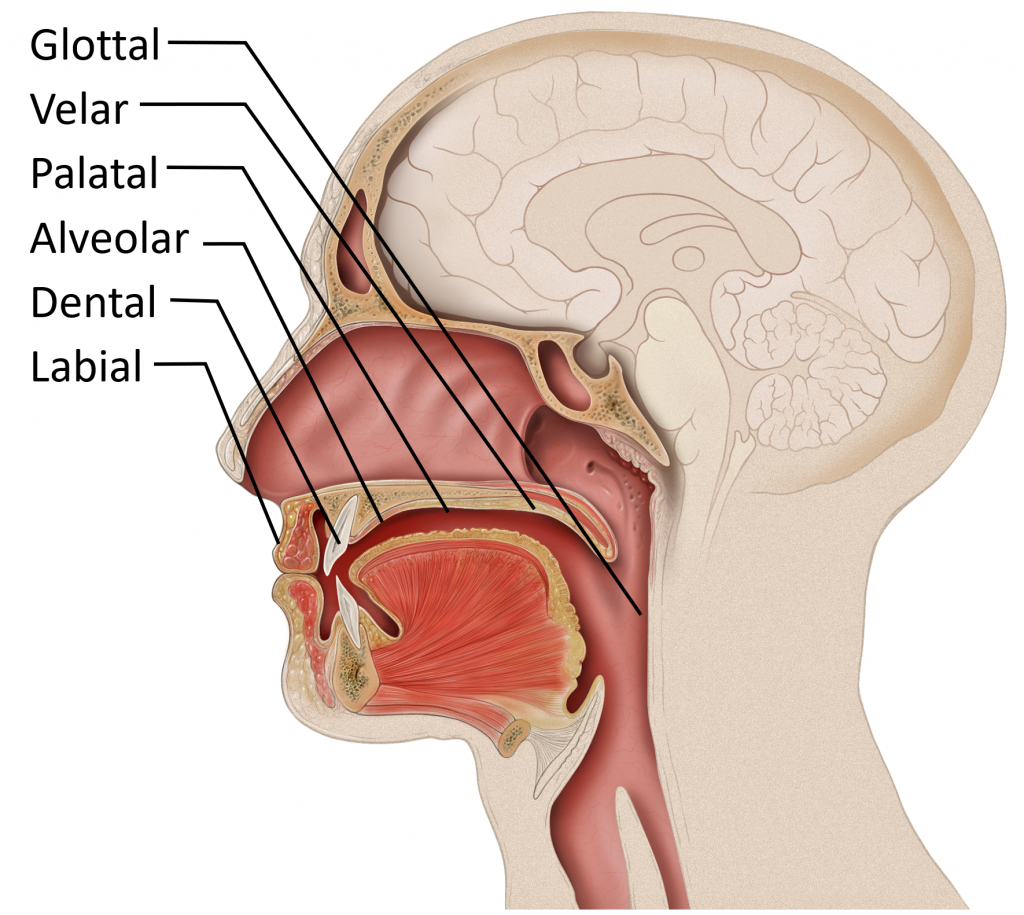

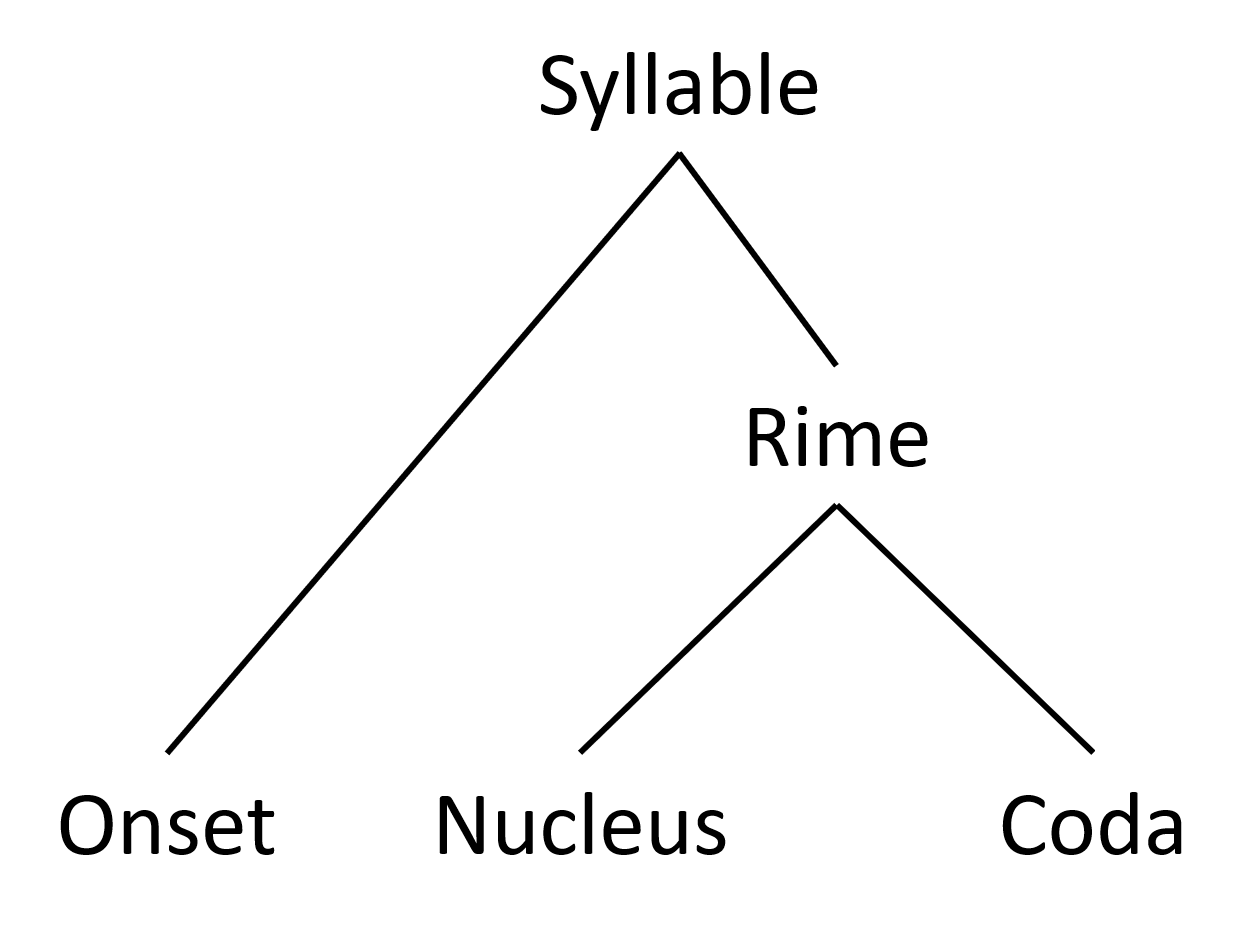


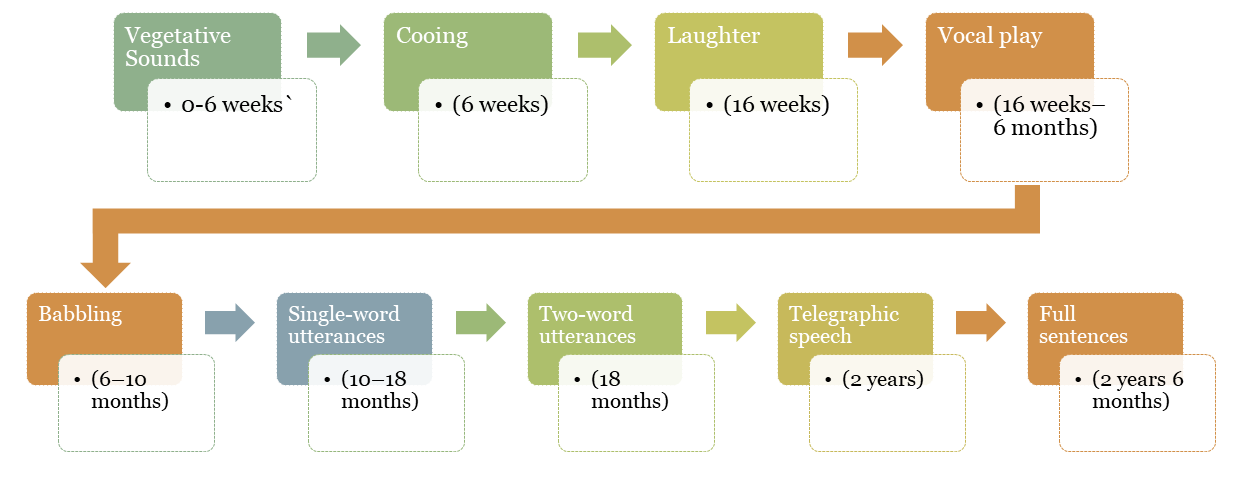
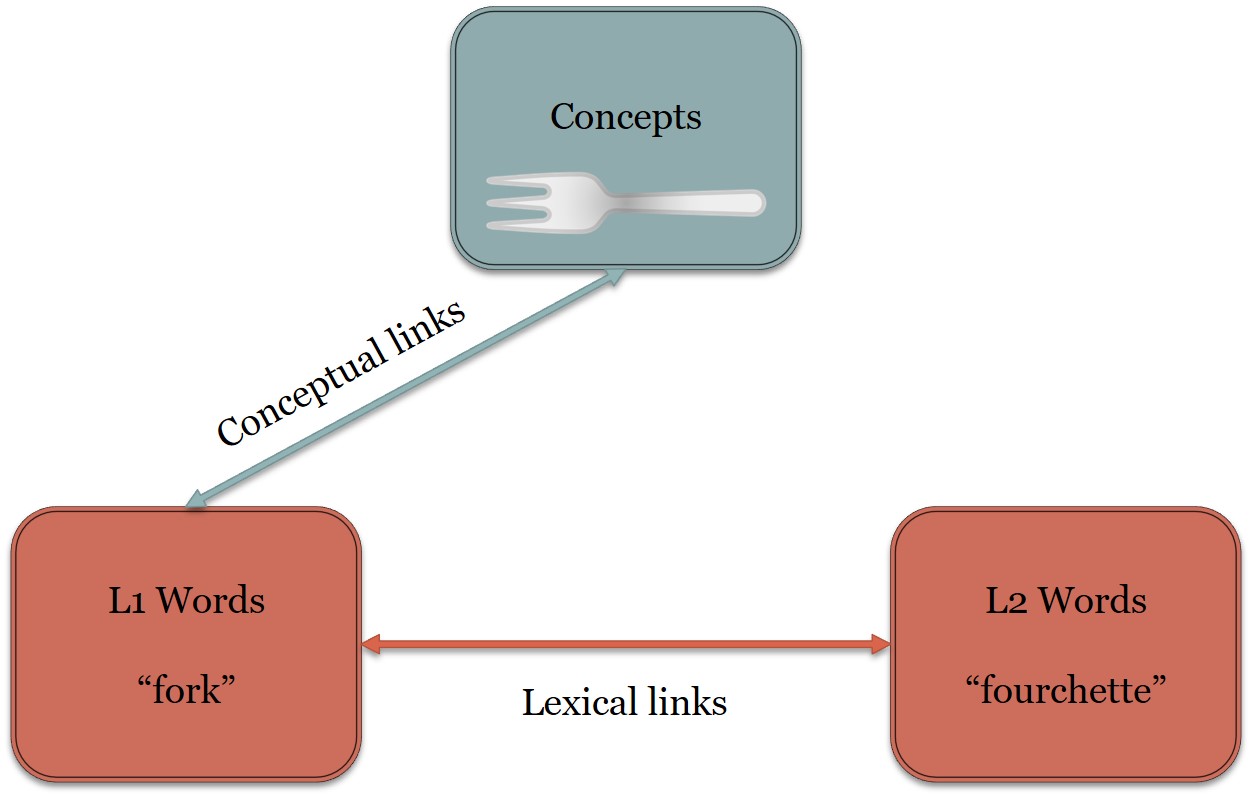
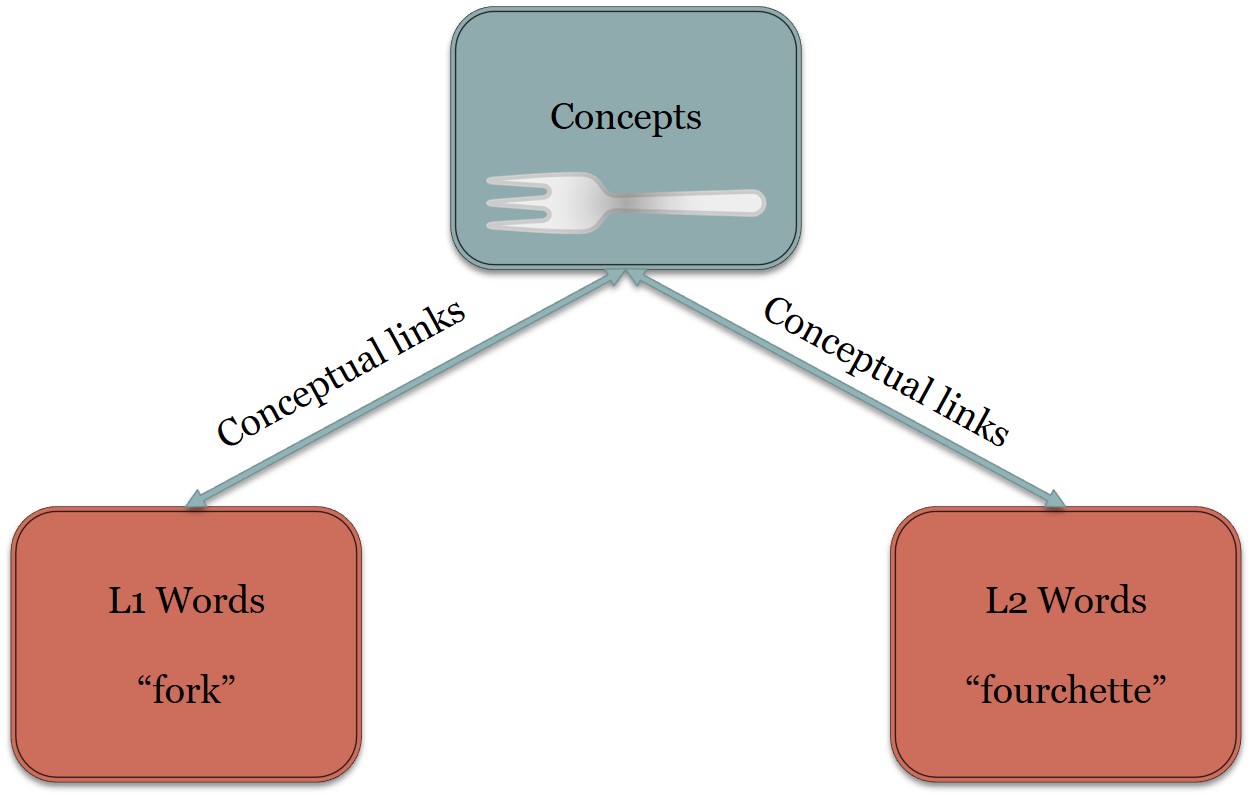
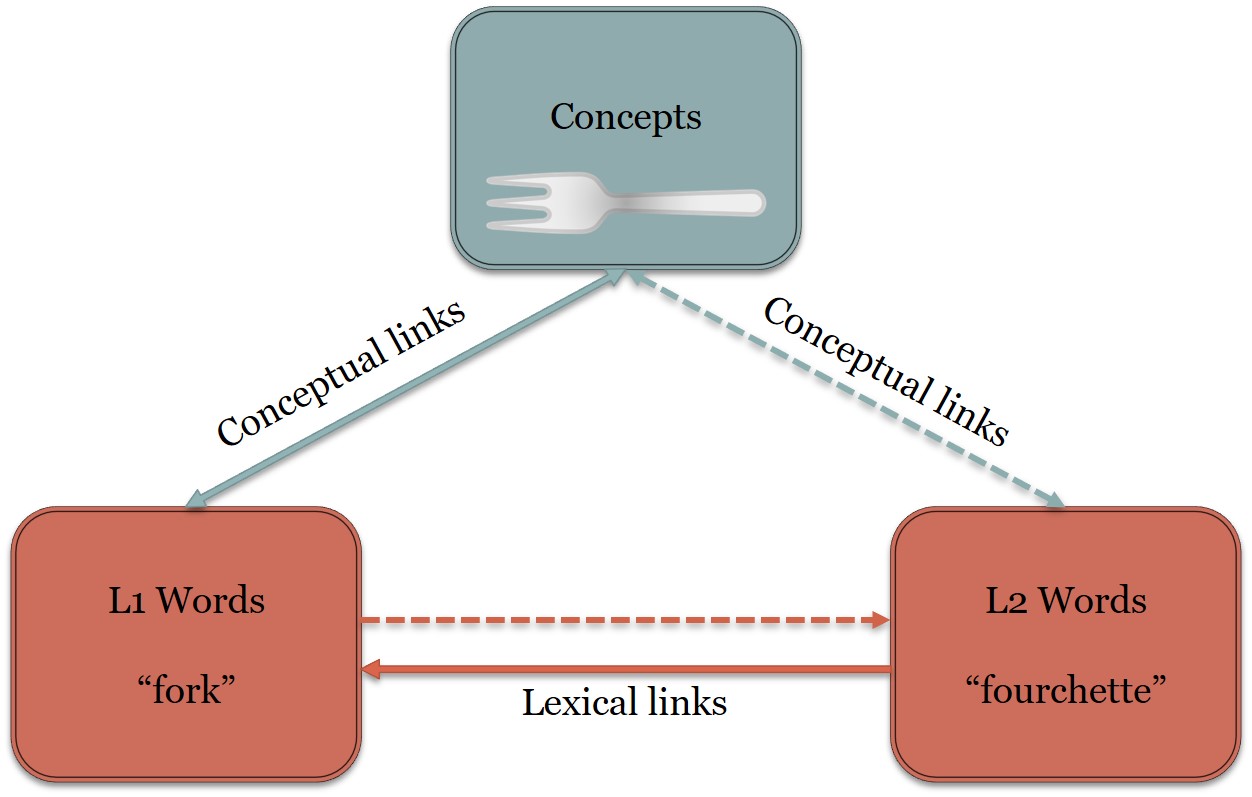
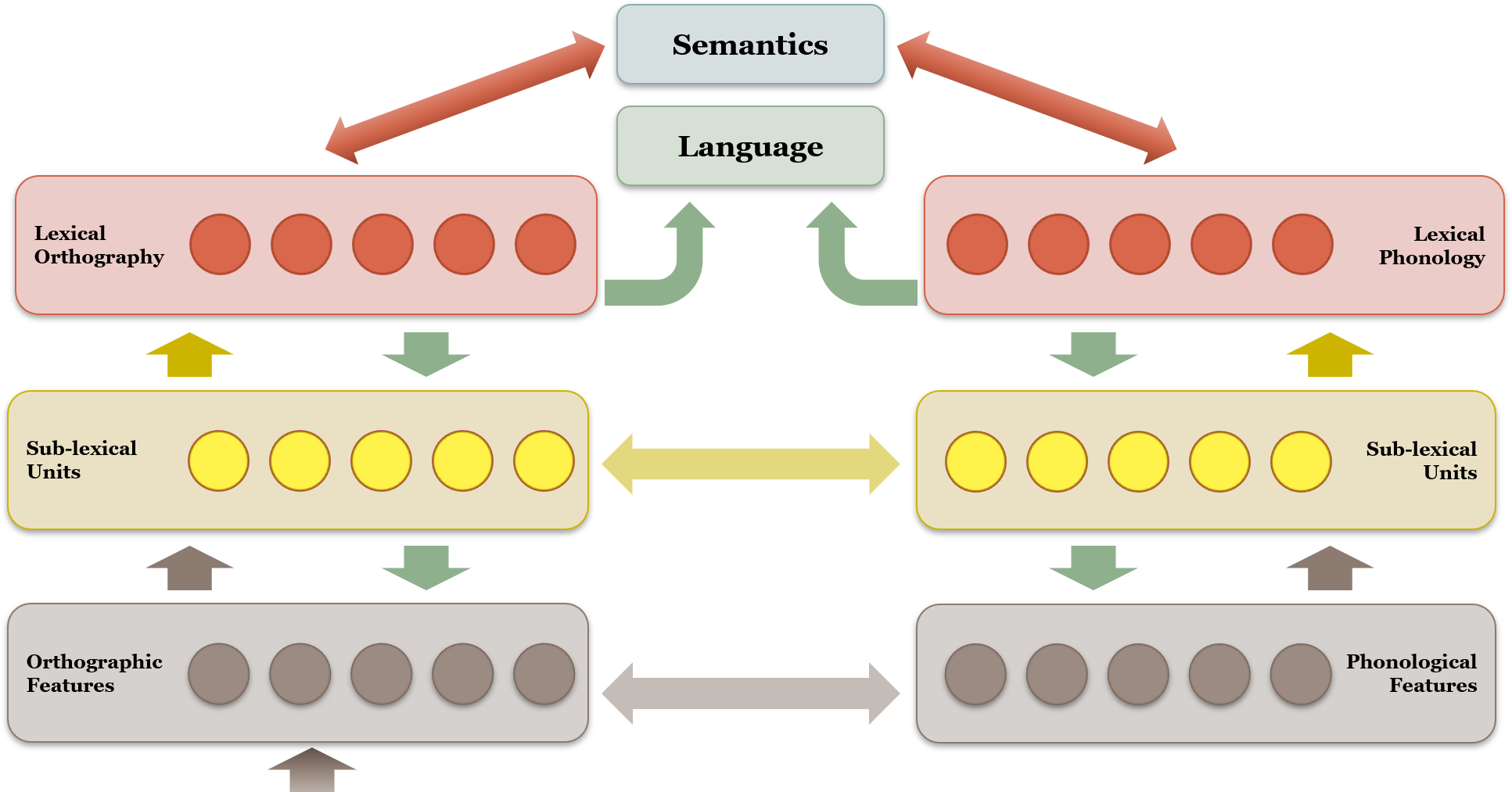
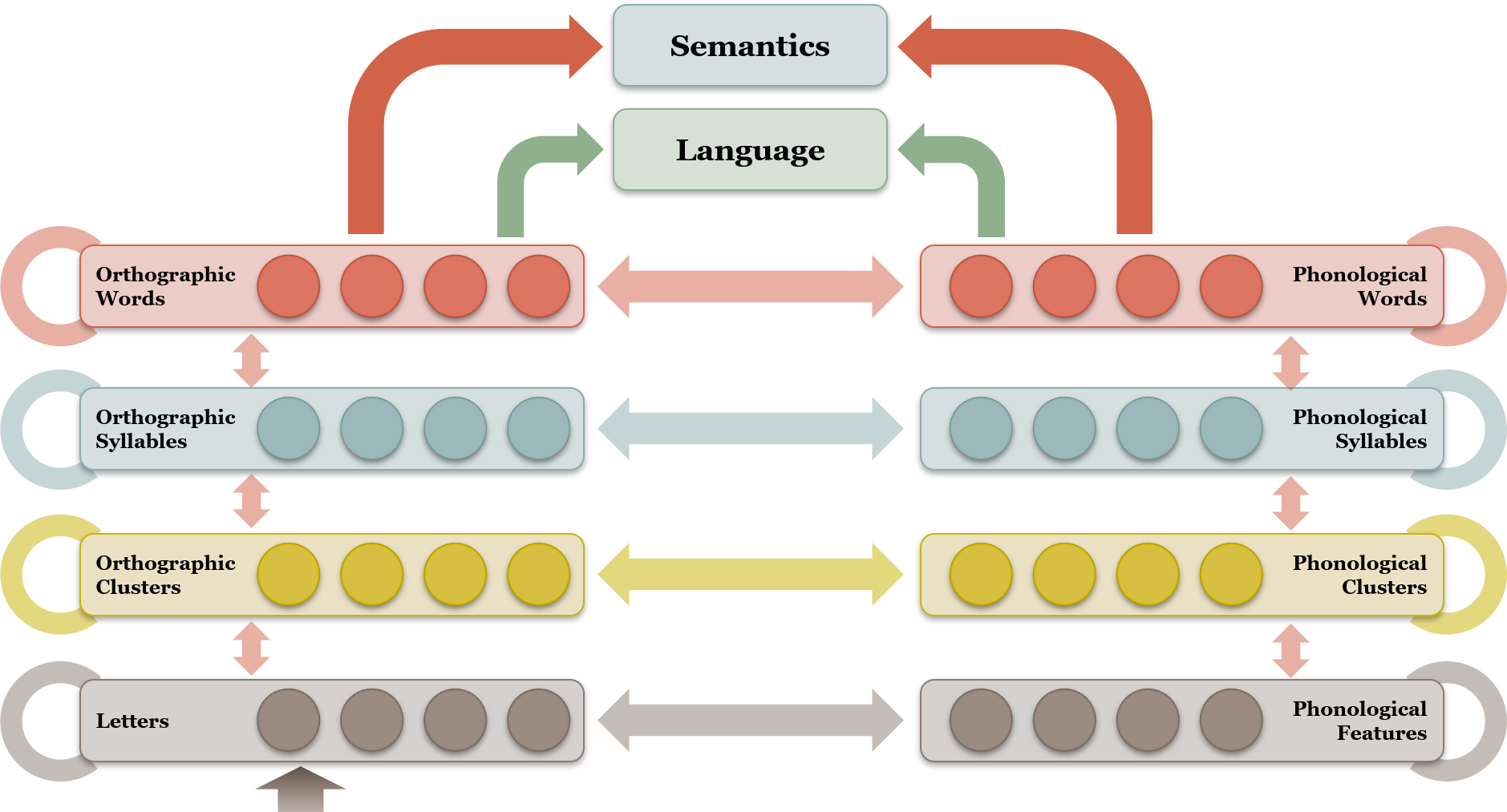


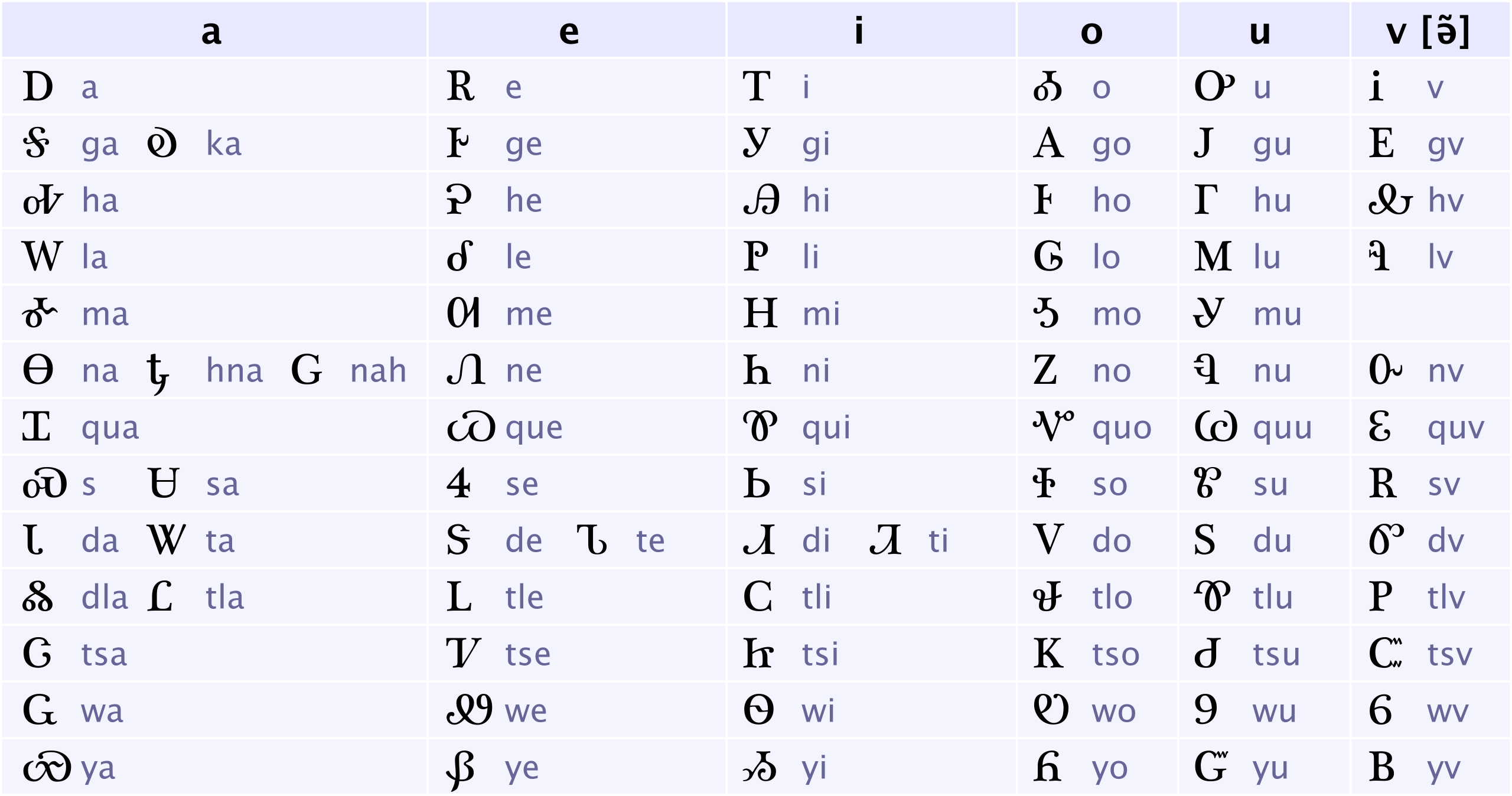
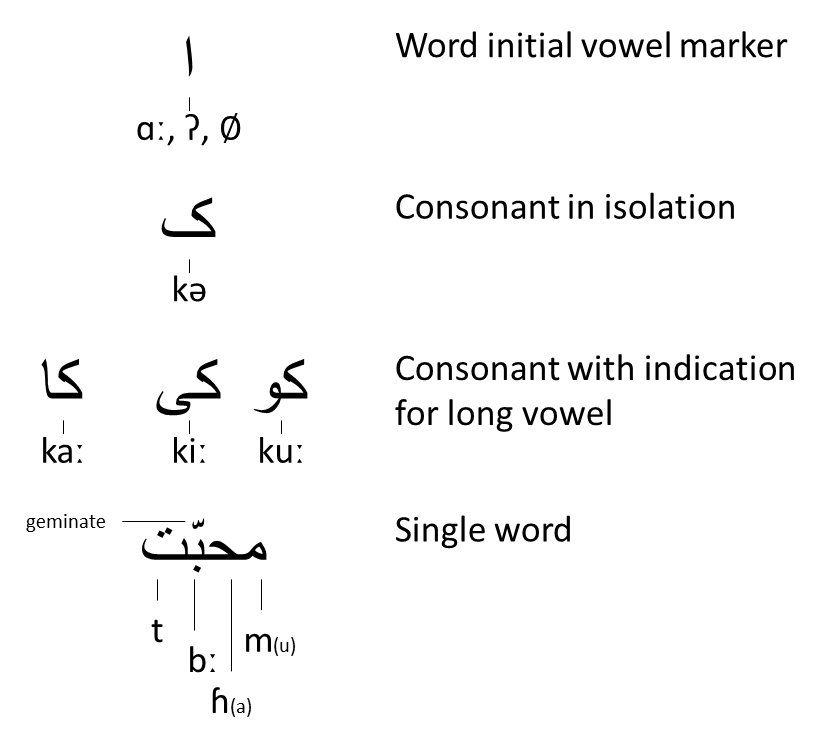


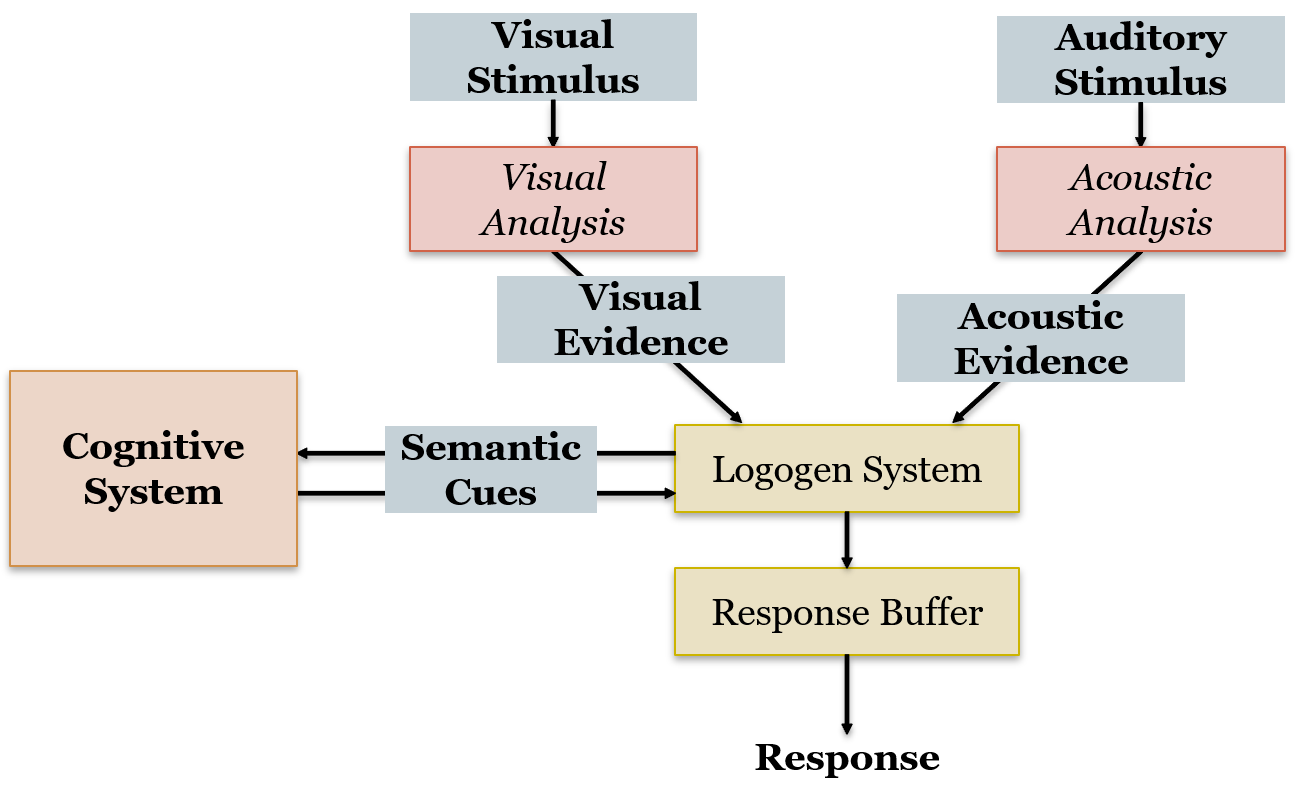
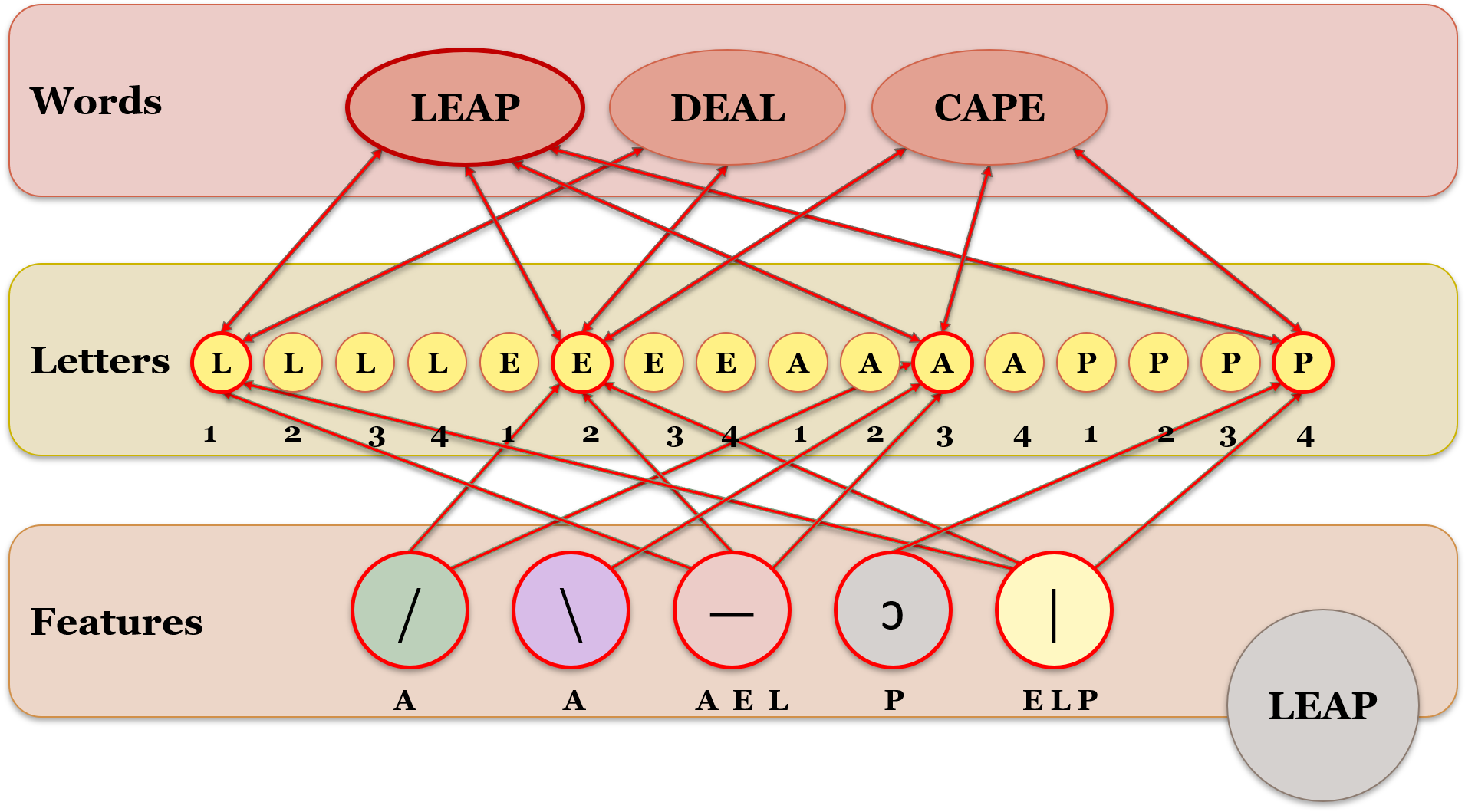
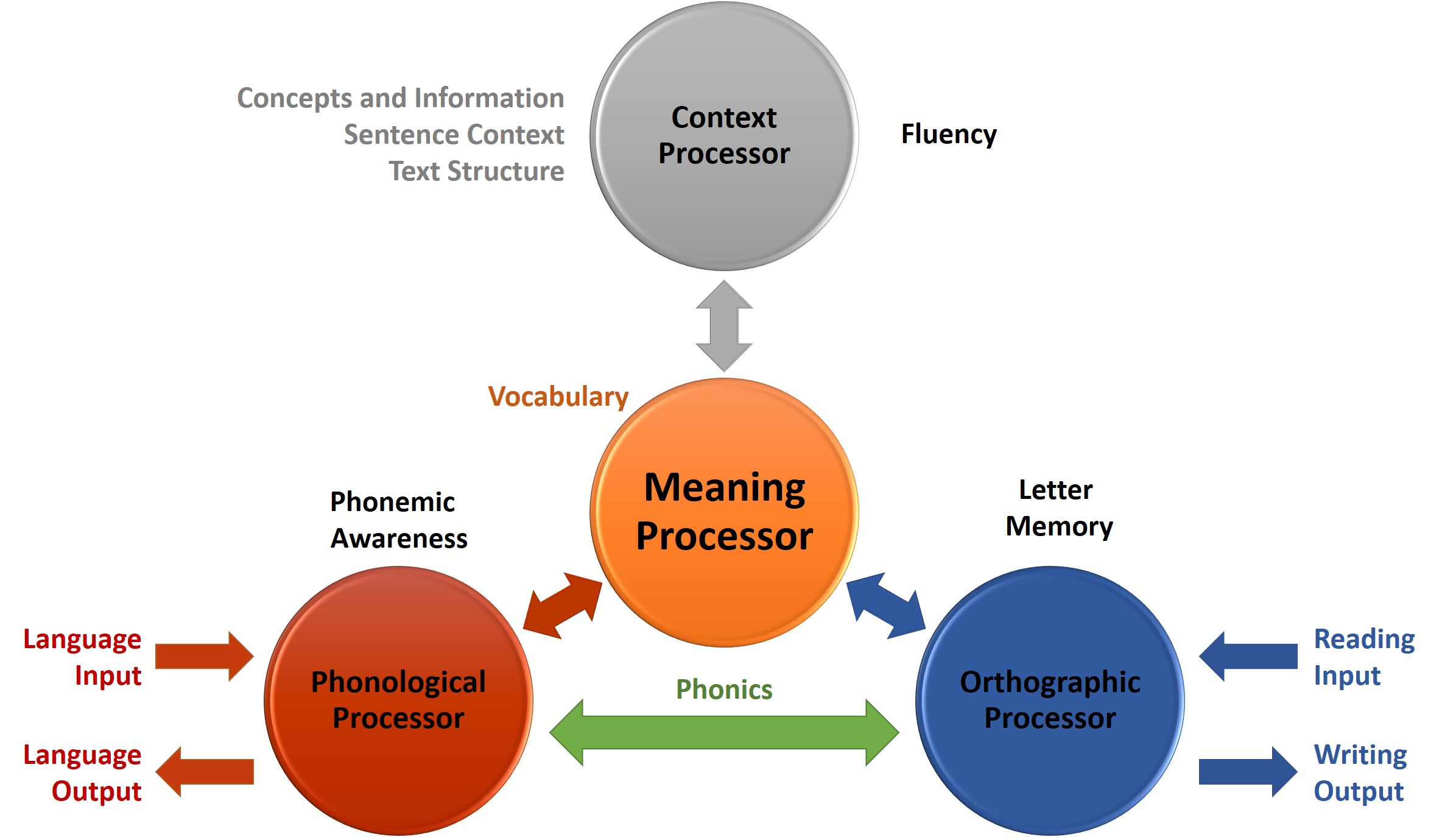
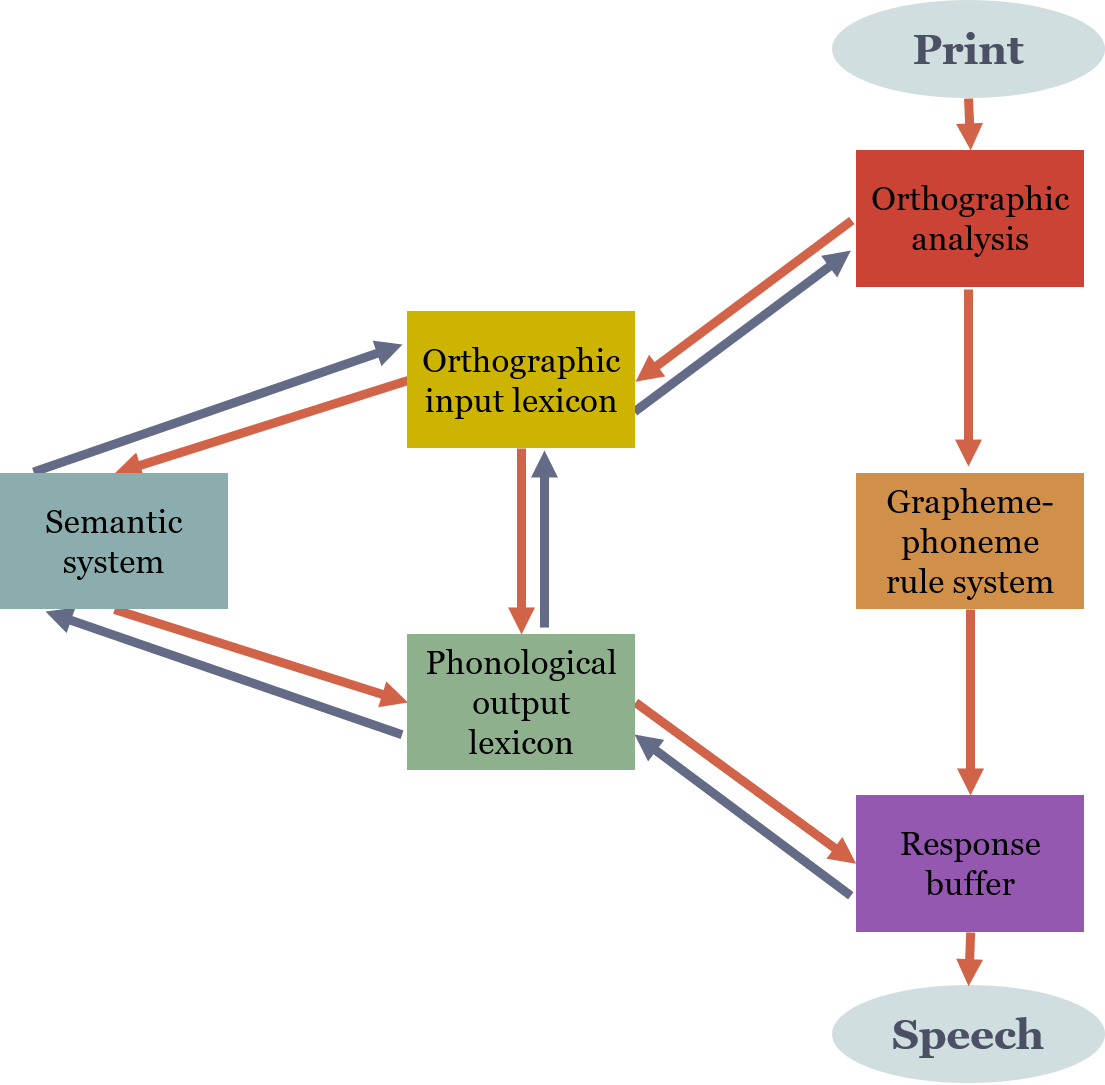

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}